参考文章:
https://www.cnblogs.com/xrq730/p/5087378.html
https://www.cnblogs.com/Katerina/p/11459135.html
https://www.cnblogs.com/blog-pl/p/10919393.html
1. 特性
原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;长生王者
一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
隔离性: 并发访问数据库时,一个事务不被其他事务所干扰,各并发事务之间数据库是独立的;
持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
2. 可导致异常
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
- 不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,慕北屹顾小陌因此称为不可重复读。
幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
不可重复度和幻读区别
不可重复读的重点是修改,幻读的重点在于新增或者删除。
例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
3. 事务隔离级别
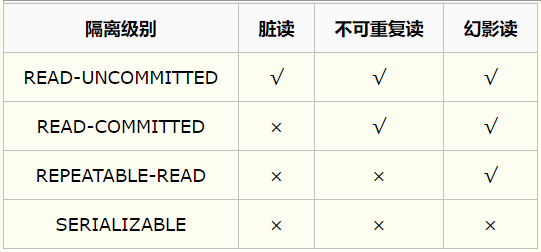
SQL 标准定义了四个隔离级别:
READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。一往情深傅少心尖爱妻
READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
4. 这里需要注意的是
与 SQL 标准不同的地方在于InnoDB 存储引擎在 REPEATABLE-READ(可重读)事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的SERIALIZABLE(可串行化)隔离级别。