目录
20182324 2019-2020-1 《数据结构与面向对象程序设计》第9周学习总结
教材学习内容总结
1、查找
查找是在一组数据项内找到指定目标或是确定目标不存在的过程。
线性查找
二分查找
二分查找利用了查找池有序的特性,同时也要求表必须是有序的。相比于线性查找,二分查找更加高效。哈希查找
通过存储不同的哈希值来确定元素的位置
2、排序
排序是按某种标准将一列数据项按确定的次序重排的过程。
选择排序
反复地将一个个具体的值放到它最终的有序位置,从而完成排序。插入排序
反复地将一个个具体的值插入到表的已有序子表中,从而完成排序。冒泡排序
反复地比较两个相邻元素,如果必要就交换次序,从而完成排序。快速排序
通过划分子表,递归地对两个子表进行排序,从而完成排序。关键是要选择一个好的划分元素。归并排序
递归地将表平分为两部分,直到每个子表中只含一个元素,将这些表归并为有序表,从而完成排序。排序算法效率
教材学习中的问题和解决过程
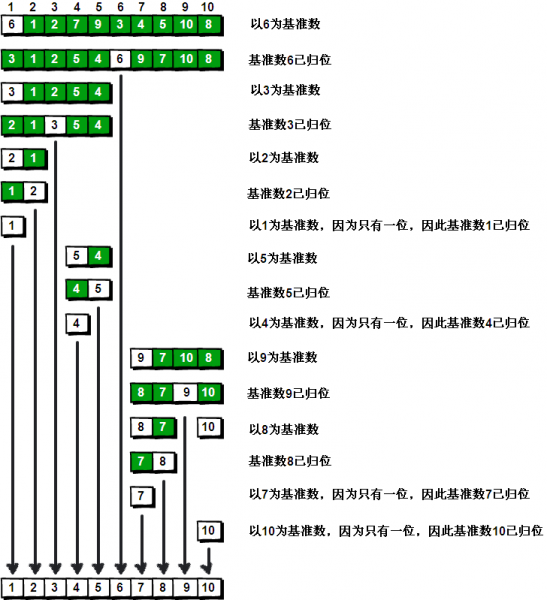
- 问题1:快速排序是怎样排序的
问题1解决方案:快速排序算法通过划分表,再递归地对两个子表进行排序,从而完成一组值的排序。最好的情况是枢纽元选取得当,每次都能均匀的划分序列, 时间复杂度为 O(n log n);最坏情况是枢纽元为最大或者最小数字,所有数都被划分到一个序列中,退化为冒泡排序,时间复杂度为O(n²)。所以快速排序的关键是要选取一个好的划分元素。
- 问题2:为什么有些时候使用二分查找却出现找不到元素的情况
问题2解决方案:二分查找的前提是查找池元素有序,倘若是乱序的,就会误导查找方向从而结果错误。
代码调试中的问题和解决过程
- 问题:泛型 T 不能传入 int 类型的参数。
- 问题解决方案:泛型类的类型不能是基本数据类型,可将变量从 int 型 改为 Integer 。可参考 为什么泛型类的类型不能是基本数据类型和 Java 面试题之 int 和 Integer 的区别
代码托管
(statistics.sh脚本的运行结果截图)
上周考试错题总结
In an ideal implementations of a stack and a queue, all operations are ______________________ .
A. O( 1 )
B. O( n )
C. O( n log n )
D. O( n² )
E. it depends on the operation
解析:In good implementations of stacks and queues, all operations require a constant amount of time.In a array-based implementation of a queue that stores the front of the queue at index 0 in the array, the dequeue operation is ___________________.
A. impossible to implement
B. has several special cases
C. O( n )
D. O( n² )
E. none of the above
解析:It requires a linear amount of time to shift all elements of the queue down an index after a remove is applied.In a circular array-based implementation of a queue, the elements must all be shifted when the dequeue operation is called.
A. true
B. false
解析:A circular array-based implementation of a queue eliminates the need to shift elements, so all queue operations can be achieved in constant time.One of the uses of trees is to provide simpler implementations of other collections.
A. true
B. falseSince a heap is a binary search tree, there is only one correct location for the insertion of a new node, and that is either the next open position from the left at level h or the first position on the left at level h+1 if level h is full.
A. true
B. false
结对及互评
点评:
- 博客中值得学习的或问题:
- 图文并茂,有参考资料
- markdown 格式运用较为熟练
- 代码中值得学习的或问题:
- 代码格式规范,合理使用空白,便于阅读
- 基于评分标准,我给本博客打分:14分。得分情况如下:
- 1、正确使用Markdown语法(加1分)
- 2、模板中的要素齐全(加1分)
- 3、教材学习中的问题和解决过程(2分)
- 4、代码调试中的问题和解决过程(1分)
- 5、本周有效代码超过300分行的(加2分)
- 6、其他加分:
- 感想,体会不假大空的加1分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
- 点评认真,能指出博客和代码中的问题的加1分
- 结对学习情况真实可信的加1分
- 参考示例
点评过的同学博客和代码
- 本周结对学习情况
- 结对学习内容
- 创建 Node 的 ADT 接口,以及 Link 的 ADT 接口以适应树的建立。
- 学习理解二叉树、完全二叉树、满二叉树的概念。
- 学会使用树的先序遍历、中序遍历、后序遍历,来查找、建立二叉树。
- 学习二叉树的排序方法,并运用二叉树查找。
- 学习实现二叉排序树。
其他(感悟、思考等,可选)
查找与排序是数据结构里面入门级的算法,三年前学 Pascal 的时候因为高中学科时间原因没有进行深入学习,留下了很大遗憾,希望能在现在补回来。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 10000行 | 30篇 | 400小时 | |
| 第一周 | 109/109 | 2/2 | 28/28 | 学习了Java的基本语法格式,熟练使用 Linux Bash 命令 |
| 第二周 | 550/659 | 1/3 | 23/51 | 学习掌握JDB调试命令 |
| 第三周 | 1028/1687 | 2/5 | 30/81 | 学习类的编写与使用 |
| 第四周 | 542/2229 | 2/7 | 22/103 | 学习方法重载,类的继承、聚合等 |
| 第五周 | 1197/3426 | 2/9 | 15/118 | 学习 Java Socket ,了解加密算法 |
| 第六周 | 1344/4770 | 1/10 | 22/140 | 学习多态与异常处理 |
| 第七周 | 3190/7960 | 2/12 | 30/170 | 学习Android |
| 第八周 | 1588/9548 | 2/14 | 30/200 | 学习查找与排序 |
| 第九周 | 3152/12700 | 3/17 | 30/230 | 学习二叉树、二叉查找树和二叉排序树 |
计划学习时间:20小时
实际学习时间:30小时
改进情况:
(有空多看看现代软件工程 课件 软件工程师能力自我评价表)