1. 背景及目的:维基百科是任何人都可以编辑和贡献的免费在线百科全书。它支持多种语言,并且一直在增长。在英语版本的Wikipedia上,当前有470万页,共有超过7.6亿次的编辑。任何人都可编辑的后果之一是有些人破坏了页面。这可以采取以下形式:删除内容,添加促销或不适当的内容,或者进行更细微的更改以改变文章的含义。每天有如此多的文章和编辑,人类很难检测到所有故意破坏行为并还原(撤消)它们。结果,维基百科使用了bots(计算机程序),该计算机程序会自动还原看起来像故意破坏的编辑内容。因此,我们尝试运用文本挖掘的方式开发一种破坏机检测器,该检测器使用机器学习来区分有效编辑和破坏机。
2. 数据介绍:此问题的数据基于页面语言的修订历史记录。维基百科提供了每个页面的历史记录,其中包括每个修订版的页面状态。而不是手动考虑每个修订版,而是运行一个脚本来检查是否保留编辑或还原了编辑。如果更改最终被撤消,则该修订被标记为故意破坏。这可能会导致一些错误分类,但是脚本可以满足我们的需求。
作为这种预处理的结果,已经完成了一些常见的处理任务,包括降低外壳和标点符号的位置。数据集中的列为:
- Vandal: 如果此编辑是故意破坏,则破坏者= 1,否则则为0。
- Minor: 如果用户将此编辑标记为“次要编辑”,则Minor = 1,否则为0。
- Loggedin: 如果用户使用Wikipedia帐户进行此编辑,则Loggedin = 1,否则,则为0
- Added: 添加的唯一词
- Removed:删除的唯一词
注意:我们拥有的数据不是传统的单词包,而是被删除或添加的单词集。例如,如果某个单词在修订版中被删除了多次,则该单词只会在“已删除”列中出现一次。
3. 应用及分析
# 读取数据
wiki <- read.csv("wiki.csv", stringsAsFactors = F)
str(wiki)

# Convert the "Vandal" column to a factor wiki$Vandal <- as.factor(wiki$Vandal) table(wiki$Vandal)

数据预处理
注意:该数据集已经全部是小写,且去除了标点符号
library(tm)
library(NLP)
corpusAdded <- VCorpus(VectorSource(wiki$Added)) # create corpus for the Added column
length(stopwords("english")) # check the length of english-language stopwords
corpusAdded <- tm_map(corpusAdded, removeWords, stopwords('english')) # remove the english-language stopwords
corpusAdded <- tm_map(corpusAdded, stemDocument) # stem the words
dtmAdded <- DocumentTermMatrix(corpusAdded) # build the document term matrix
sparseAdded <- removeSparseTerms(dtmAdded, 0.997) # remove sparse words
wordsAdded <- as.data.frame(as.matrix(sparseAdded)) # convert sparseAdded into a data frame
colnames(wordsAdded) = paste("A", colnames(wordsAdded)) # prepend all the words with the letter A
corpusRemoved <- VCorpus(VectorSource(wiki$Removed)) # create corpus for the Added column
length(stopwords("english")) # check the length of english-language stopwords
corpusRemoved <- tm_map(corpusRemoved, removeWords, stopwords('english')) # remove the english-language stopwords
corpusRemoved <- tm_map(corpusRemoved, stemDocument) # stem the words
dtmRemoved <- DocumentTermMatrix(corpusRemoved) # build the document term matrix
sparseRemoved <- removeSparseTerms(dtmRemoved, 0.997) # remove sparse words
wordsRemoved <- as.data.frame(as.matrix(sparseRemoved)) # convert sparseAdded into a data frame
colnames(wordsRemoved) = paste("R", colnames(wordsRemoved)) # prepend all the words with the letter A
wikiWords = cbind(wordsAdded, wordsRemoved)
wikiWords$Vandal <- wiki$Vandal # final data frame
将数据分为训练集和测试集
library(caTools) set.seed(123) spl <- sample.split(wikiWords$Vandal, 0.7) wiki.train <- subset(wikiWords, spl ==T) wiki.test <- subset(wikiWords, spl == F) # baseline accuracy table(wiki.test$Vandal)/nrow(wiki.test)

构建CART模型
# CART model library(rpart) library(rpart.plot) wiki.train.cart1 <- rpart(Vandal ~ ., data = wiki.train, method = 'class') prp(wiki.train.cart1)

wiki.cart1.pred <- predict(wiki.train.cart1, newdata = wiki.test, type = 'class') # predict on the test set library(caret) confusionMatrix(wiki.cart1.pred, wiki.test$Vandal)

尽管CART模型比baseline,但准确率也只有54.17%。因此,通过增删词汇预测并不是一个很好的办法,接下来我们将想办法改进模型。
模型改进1:辨认关键词
“网站地址”(也称为URL-统一资源定位符),由两个主要部分组成。例如“ http://www.google.com”。第一部分是协议,通常为“ http”(超文本传输协议);第二部分是网站的地址,例如“ www.google.com”。我们删除了所有标点符号,因此指向网站的链接在数据中显示为一个词,例如“ httpwwwgooglecom”。我们假设,由于很多人为破坏行为似乎都在添加到促销或不相关网站的链接,网址的存在是故意破坏的迹象。因此,我们可以通过在“添加的”列中搜索“ http”来搜索添加的单词中是否存在网址。
# Create a copy of your dataframe from the previous question:
wikiWords2 <- wikiWords
# Make a new column in wikiWords2 that is 1 if "http" was in Added:
wikiWords2$HTTP <- ifelse(grepl("http",wiki$Added,fixed=TRUE), 1, 0)
table(wikiWords2$HTTP)

将新的数据分为测试集和训练集,并构建CART模型
wikiTrain2 <- subset(wikiWords2, spl==TRUE) wikiTest2 <- subset(wikiWords2, spl==FALSE) # CART model wiki2.train.cart1 <- rpart(Vandal ~ ., data = wikiTrain2, method = 'class') prp(wiki2.train.cart1)

用构建的CART模型预测并计算准确性
wiki2.cart1.pred <- predict(wiki2.train.cart1, newdata = wikiTest2, type = 'class') confusionMatrix(wiki2.cart1.pred, wikiTest2$Vandal)

模型改进2:文本计数
在此,我们假设可以通过增加/删除文字的个数来预测。因此,构建新的一列来表示每一个观测值增加/删除的文字的总数,重新划分测试集、训练集,并构建CART模型
# We already have a word count available in the form of the document-term matrices (DTMs).
wikiWords2$NumWordsAdded <- rowSums(as.matrix(dtmAdded)) wikiWords2$NumWordsRemoved <- rowSums(as.matrix(dtmRemoved)) wikiTrain3 <- subset(wikiWords2, spl==TRUE) wikiTest3 <- subset(wikiWords2, spl==FALSE)
# CART model
wiki3.train.cart1 <- rpart(Vandal ~ ., data = wikiTrain3, method = 'class')
prp(wiki3.train.cart1)
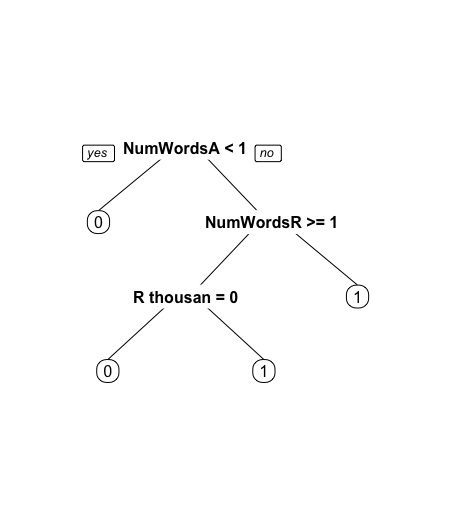
用构建的CART模型预测测试集数据并计算准确性
wiki3.cart1.pred <- predict(wiki3.train.cart1, newdata = wikiTest3, type = 'class') confusionMatrix(wiki3.cart1.pred, wikiTest3$Vandal)

模型改进3:使用更多的信息
在此,我们引入Minor和Loggin两个变量
wikiWords3 <- wikiWords2 wikiWords3$Minor <- wiki$Minor wikiWords3$Loggedin <- wiki$Loggedin wikiTrain4 <- subset(wikiWords3, spl==TRUE) wikiTest4 <- subset(wikiWords3, spl==FALSE) # CART model wiki4.train.cart1 <- rpart(Vandal ~ ., data = wikiTrain4, method = 'class') prp(wiki4.train.cart1)
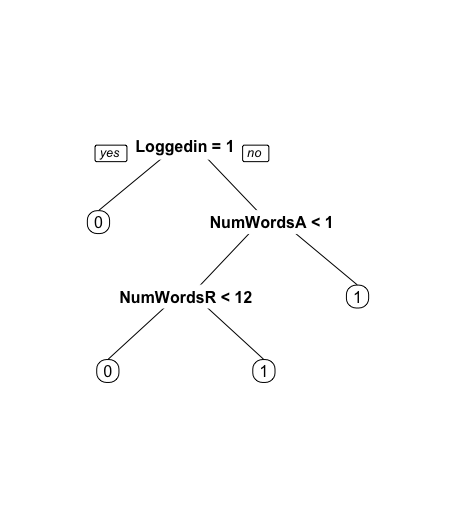
模型预测及其准确性
wiki4.cart1.pred <- predict(wiki4.train.cart1, newdata = wikiTest4, type = 'class') confusionMatrix(wiki4.cart1.pred, wikiTest4$Vandal)

因此,通过不断地改进,模型准确率由54.17%提升至71.88%。