首先要弄明白一点,从根本上来讲 Git 是一个内容寻址(content-addressable)文件系统,并在此之上提供了一个版本控制系统的用户界面。 马上你就会学到这意味着什么。
- git object
头部信息和任意内容做SHA-1校验的结果作为文件名(前两个字符用于命名目录,剩下的38个字符命名文件);文件内容由 zlib 压缩所得,存在
.git/objects/
- tree object
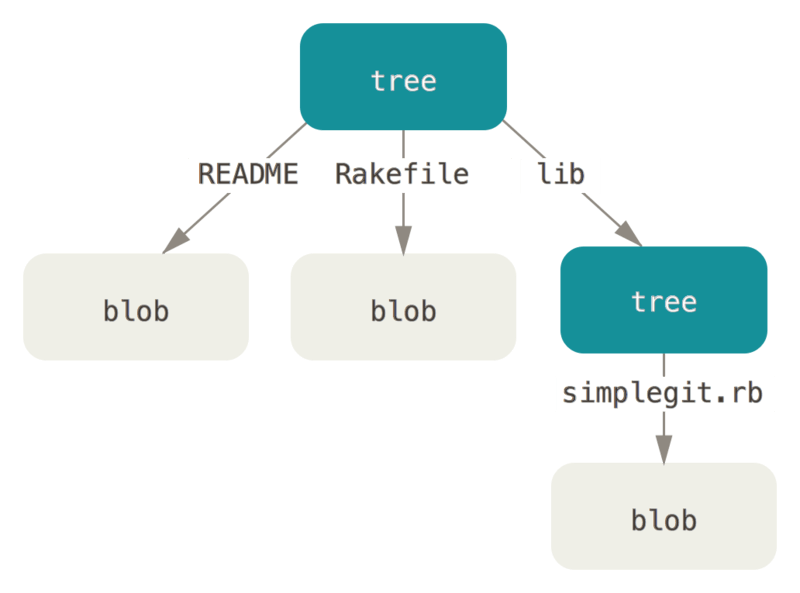
它能解决文件名保存的问题,也允许我们将多个文件组织到一起。 Git 以一种类似于 UNIX 文件系统的方式存储内容,但作了些许简化。 所有内容均以树对象和数据对象的形式存储,其中树对象对应了 UNIX 中的目录项,数据对象则大致上对应了 inodes 或文件内容。 一个树对象包含了一条或多条树对象记录(tree entry),每条记录含有一个指向数据对象或者子树对象的 SHA-1 指针,以及相应的模式、类型、文件名信息。
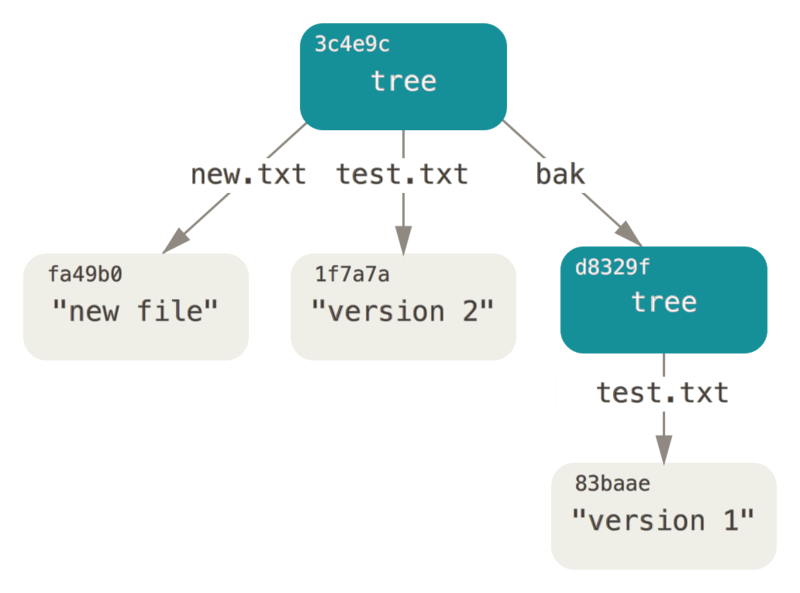
- commit object
现在有三个树对象,分别代表了我们想要跟踪的不同项目快照。然而问题依旧:若想重用这些快照,你必须记住所有三个 SHA-1 哈希值。 并且,你也完全不知道是谁保存了这些快照,在什么时刻保存的,以及为什么保存这些快照。 而以上这些,正是提交对象(commit object)能为你保存的基本信息。
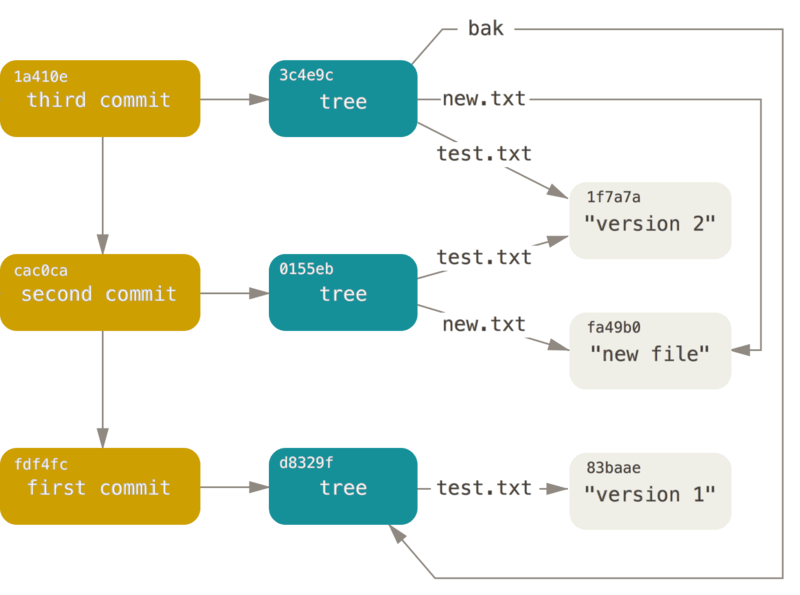
- git 引用
我们可以借助类似于 git log 1a410e 这样的命令来浏览完整的提交历史,但为了能遍历那段历史从而找到所有相关对象,你仍须记住 1a410e 是最后一个提交。 我们需要一个文件来保存 SHA-1 值,并给文件起一个简单的名字,然后用这个名字指针来替代原始的 SHA-1 值。在 Git 里,这样的文件被称为“引用(references,或缩写为 refs)”;你可以在 .git/refs 目录下找到这类含有 SHA-1 值的文件。

tree object: