问题背景
好久没写爬虫了,前两天友人来问我python能不能爬论文,能不能告诉她爬虫的基本运行原理是什么,跑起来是什么样子。
我一看,论文爬取——爬虫最实用的场景之一,这不拿捏?

于是便尝试现场演示一番。但是牛皮吹大了,由于手生及记忆有误,代码稀碎运行不出来,一时有些尴尬,趁着今日半天时间重新复习了一遍,查了一些资料,将这个爬虫肝了出来。在此权做记录。
OK不扯皮了,进入正题。
任务分析
需求:
提供一个关键词,先以B站为例,演示一般的爬虫思路,爬取B站热门榜单,随后爬取某论文网站收录的相关论文信息,包括标题,作者,来源,摘要,出版时间,被引用量等等,整理成一个excel表格。
说明:
-
静态网页的爬取一般都比较简单,一个requests加BeautifulSoup就足矣,一般不涉及翻Network。但现在的网页一般都是动态网页,并且是经过加密处理的,需要对网址进行破译,如果不是使用senlenium这种“可见即可爬”的库,那么找到目标信息所在的真实网址就是必不可少的一环了。
-
这里先以B站的热门榜信息爬取为引子,先从较简单的网址解析流程开始,随后进入到某论文网站的论文爬取——带参数操作,这块内容涉及动态网页、网址加密、参数翻找及修改等内容。
-
这两个例子都是需要翻NetWork,仅仅靠解析html是不够的,只会得到
[ ]空值
B站热门榜单爬取步骤
- 思路: 【获取数据】->【解析数据】->【提取数据】->【存储数据】
- 进入B站热门页面,F12打开开发者工具,点开NetWork,Ctrl+R刷新,勾选Fetch/XHR,出现如下页面:
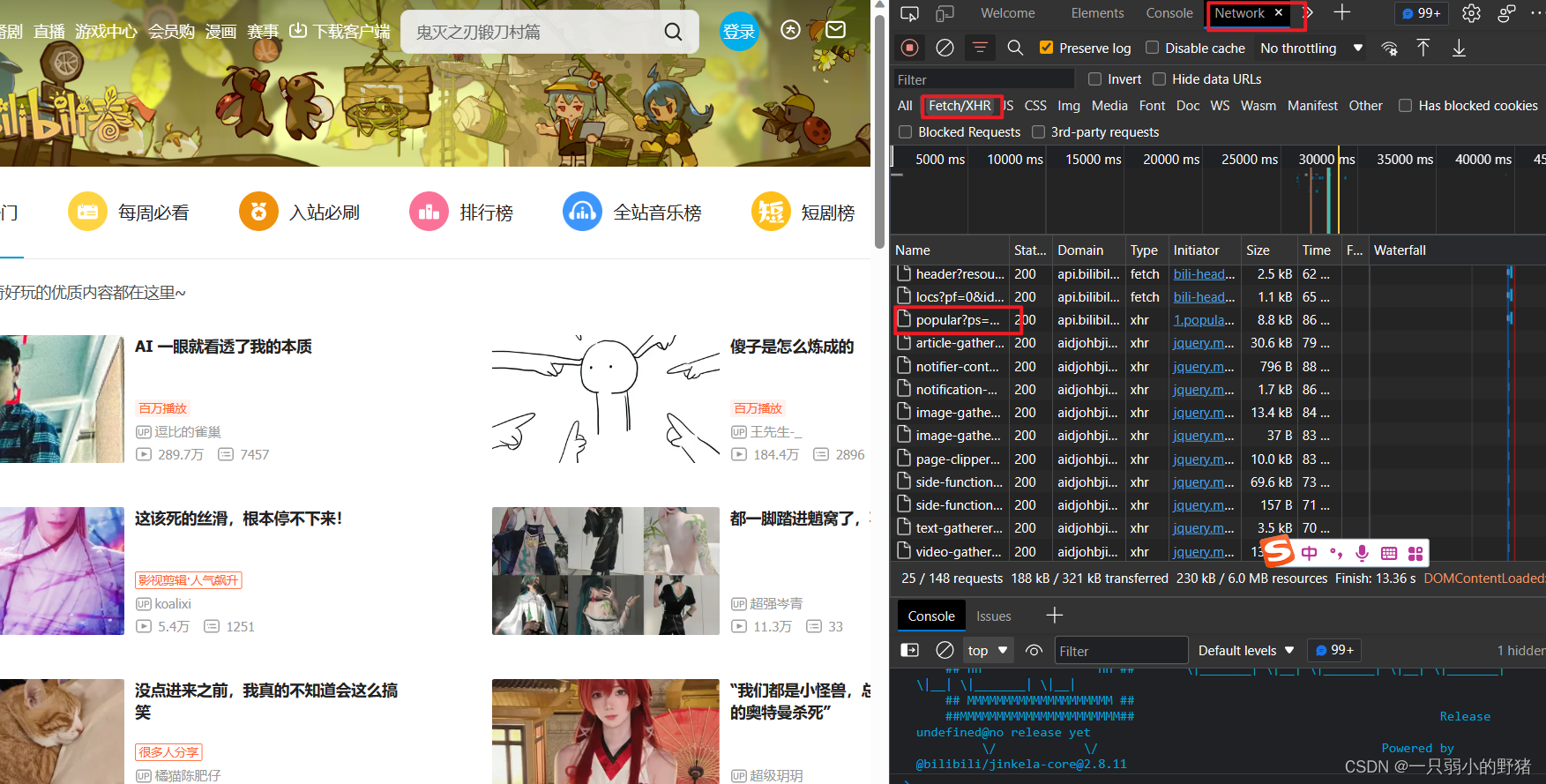
- 然后依次点开Name下面的文件,一个个看,看哪个文件里藏了想要的标题、up主、播放量等信息。最后定位到发现那个
popular?ps=20&pn=1的文件里面藏着我们想要的数据,【获取数据】完成,如下图:
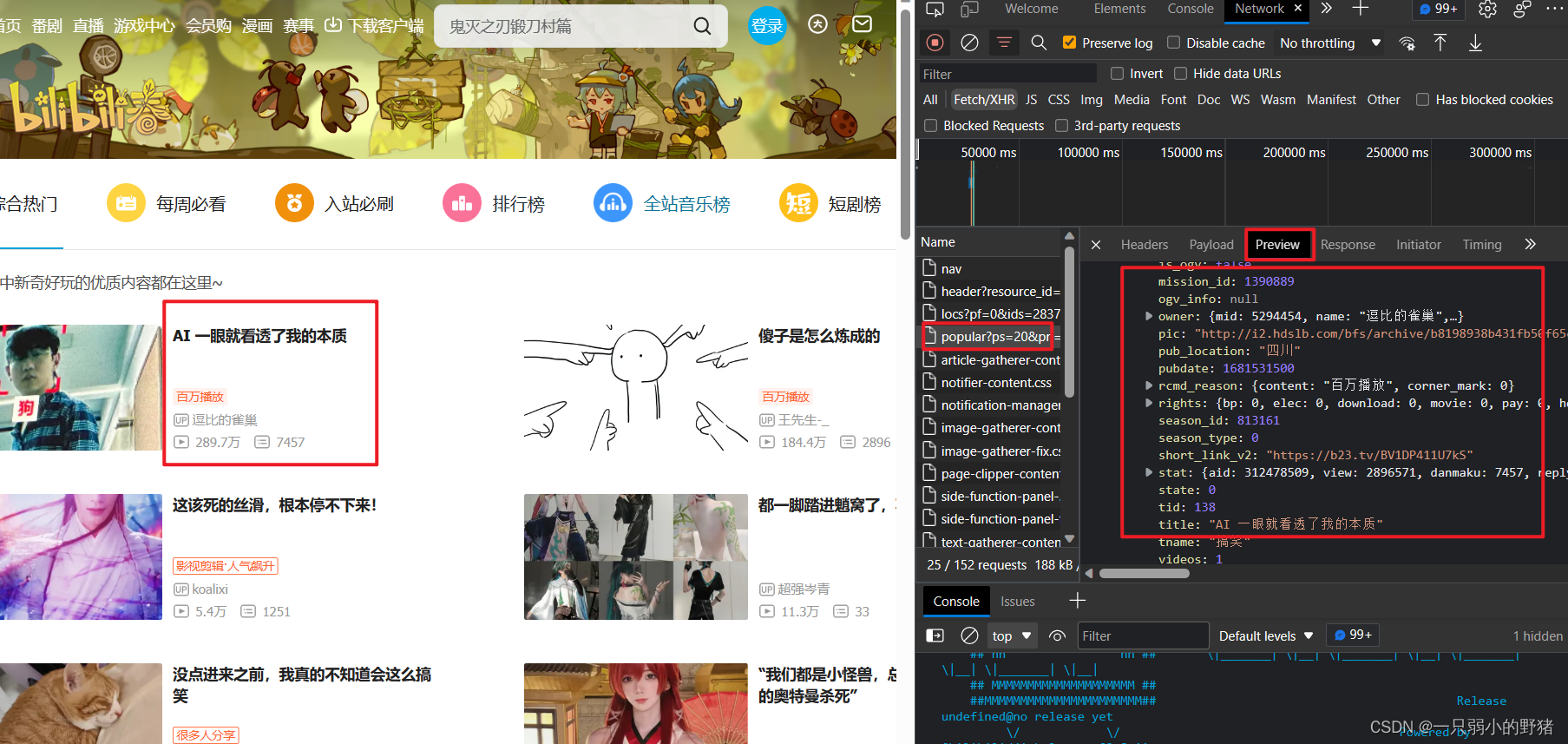
- 目前可以看到这是一个json文件,所以考虑用json库解析,即把它转成字典后再进行字典操作,一层一层像洋葱一样剥开我们想要的信息。
然后我们点开它的Headers,下图的红色区域就是这个json文件的网址了:
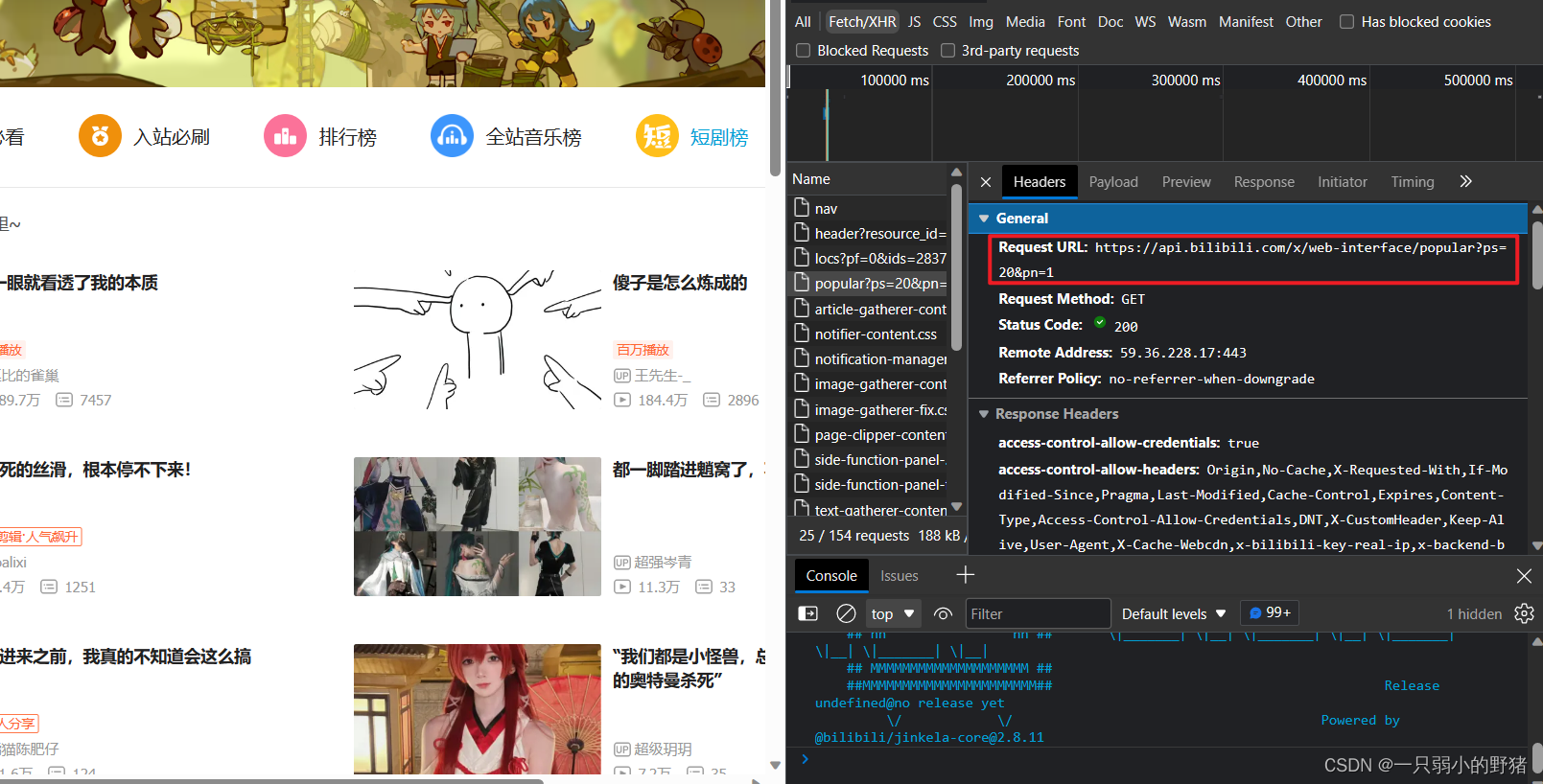
- 最后再把提取的数据整理好,放到excel表格里就完成了【储存数据】。
- 思路映射到代码上:用requests库获取这个网址,再用json库把获取到的内容转成字典,再一层一层提取信息,最后写入excel表格存储
- 实践:【敲代码】
先把完整代码放在下面,随后一行一行分析:
import requests
import pandas as pd
url = 'https://api.bilibili.com/x/web-interface/popular?ps=20&pn=1' # 信息藏匿的网址
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0Win64x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48"} # 加个请求头防止被ban
res = requests.get(url, headers=headers) # 向网址发起请求,获取信息
res_json = res.json() # 用json把网页信息转成字典
target = res_json['data']['list'] # 用字典方法提取信息
titles = [] # 建一个空列表,后续提取title(标题)
owners = [] # 建一个空列表,后续提取owner(up主)
descs = [] # 建一个空列表,后续提取desc(摘要)
views = [] # 建一个空列表,后续提取view(播放量)
for i in target:
# 把每个视频对应的信息分别提取出来,加到各自的列表中
titles.append(i['title'])
owners.append(i['owner']['name'])
descs.append(i['desc'])
views.append(i['stat']['view'])
print([i['title'], i['owner']['name'], i['desc'], i['stat']['view']]) # 打印看看效果
dic = {
"标题": titles, "up主": owners, "简介": descs, "播放量": views} # 建一个字典
df = pd.DataFrame(dic) # 字典转pandas.frame类,好写入excel文件
df.to_excel('./Bilibili_2.xlsx', sheet_name="Sheet1", index=False) # 信息储存到该文件目录下
代码分析:
- 前两行导入要用的库;
import requests
import pandas as pd
- 这一段主要是json部分,因为那个目标信息藏匿的地方的字典结构是这样的↓↓↓
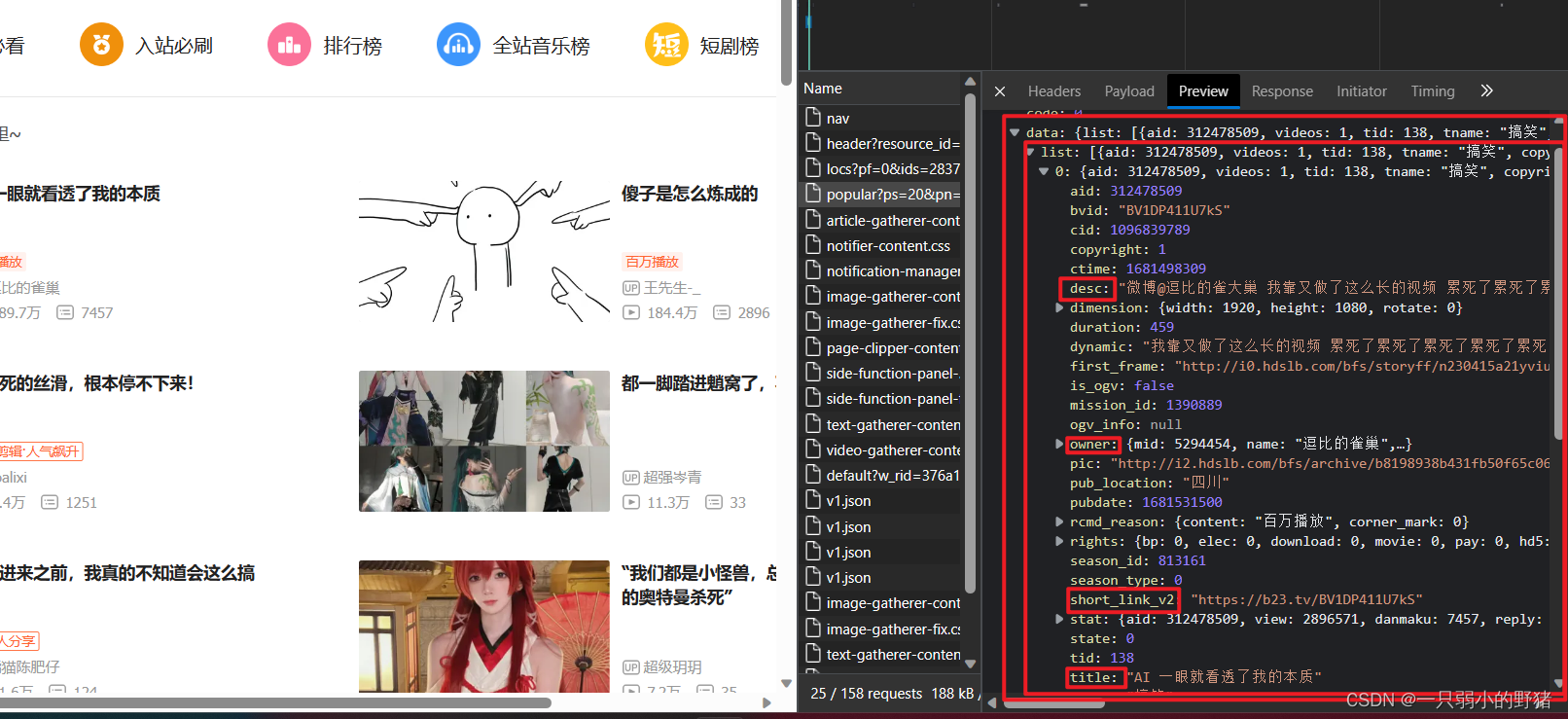
所以按照res_json['data']['list']先提取每个视频的所有信息,再把其中每一个进一步定位提取即可;
url = 'https://api.bilibili.com/x/web-interface/popular?ps=20&pn=1' # 信息藏匿的网址
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0Win64x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48"} # 加个请求头防止被ban
res = requests.get(url, headers=headers) # 向网址发起请求,获取信息
res_json = res.json() # 用json把网页信息转成字典
target = res_json['data']['list'] # 用字典方法提取信息
titles = [] # 建一个空列表,后续提取title(标题)
owners = [] # 建一个空列表,后续提取owner(up主)
descs = [] # 建一个空列表,后续提取desc(摘要)
views = [] # 建一个空列表,后续提取view(播放量)
for i in target:
# 把每个视频对应的信息分别提取出来,加到各自的列表中
titles.append(i['title'])
owners.append(i['owner']['name'])
descs.append(i['desc'])
views.append(i['stat']['view'])
print([i['title'], i['owner']['name'], i['desc'], i['stat']['view']]) # 打印看看效果
- 下面这段就是把提取到所有数据先转成一个字典,再转成一个dataframe,这样就方便用
pandas.to_excel写入了;
dic = {
"标题": titles, "up主": owners, "简介": descs, "播放量": views} # 建一个字典
df = pd.DataFrame(dic) # 字典转pandas.frame类,好写入excel文件
df.to_excel('./Bilibili_2.xlsx', sheet_name="Sheet1", index=False) # 信息储存到该文件目录下
- 最后的结果如下:

某论文网站爬取
这个网站的反爬机制比较厉害,查了挺多大佬的文章,想了挺久,写了一个晚上才搞清楚其中原理。
- 思路: 【获取数据】->【解析数据】->【提取数据】->【存储数据】
- 按同样方法进入网站,搜索完关键词(这里我以碳中和为例)后,F12打开开发者工具,点开NetWork,Ctrl+R刷新,勾选Fetch/XHR,出现如下页面:
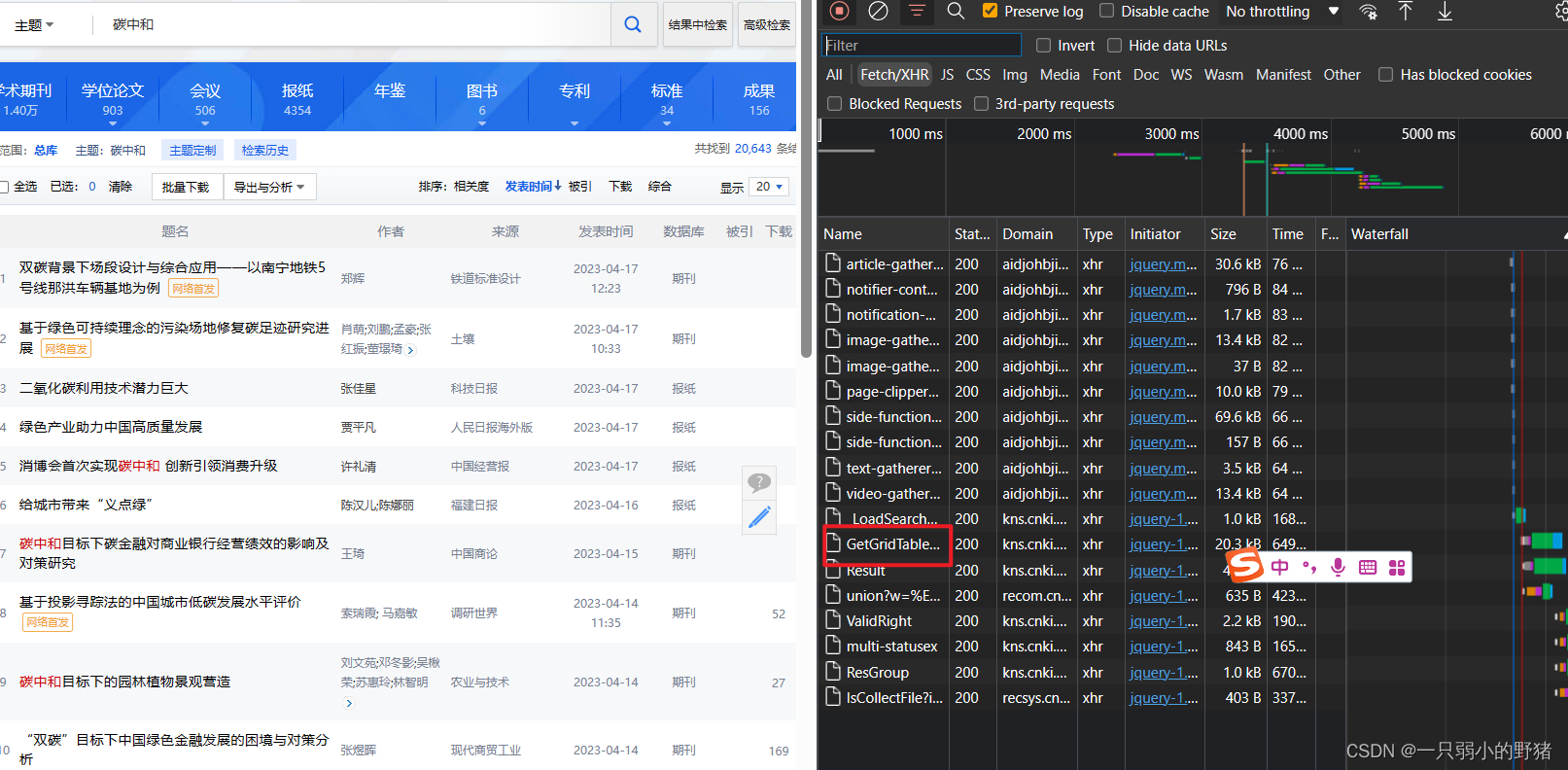
- 一个一个点开看后,发现信息藏在
GetGridTableHtml文件中,我们点开一看,发现这是一个html语言生成的网页文件,那就先不用json解析了,说不定普通的Beautifulsoup就够用了,以防万一,这次我们做好“伪装”,把请求头和cookies都带上来访问它。
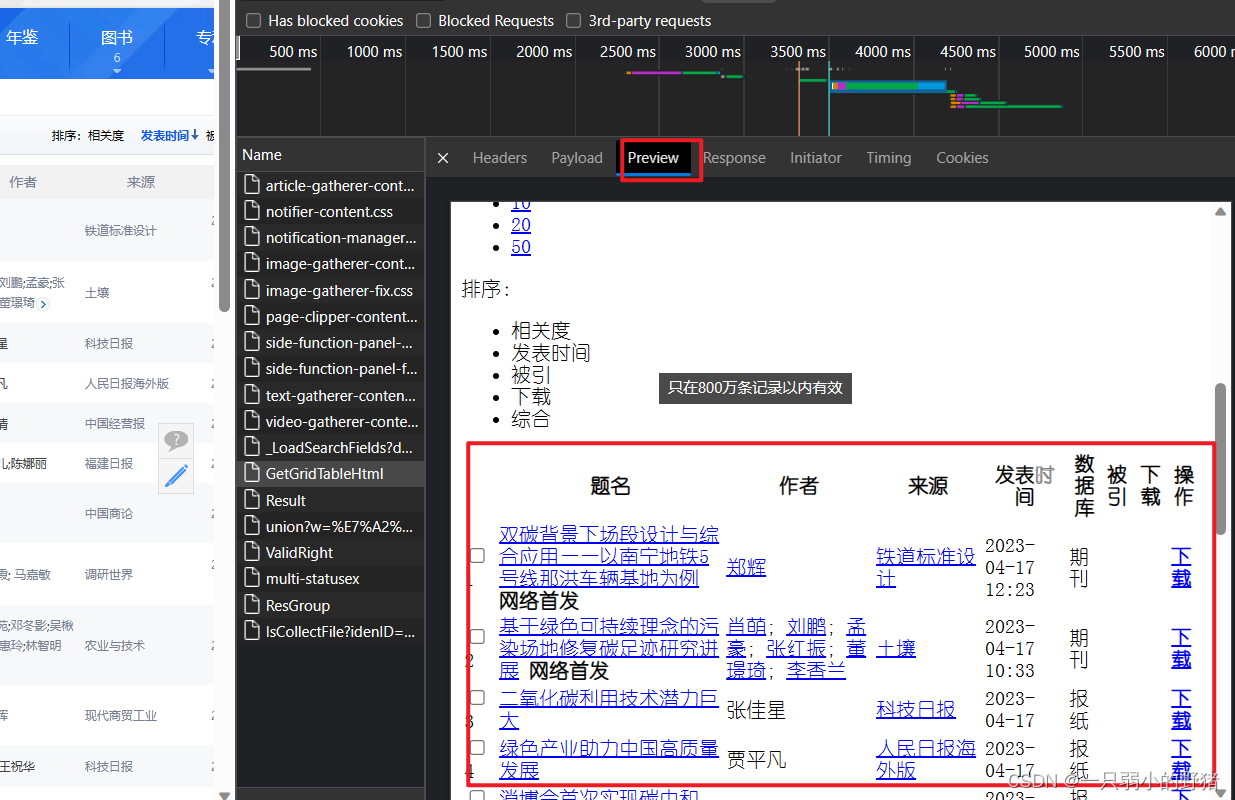
(在响应的Response下面我们也可以看到这个网页文件的源html代码)
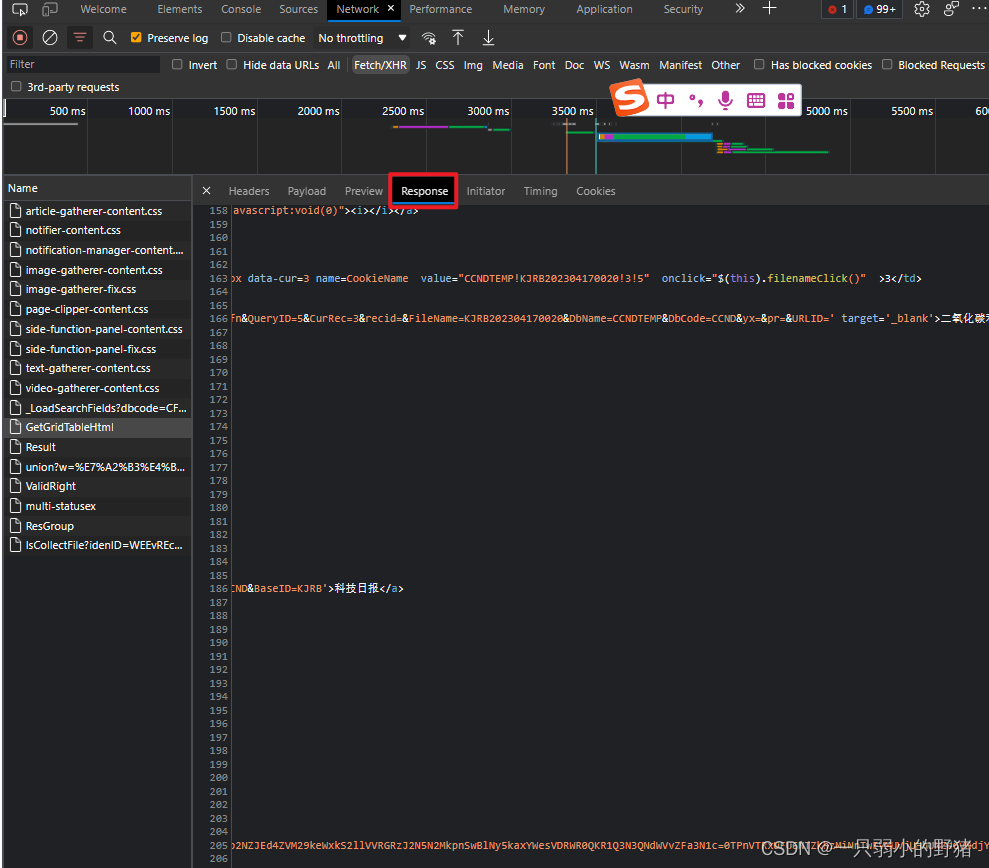
话不多说,开始操作!
- 实践:【敲代码】
先把完整代码放在下面,随后一行一行分析:
import requests
from bs4 import BeautifulSoup
url = 'https://kns.cnki.net/KNS8/Brief/GetGridTableHtml'
head = '''
Accept: text/html, */*; q=0.01
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Connection: keep-alive
Content-Length: 5134
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Cookie: Ecp_ClientId=b230309162401492276; Ecp_loginuserbk=gz0332; knsLeftGroupSelectItem=1%3B2%3B; Ecp_ClientIp=219.223.233.83; cnkiUserKey=3c1cc8af-46ae-8fb2-d5f7-1014b5e3d034; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22186c579a2ef11ea-0e8fd66c04c69e8-74525476-1327104-186c579a2f01680%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%7D%2C%22%24device_id%22%3A%22186c579a2ef11ea-0e8fd66c04c69e8-74525476-1327104-186c579a2f01680%22%7D; Hm_lvt_6e967eb120601ea41b9d312166416aa6=1678350324,1680238706; Ecp_session=1; SID_kns_new=kns15128006; ASP.NET_SessionId=4dobe0vxy4f4m2fnmchugzbg; SID_kns8=25124104; CurrSortFieldType=desc; LID=WEEvREcwSlJHSldSdmVqMDh6c3VFeXBleUNRb1BiK00rb0k3YXk5YllBQT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!; Ecp_LoginStuts={"IsAutoLogin":false,"UserName":"gz0332","ShowName":"%E6%B7%B1%E5%9C%B3%E5%A4%A7%E5%AD%A6%E5%9F%8E%E5%9B%BE%E4%B9%A6%E9%A6%86","UserType":"bk","BUserName":"","BShowName":"","BUserType":"","r":"77fOa5","Members":[]}; dsorder=pubdate; CurrSortField=%e5%8f%91%e8%a1%a8%e6%97%b6%e9%97%b4%2f(%e5%8f%91%e8%a1%a8%e6%97%b6%e9%97%b4%2c%27time%27); _pk_ref=%5B%22%22%2C%22%22%2C1681733499%2C%22https%3A%2F%2Fcn.bing.com%2F%22%5D; _pk_ses=*; _pk_id=b73a87af-2c79-4c0e-866e-1b6b2c1787d5.1678350286.7.1681733507.1681733499.; c_m_LinID=LinID=WEEvREcwSlJHSldSdmVqMDh6c3VFeXBleUNRb1BiK00rb0k3YXk5YllBQT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!&ot=04%2F17%2F2023%2020%3A16%3A32; c_m_expire=2023-04-17%2020%3A16%3A32; dblang=ch
Host: kns.cnki.net
Origin: https://kns.cnki.net
Referer: https://kns.cnki.net/kns8/defaultresult/index
sec-ch-ua: "Chromium";v="112", "Microsoft Edge";v="112", "Not:A-Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48
X-Requested-With: XMLHttpRequest
'''
headers = dict([[y.strip() for y in x.strip().split(':', 1)] for x in head.strip().split('\n') if x.strip()])
# head的issearch参数我直接设置为false,具体分析看注释
head = '''
IsSearch: false
QueryJson: {"Platform":"","DBCode":"CFLS","KuaKuCode":"CJFQ,CDMD,CIPD,CCND,CISD,SNAD,BDZK,CCJD,CCVD,CJFN","QNode":{"QGroup":[{"Key":"Subject","Title":"","Logic":1,"Items":[{"Title":"主题","Name":"SU","Value":"碳中和","Operate":"%=","BlurType":""}],"ChildItems":[]}]},"CodeLang":"ch"}
SearchSql: $s
PageName: defaultresult
DBCode: CFLS
KuaKuCodes: CJFQ,CDMD,CIPD,CCND,CISD,SNAD,BDZK,CCJD,CCVD,CJFN
CurPage: $page
RecordsCntPerPage: 20
CurDisplayMode: listmode
CurrSortField: PT
CurrSortFieldType: desc
IsSentenceSearch: false
Subject:
'''
s = '0645419CC2F0B23BC604FFC82ADF67C6E920108EDAD48468E8156BA693E89F481391D6F5096D7FFF3585B29E8209A884EFDF8EF1B43B4C7232E120D4832CCC8979F171B4C268EE675FFB969E7C6AF23B4B63CE6436EE93F3973DCB2E4950C92CBCE188BEB6A4E9E17C3978AE8787ED6BB56445D70910E6E32D9A03F3928F9AD8AADE2A90A8F00E2B29BD6E5A0BE025E88D8E778EC97D42EF1CF47C35B8A9D5473493D11B406E77A4FF28F5B34B8028FE85F57606D7A3FED75B27901EEF587583EBD4B63AC0E07735BE77F216B50090DEE5ABB766456B996D37EB8BDACA3A67E8126F111CF9D15B351A094210DB6B4638A21065F03B6F0B73BB4625BBECE66F8197909739D8FB4EB756DEF71864177DFA3CB468CFA6E8ABF7924234DED6B0DFD49D9269CBA4A2BF4075D517A61D094225D70C1B4C137DB9614758A5E097376F5F3E55A7063A4B7E437436D13FF3CC8FB435E131FFCD16FC30DD997098B4FC997D995E767E2712175BC05B960D3FEB5CAF12A13BD1CE3530AD72FC4DB93206996E216BC5DC294960A0CA05E986848E1E64FFC5A52BFCB41A97840A708E397F11EFF261E08F3A34094061AE8E8F819AF6A17A9E2176C3893C6DD3E3C06864C91989BDEF9790A38FAF2524B17743B30EBA4ADD550BF985F9C3097A608C697283CE37F8CB78BDC9EAA4874C3485E6F931B016EC41BFBC0EF91B2AD7E1B424E1DFB8FC8771DEA2458C5A7A4C9BF0192C101FD8EDDEE1BACB44C3E478361EF0D1B70FAD56BCF6870A6044D3A226611B9C1A43C6F9F7C021C98E0D5F778D72C87183F026071A730B8BB4FABF9F68FEC783AB1E6E79218B5D87FD1BB541817FB4F3C21DC849A803CB8A620A2EE00475BAF2CE6556638B7A949B446F39A1076DA15764A777BA6239447CB91F4CF513325366E167D268DDB75F288B5C13415CE62F5C431181C044A28CA502FF14439E5C6F63D419CB6DE1360DB01593FE765459299E442EE24917C199AB5178F38461F8C4EBBC95344C5F2AB60F379813A87E2E3AFE3021198B8222CEAB870D9A353786079961184D63977917C7DF8FE6AFBBC795A832BDD454D6E3CD22C3FF7A58808923DD6F464C12A9A88FBFD0C71458AB0E4C1D566315181A9578ECE93670E5CAF13CF2553F68E64726C131F4A48B42A9E7F09EFEBA51D1FDA6BA0ECA0B02B951ECC04548F1D4D08DB69D0EFDCE6793537BB8E59DC442631A9CDBA13878D7493AADA0CD868C1C1C3A6A6FA17C4109205A83F9C0C43E0D2551D0A8592EA99D20D4B78B4EEEE2D53A543701F620C7D6FF46E800B0CEF9B3D23ACD62C7CBEA25FC8BD74D5A0E5C86B9CF3FCACBDBE585AFF85F9689CBF5BCBD267C580361D5B93AA9BD5A1BB6122BB87C04AE227211FE675A4650814F2285261E5641683D65E0454E2597F6025BB4AA1A044D7B97F57394EA5EC878B80FC0A82F12E2D3D9E1BCB062A7ABB290F02116BDED95761A67CE2FDDE42BDDDF34F22E49A0406D724FEBC86B93F80BB52A8D34B8D2B24288ECBC3F90CCB1EF36085E77F1E2AE0AB411FE60A033E704A21469EA5CE4BB8AF6B1C1F1C5F1F084472D57F458CC39F0B2FE583D0795159E9E38BD1102F5D96DB0F828B66F41A702BB0AE59E40CF53BE7F6342EF208434CFFABF845AFD771B288D484BB79952159E6EA27658A6B6230557AF16E86C4AFDF973DBD5A3A2B979AD9037441409D22A954DC50CBCEA8EA5AC500C4BC8282DCE2626BD2B2CB4B1E33B2E1F92533F7F04C48D061907DBCE3E21FF0A77F09C1AE33E769962CD1EDE6B688590D569409EE9EEC4DF1074DCC97C43B0EDAF1C38B5B2784ABC803D9B3B4FC35F46CB1E275E7F83036FC6AFF2E624D4D2E6AE1C2D4CE3FF219FA90A935957E0DE1A386E4AAB5C9F9D1CECA909F5698BFA86C57B6A73D3C0F9FDB94128B7BB9FDD19D57E4C2C2F4127A1F127A96ABF248B26D8B6EF12A1EA97D064564D33D46E5CA71F53FA121A7E5C91ED2B08BE64A0E3D22BE26FC251C0BF4CF21674DE19AF410E3EDFBD9A4BBEA6C709A1E42B5C17E1EE7AA33EFB0F375BF0858D49210A71662313FA5B8E04E508A5E9425D49C3C5D12CB8DCADBF8A148BFA042BBB0218AAC403AAB9CECC45FD33CEC6797FC984BF91FF638AF6E1F09546F595CFC779D2D867282C63B78DC6A6ED3C1C3887462C84AC07C756C5A8D8A8B2EFD39C28A68D47091A3312461BC20085636F4B41F22D5B46861F3E557777CDCFDFE6CAB8ABECFECA3634D779C0F21185772C426BE383BD26E1715DAB5EC4AE4CAC877ED6899CBCB31546F9C6144399C7C0257BBCCBE0EBD2E90EA901840211FCBB1655CB66FD9C51E90432B273CC4CFF3F8DBEB24CDB0ED6017FE68A7F3E9156E1BA276526DE9599A66921F0E2C3ED466FDE0076DCDA6745F29D28E406BEE5FFB0D4C5FB5D72029BAE56BC22496567FF64341F89469703987DD9D700C08346782F57BA62479812820C862D3D5C604C5C26A76F1A7EC503EB4892BAEB25BB44E783FFB3F1B2F5BECB16A5B48F4D769C3DD5713D2B00AEF4870248A1D561623C9418C285CEE86E1C8DF4A73ED729D7789577456281B4F4D1EE3447E6F8391341BB8F15CF9712E73DBE149164B95748F35D6A4CB4492B8D082AB372E96FC29D1578B41D85F0B7A04EFCBE928642D5D2825F978805C43062C3DF3F0915B33F58A8D82BCC523F3C36B9BAEB9226A39549408AFD3119A8B39B8887038107EB5A623D59186BFFF562E624E1BC25A0C8AA6DD298AEC09B06802A77DFD11799D29506307693DAB2962B98EF9F25E785619D05BDE7073474E187D59D41F6A2E06CC292AD406C2991D9C5E58812A1431B46AB634D548433B1E437D745A013EF5950818CC2A2860B4A7D93BE2DDF0AAAE0627B587A6FAD3FBFFCE90BEFB8ED5F71EAA17F6A0841841EC096D2F47AEA2203CD44B0D68A7B02FE7BEA80BA3CC925155610F00B7D631D150EBA6FFE62E756004A946F9E0F8728DC9E87768D1AC6560DA6A15382DFFA62B129957D4B23F4921C46631D24125DD5CACA73481F2CBDE5'
# 这里解释一下这个网站的小伎俩,当page为1时,isresearch值为true,这时不会显示Searchsql,
# 但是一旦你多翻两页,就会发现page>1时,isresearch值为false,这时就会显示Searchsql,这里我直接尝试设置page为1时issearch为false,发现并不影响,所以只改page即可
# s是查询sql在IsrSearch为false的html里面可以找到 GetgridTableHtml和ValidRight都可以找到sql
page = 0
head = head.replace('$s', s)
head = head.replace('$page', str(page))
data = dict([[y.strip() for y in x.strip().split(':', 1)] for x in head.strip().split('\n') if x.strip()]) #转成特定格式,可以打印出来看
def cal(url, headers, data, Curpage, database):
data['CurPage'] = Curpage
res = requests.post(url, timeout=30, data=data,
headers=headers).content.decode('utf-8')
bs = BeautifulSoup(res, 'html.parser')
target = bs.find('table', class_="result-table-list")
names = target.find_all(class_='name')
authors = target.find_all(class_="author")
sources = target.find_all(class_="source")
dates = target.find_all(class_="date")
datas = target.find_all(class_="data")
for k in range(len(names)):
name = names[k].find('a').text.strip()
author = authors[k].text.strip()
source = sources[k].text.strip()
date = dates[k].text.strip()
data = datas[k].text.strip()
href = "https://kns.cnki.net/" + names[k].find('a')['href'] # 提取文章链接
database.append([name, author, source, date, data, href])
database = []
for m in range(1, 3, 1):
cal(url, headers, data, str(m), database)
import pandas as pd
df = pd.DataFrame(database, columns=["Title", "Author", "Source", "Publish_date", "Database", "Link"])
df.to_excel('./paper.xlsx', sheet_name="Sheet1", index=False)
代码分析:
-
前两行导入相关库,这里经过尝试,发现
requests库和BeautifulSoup两个最常用的就足够解析网页了,当然也可以用lxmt.html来解析网页。 -
然后把找到的目标网址赋好值为url(和前面一样,在Headers里找)。
import requests
from bs4 import BeautifulSoup
url = 'https://kns.cnki.net/KNS8/Brief/GetGridTableHtml'
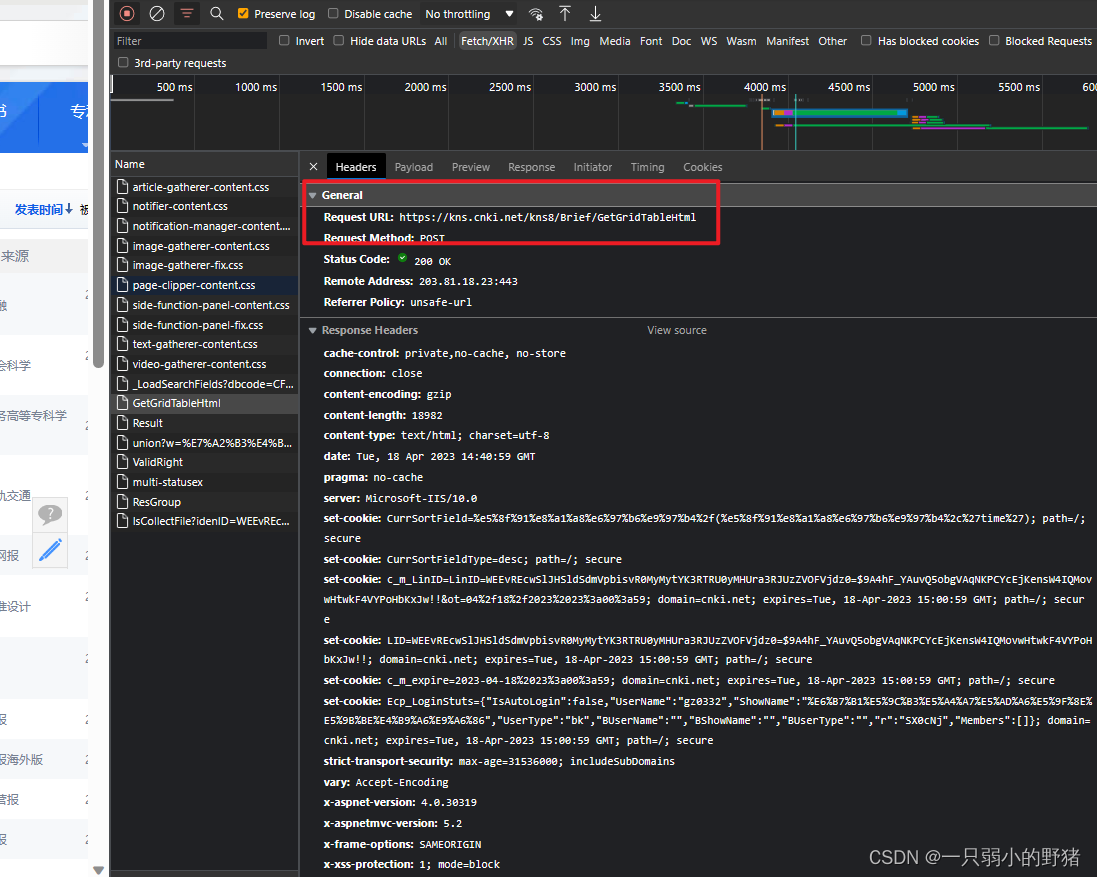
- 这一段很容易,就是把Headers里的请求头copy过来赋给新的变量,然后转成字典。
head = '''
Accept: text/html, */*; q=0.01
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Connection: keep-alive
Content-Length: 5134
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Cookie: Ecp_ClientId=b230309162401492276; Ecp_loginuserbk=gz0332; knsLeftGroupSelectItem=1%3B2%3B; Ecp_ClientIp=219.223.233.83; cnkiUserKey=3c1cc8af-46ae-8fb2-d5f7-1014b5e3d034; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22186c579a2ef11ea-0e8fd66c04c69e8-74525476-1327104-186c579a2f01680%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%7D%2C%22%24device_id%22%3A%22186c579a2ef11ea-0e8fd66c04c69e8-74525476-1327104-186c579a2f01680%22%7D; Hm_lvt_6e967eb120601ea41b9d312166416aa6=1678350324,1680238706; Ecp_session=1; SID_kns_new=kns15128006; ASP.NET_SessionId=4dobe0vxy4f4m2fnmchugzbg; SID_kns8=25124104; CurrSortFieldType=desc; LID=WEEvREcwSlJHSldSdmVqMDh6c3VFeXBleUNRb1BiK00rb0k3YXk5YllBQT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!; Ecp_LoginStuts={"IsAutoLogin":false,"UserName":"gz0332","ShowName":"%E6%B7%B1%E5%9C%B3%E5%A4%A7%E5%AD%A6%E5%9F%8E%E5%9B%BE%E4%B9%A6%E9%A6%86","UserType":"bk","BUserName":"","BShowName":"","BUserType":"","r":"77fOa5","Members":[]}; dsorder=pubdate; CurrSortField=%e5%8f%91%e8%a1%a8%e6%97%b6%e9%97%b4%2f(%e5%8f%91%e8%a1%a8%e6%97%b6%e9%97%b4%2c%27time%27); _pk_ref=%5B%22%22%2C%22%22%2C1681733499%2C%22https%3A%2F%2Fcn.bing.com%2F%22%5D; _pk_ses=*; _pk_id=b73a87af-2c79-4c0e-866e-1b6b2c1787d5.1678350286.7.1681733507.1681733499.; c_m_LinID=LinID=WEEvREcwSlJHSldSdmVqMDh6c3VFeXBleUNRb1BiK00rb0k3YXk5YllBQT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!&ot=04%2F17%2F2023%2020%3A16%3A32; c_m_expire=2023-04-17%2020%3A16%3A32; dblang=ch
Host: kns.cnki.net
Origin: https://kns.cnki.net
Referer: https://kns.cnki.net/kns8/defaultresult/index
sec-ch-ua: "Chromium";v="112", "Microsoft Edge";v="112", "Not:A-Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48
X-Requested-With: XMLHttpRequest
'''
headers = dict([[y.strip() for y in x.strip().split(':', 1)] for x in head.strip().split('\n') if x.strip()])
在这里找↓↓↓
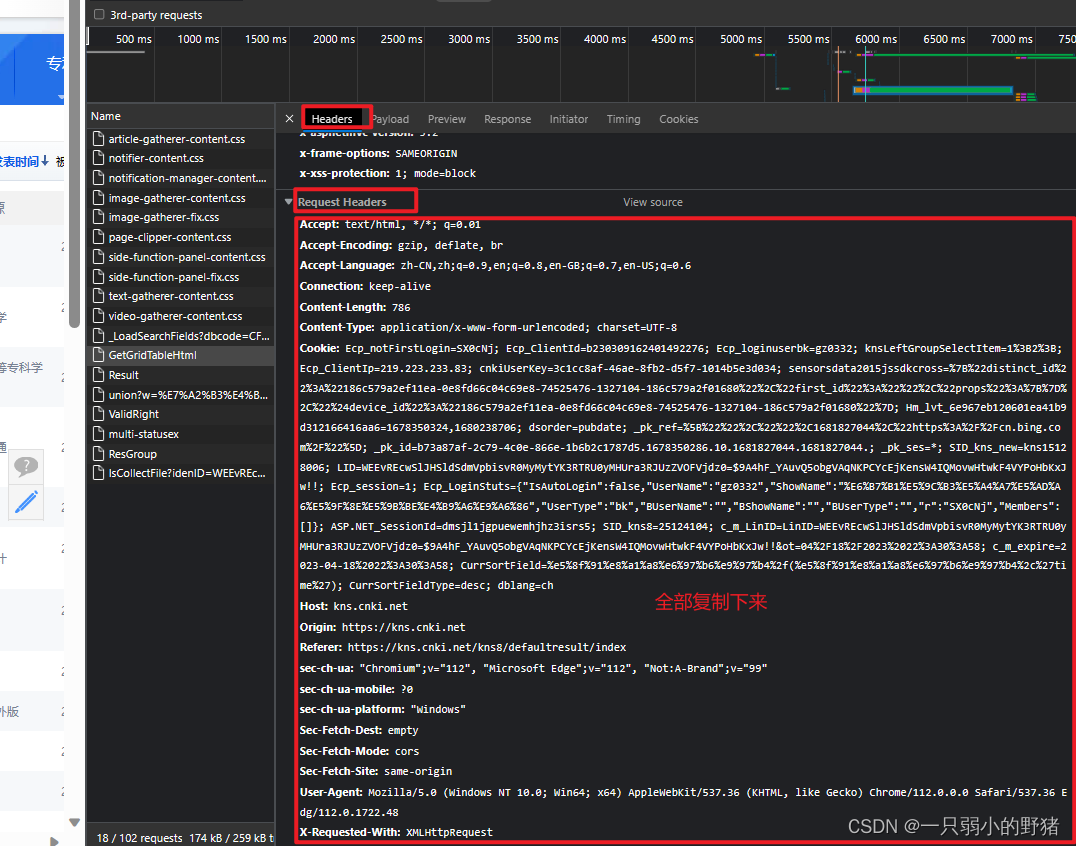
- 这一段把另一个参数赋值下来,方法和上面是一样的,直接copy+赋值+转字典;
*(代码注释和下面都有一段关于这个参数的独特之处解释,倘若是只看思路可以不去细究其加密方式,跳过分析阶段)*
# head的issearch参数我直接设置为false,具体分析看注释
head = '''
IsSearch: false
QueryJson: {"Platform":"","DBCode":"CFLS","KuaKuCode":"CJFQ,CDMD,CIPD,CCND,CISD,SNAD,BDZK,CCJD,CCVD,CJFN","QNode":{"QGroup":[{"Key":"Subject","Title":"","Logic":1,"Items":[{"Title":"主题","Name":"SU","Value":"碳中和","Operate":"%=","BlurType":""}],"ChildItems":[]}]},"CodeLang":"ch"}
SearchSql: $s
PageName: defaultresult
DBCode: CFLS
KuaKuCodes: CJFQ,CDMD,CIPD,CCND,CISD,SNAD,BDZK,CCJD,CCVD,CJFN
CurPage: $page
RecordsCntPerPage: 20
CurDisplayMode: listmode
CurrSortField: PT
CurrSortFieldType: desc
IsSentenceSearch: false
Subject:
'''
s = '0645419CC2F0B23BC604FFC82ADF67C6E920108EDAD48468E8156BA693E89F481391D6F5096D7FFF3585B29E8209A884EFDF8EF1B43B4C7232E120D4832CCC8979F171B4C268EE675FFB969E7C6AF23B4B63CE6436EE93F3973DCB2E4950C92CBCE188BEB6A4E9E17C3978AE8787ED6BB56445D70910E6E32D9A03F3928F9AD8AADE2A90A8F00E2B29BD6E5A0BE025E88D8E778EC97D42EF1CF47C35B8A9D5473493D11B406E77A4FF28F5B34B8028FE85F57606D7A3FED75B27901EEF587583EBD4B63AC0E07735BE77F216B50090DEE5ABB766456B996D37EB8BDACA3A67E8126F111CF9D15B351A094210DB6B4638A21065F03B6F0B73BB4625BBECE66F8197909739D8FB4EB756DEF71864177DFA3CB468CFA6E8ABF7924234DED6B0DFD49D9269CBA4A2BF4075D517A61D094225D70C1B4C137DB9614758A5E097376F5F3E55A7063A4B7E437436D13FF3CC8FB435E131FFCD16FC30DD997098B4FC997D995E767E2712175BC05B960D3FEB5CAF12A13BD1CE3530AD72FC4DB93206996E216BC5DC294960A0CA05E986848E1E64FFC5A52BFCB41A97840A708E397F11EFF261E08F3A34094061AE8E8F819AF6A17A9E2176C3893C6DD3E3C06864C91989BDEF9790A38FAF2524B17743B30EBA4ADD550BF985F9C3097A608C697283CE37F8CB78BDC9EAA4874C3485E6F931B016EC41BFBC0EF91B2AD7E1B424E1DFB8FC8771DEA2458C5A7A4C9BF0192C101FD8EDDEE1BACB44C3E478361EF0D1B70FAD56BCF6870A6044D3A226611B9C1A43C6F9F7C021C98E0D5F778D72C87183F026071A730B8BB4FABF9F68FEC783AB1E6E79218B5D87FD1BB541817FB4F3C21DC849A803CB8A620A2EE00475BAF2CE6556638B7A949B446F39A1076DA15764A777BA6239447CB91F4CF513325366E167D268DDB75F288B5C13415CE62F5C431181C044A28CA502FF14439E5C6F63D419CB6DE1360DB01593FE765459299E442EE24917C199AB5178F38461F8C4EBBC95344C5F2AB60F379813A87E2E3AFE3021198B8222CEAB870D9A353786079961184D63977917C7DF8FE6AFBBC795A832BDD454D6E3CD22C3FF7A58808923DD6F464C12A9A88FBFD0C71458AB0E4C1D566315181A9578ECE93670E5CAF13CF2553F68E64726C131F4A48B42A9E7F09EFEBA51D1FDA6BA0ECA0B02B951ECC04548F1D4D08DB69D0EFDCE6793537BB8E59DC442631A9CDBA13878D7493AADA0CD868C1C1C3A6A6FA17C4109205A83F9C0C43E0D2551D0A8592EA99D20D4B78B4EEEE2D53A543701F620C7D6FF46E800B0CEF9B3D23ACD62C7CBEA25FC8BD74D5A0E5C86B9CF3FCACBDBE585AFF85F9689CBF5BCBD267C580361D5B93AA9BD5A1BB6122BB87C04AE227211FE675A4650814F2285261E5641683D65E0454E2597F6025BB4AA1A044D7B97F57394EA5EC878B80FC0A82F12E2D3D9E1BCB062A7ABB290F02116BDED95761A67CE2FDDE42BDDDF34F22E49A0406D724FEBC86B93F80BB52A8D34B8D2B24288ECBC3F90CCB1EF36085E77F1E2AE0AB411FE60A033E704A21469EA5CE4BB8AF6B1C1F1C5F1F084472D57F458CC39F0B2FE583D0795159E9E38BD1102F5D96DB0F828B66F41A702BB0AE59E40CF53BE7F6342EF208434CFFABF845AFD771B288D484BB79952159E6EA27658A6B6230557AF16E86C4AFDF973DBD5A3A2B979AD9037441409D22A954DC50CBCEA8EA5AC500C4BC8282DCE2626BD2B2CB4B1E33B2E1F92533F7F04C48D061907DBCE3E21FF0A77F09C1AE33E769962CD1EDE6B688590D569409EE9EEC4DF1074DCC97C43B0EDAF1C38B5B2784ABC803D9B3B4FC35F46CB1E275E7F83036FC6AFF2E624D4D2E6AE1C2D4CE3FF219FA90A935957E0DE1A386E4AAB5C9F9D1CECA909F5698BFA86C57B6A73D3C0F9FDB94128B7BB9FDD19D57E4C2C2F4127A1F127A96ABF248B26D8B6EF12A1EA97D064564D33D46E5CA71F53FA121A7E5C91ED2B08BE64A0E3D22BE26FC251C0BF4CF21674DE19AF410E3EDFBD9A4BBEA6C709A1E42B5C17E1EE7AA33EFB0F375BF0858D49210A71662313FA5B8E04E508A5E9425D49C3C5D12CB8DCADBF8A148BFA042BBB0218AAC403AAB9CECC45FD33CEC6797FC984BF91FF638AF6E1F09546F595CFC779D2D867282C63B78DC6A6ED3C1C3887462C84AC07C756C5A8D8A8B2EFD39C28A68D47091A3312461BC20085636F4B41F22D5B46861F3E557777CDCFDFE6CAB8ABECFECA3634D779C0F21185772C426BE383BD26E1715DAB5EC4AE4CAC877ED6899CBCB31546F9C6144399C7C0257BBCCBE0EBD2E90EA901840211FCBB1655CB66FD9C51E90432B273CC4CFF3F8DBEB24CDB0ED6017FE68A7F3E9156E1BA276526DE9599A66921F0E2C3ED466FDE0076DCDA6745F29D28E406BEE5FFB0D4C5FB5D72029BAE56BC22496567FF64341F89469703987DD9D700C08346782F57BA62479812820C862D3D5C604C5C26A76F1A7EC503EB4892BAEB25BB44E783FFB3F1B2F5BECB16A5B48F4D769C3DD5713D2B00AEF4870248A1D561623C9418C285CEE86E1C8DF4A73ED729D7789577456281B4F4D1EE3447E6F8391341BB8F15CF9712E73DBE149164B95748F35D6A4CB4492B8D082AB372E96FC29D1578B41D85F0B7A04EFCBE928642D5D2825F978805C43062C3DF3F0915B33F58A8D82BCC523F3C36B9BAEB9226A39549408AFD3119A8B39B8887038107EB5A623D59186BFFF562E624E1BC25A0C8AA6DD298AEC09B06802A77DFD11799D29506307693DAB2962B98EF9F25E785619D05BDE7073474E187D59D41F6A2E06CC292AD406C2991D9C5E58812A1431B46AB634D548433B1E437D745A013EF5950818CC2A2860B4A7D93BE2DDF0AAAE0627B587A6FAD3FBFFCE90BEFB8ED5F71EAA17F6A0841841EC096D2F47AEA2203CD44B0D68A7B02FE7BEA80BA3CC925155610F00B7D631D150EBA6FFE62E756004A946F9E0F8728DC9E87768D1AC6560DA6A15382DFFA62B129957D4B23F4921C46631D24125DD5CACA73481F2CBDE5'
# 这里解释一下这个网站的小伎俩,当page为1时,isresearch值为true,这时不会显示Searchsql,
# 但是一旦你多翻两页,就会发现page>1时,isresearch值为false,这时就会显示Searchsql,这里我直接尝试设置page为1时issearch为false,发现并不影响,所以只改page即可
# s是查询sql在IsrSearch为false的html里面可以找到 GetgridTableHtml和ValidRight都可以找到sql
page = 0
head = head.replace('$s', s)
head = head.replace('$page', str(page))
data = dict([[y.strip() for y in x.strip().split(':', 1)] for x in head.strip().split('\n') if x.strip()]) #转成特定格式,可以打印出来看
((( 需要注意的是这个sqlsearch参数,需要翻到下一页的GetGridTableHtml文件里才能找到,isreash参数直接设置为false即可。
这个参数在这里copy,要进到 第二页论文 才会出现↓↓↓
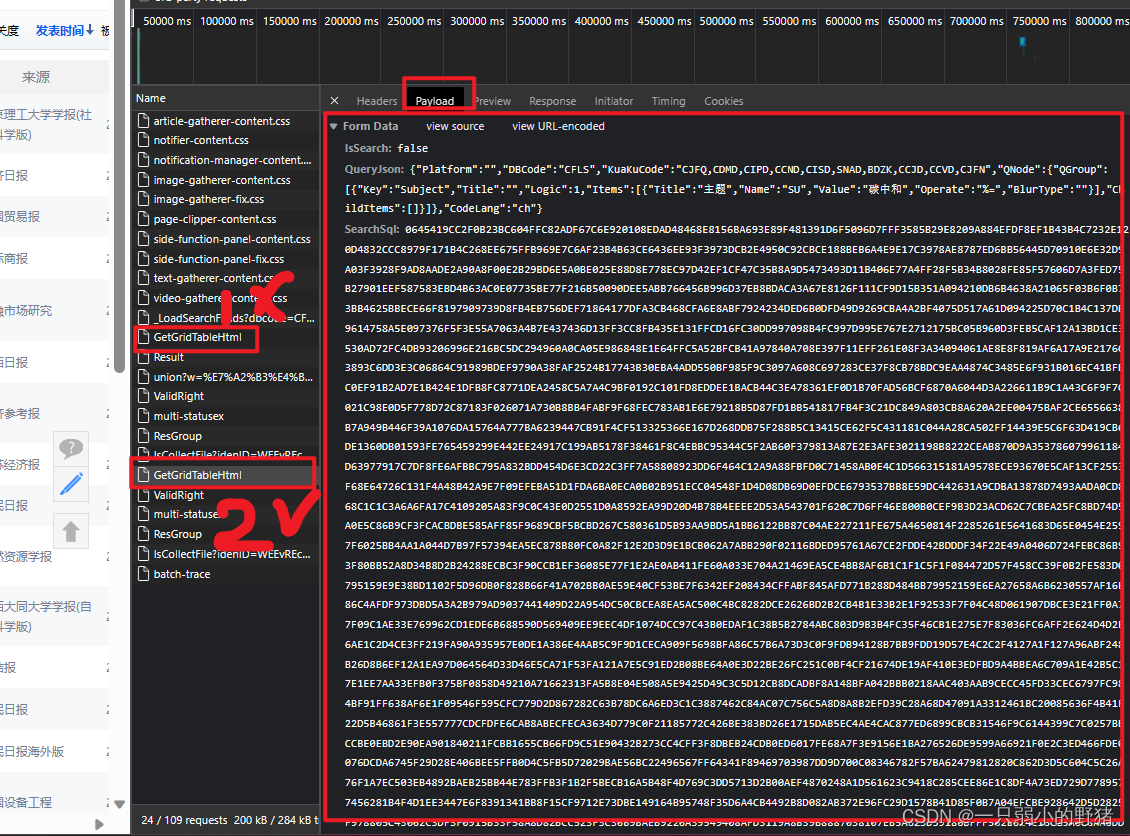
- 接下来写一个专门的函数来重复完成不同页论文的爬取工作,代码的逻辑和前面爬B站用
json是一样的,只不过这里是用Beautifulsoup来解析网页,用find和find_all方法来定位元素。
def cal(url, headers, data, Curpage, database):
## 爬取指定页的论文信息
data['CurPage'] = Curpage
res = requests.post(url, timeout=30, data=data,
headers=headers).content.decode('utf-8')
bs = BeautifulSoup(res, 'html.parser')
target = bs.find('table', class_="result-table-list")
names = target.find_all(class_='name')
authors = target.find_all(class_="author")
sources = target.find_all(class_="source")
dates = target.find_all(class_="date")
datas = target.find_all(class_="data")
for k in range(len(names)):
# 用text提取字符段,strip()去除空格或其他转义符
name = names[k].find('a').text.strip()
author = authors[k].text.strip()
source = sources[k].text.strip()
date = dates[k].text.strip()
data = datas[k].text.strip()
href = "https://kns.cnki.net/" + names[k].find('a')['href'] # 提取文章链接
database.append([name, author, source, date, data, href])
- 最后一个部分就是调用这个函数爬取不同页面的论文数据啦~记得储存到excel文件中(^ ▽ ^)
database = [] # 建一个空列表存储数据
for m in range(1, 3, 1): # 爬前两页的论文
cal(url, headers, data, str(m), database)
import pandas as pd
# 用pandas操作写入,设置好列名
df = pd.DataFrame(database, columns=["Title", "Author", "Source", "Publish_date", "Database", "Link"])
df.to_excel('./paper.xlsx', sheet_name="Sheet1", index=False)
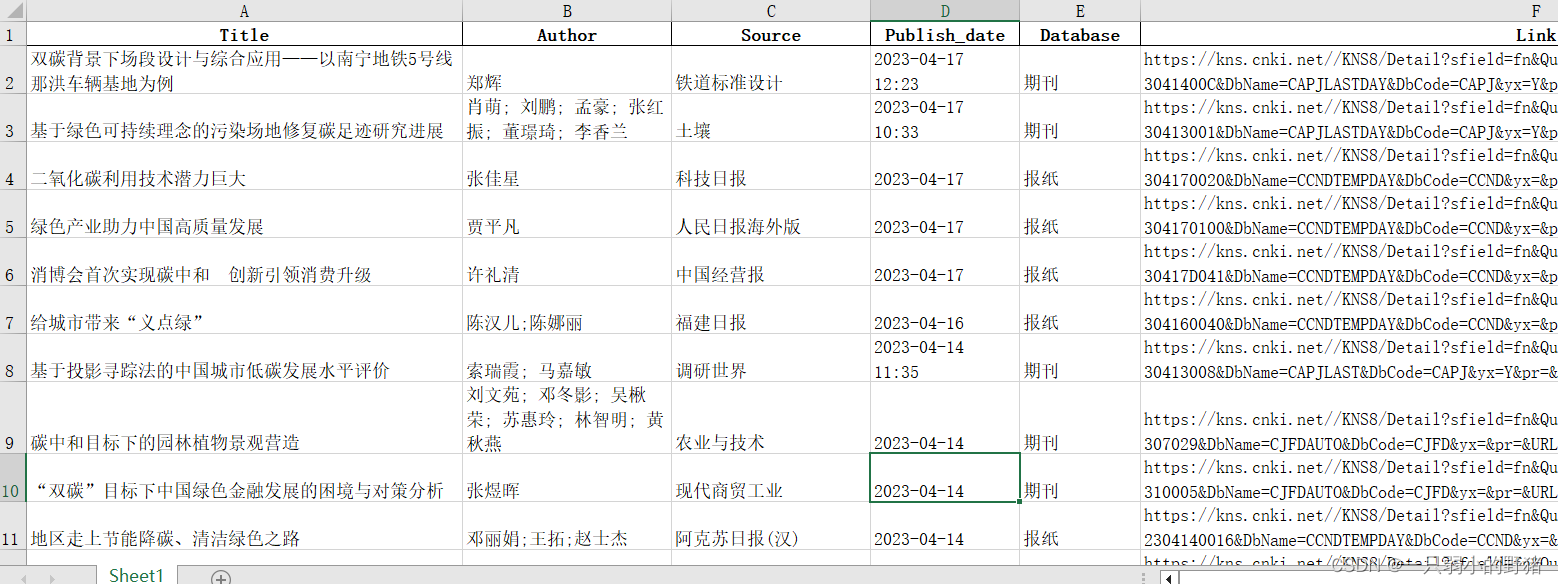
- 结果如下↓↓↓
问题及回顾
- 问题:
虽然最后的爬虫的确有相对理想的效果,但是在写代码过程遇到以下三个问题还未想明白,希望有大佬能在评论区留下解答:
① B站爬取的数据和实时页面有一定出入 ,比如我爬取的第一个数据标题是【这也太不合理了吧】,但是按照那个网页解析出来的第一个应该是【AI一眼就看透了我的本质】,我目前有两个怀疑方向:一是这个热门榜是不停在变的,每隔一段时间就会变化;二是我翻到的那个网址并不是目标网址。但这两种怀疑在网页解析过程中都没找到痕迹,不知道具体是什么原因。
② 在爬论文时,我其实一开始没有专门def一个函数出来,完全是因为这段代码会有以下报错
Traceback (most recent call last): File "D:\PyTest\爬虫\COVID-19\spider.py", line 91, in <module> data['CurPage'] = str(j) TypeError: 'str' object does not support item assignment
希望这里能有大哥解答这里为什么会涉及字符无法更改的报错。
## 这段代码就是在 data = dict([[y.strip() for y in x.strip().split(':', 1)] for x in head.strip().split('\n') if x.strip()]) 那一行的后面
for j in range(2, 5):
data['CurPage'] = str(j)
res = requests.post(url, timeout=30, data=data,
headers=headers).content.decode('utf-8')
bs = BeautifulSoup(res, 'html.parser')
target = bs.find('table', class_="result-table-list")
names = target.find_all(class_='name')
authors = target.find_all(class_="author")
sources = target.find_all(class_="source")
dates = target.find_all(class_="date")
datas = target.find_all(class_="data")
for k in range(len(names)):
name = names[k].find('a').text.strip()
author = authors[k].text.strip()
source = sources[k].text.strip()
date = dates[k].text.strip()
data = datas[k].text.strip()
href = "https://kns.cnki.net/" + names[k].find('a')['href'] # 提取文章链接
③ 论文页第一页将一个重要参数sqlsearch隐藏,当时没有往后翻,导致浪费大量时间,这种操作是如何实现的?不是很能凭直觉猜测和理解。
- 回顾:
本文尝试将爬虫的四个步骤映射到实际需求中进行操作,但技术水平有限,权做一次爬虫基本知识的复习梳理以及同友人的交流机会haha~
可以看到,网页解析方式是多种多样的,网站加密方式也是在不断进步的。
今天课上我玩了一下ChatGPT,要他写一个B站热门的爬取代码,因为GPT数据库的问题,他写出来的代码确实能解决20年左右的B站爬取问题,但如今因为网站加密方式改进,代码已经运行不出效果了,还有其他许多网站也是如此。
不过,仅针对文本资源爬取的话,本文涉及的思路和步骤应该是绝大部分爬虫工作时都绕不开的。
最后,感谢每位经验分享者,在下只是一只小小爬虫,唯有在大家的知识网站中游弋才能爬取智慧。

(顺带吐槽一嘴,CSDN的这个图片水印真丑捏╮(╯▽╰)╭)