今天,发生了很大的事情,因为项目临时更换,有很多新的东西要学,还要做整个项目把控,先装一波,个人也是尽我所能,暂时对未来有点朦胧。之前个人做笔记总是把记录,后来发现还是要类似于把每天发生的东西记下来,因为时间过去了就回不去了,要有落地,落地,个人感觉已经到临界点,不知道还能撑多久,哎,漫漫人生路,以后坚持每天1篇。我们不要把时间浪费在无用的地方。开始记录吧。
Git 内部原理
你将认识到Git 的内部工作原理和实现方式。。我个人发现学习这些内容对于理解 Git 的用处和强大是非常重要的,不过也有人认为这些内容对于初学者来说可能难以理解且过于复杂。正因如此我把这部分内容放在最后一章,你在学习过程中可以先阅读这部分,也可以晚点阅读这部分,这完全取决于你自己。
既然已经读到这了,就让我们开始吧。首先要弄明白一点,从根本上来讲 Git 是一套内容寻址 (content-addressable) 文件系统,在此之上提供了一个 VCS 用户界面。马上你就会学到这意味着什么。
内容寻址文件系统这一层相当酷,在本章中我会先讲解这部分。随后你会学到传输机制和最终要使用的各种库管理任务。
9.1 底层命令 (Plumbing) 和高层命令 (Porcelain)
本书讲解了使用 checkout, branch, remote 等共约 30 个 Git 命令。然而由于 Git 一开始被设计成供 VCS 使用的工具集而不是一整套用户友好的 VCS,它还包含了许多底层命令,这些命令用于以 UNIX 风格使用或由脚本调用。这些命令一般被称为 “plumbing” 命令(底层命令),其他的更友好的命令则被称为 “porcelain” 命令(高层命令)。
本书前八章主要专门讨论高层命令。本章将主要讨论底层命令以理解 Git 的内部工作机制、演示 Git 如何及为何要以这种方式工作。这命令主要不是用来从命令行手工使用的,更多的是用来为其他工具和自定义脚本服务的。
当你在一个新目录或已有目录内执行 git init 时,Git 会创建一个 .git 目录,几乎所有 Git 存储和操作的内容都位于该目录下。如果你要备份或复制一个库,基本上将这一目录拷贝至其他地方就可以了。本章基本上都讨论该目录下的内容。该目录结构如下:
$ ls
HEAD
branches/
config
description
hooks/
index
info/
objects/
refs/该目录下有可能还有其他文件,但这是一个全新的 git init 生成的库,所以默认情况下这些就是你能看到的结构。新版本的 Git 不再使用 branches 目录,description 文件仅供GitWeb 程序使用,所以不用关心这些内容。config 文件包含了项目特有的配置选项,info目录保存了一份不希望在 .gitignore 文件中管理的忽略模式 (ignored patterns) 的全局可执行文件。hooks 目录包住了第六章详细介绍了的客户端或服务端钩子脚本。另外还有四个重要的文件或目录:HEAD 及 index 文件,objects 及 refs 目录。这些是Git 的核心部分。objects 目录存储所有数据内容,refs 目录存储指向数据 (分支) 的提交对象的指针,HEAD 文件指向当前分支,index 文件保存了暂存区域信息。马上你将详细了解 Git 是如何操纵这些内容的。
9.2 Git 对象
Git 是一套内容寻址文件系统。很不错。不过这是什么意思呢?
这种说法的意思是,从内部来看,Git 是简单的 key-value 数据存储。它允许插入任意类型的内容,并会返回一个键值,通过该键值可以在任何时候再取出该内容。可以通过底层命令 hash-object 来示范这点,传一些数据给该命令,它会将数据保存在 .git 目录并返回表示这些数据的键值。首先初使化一个 Git 仓库并确认 objects 目录是空的:
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$Git 初始化了 objects 目录,同时在该目录下创建了 pack 和 info 子目录,但是该目录下没有其他常规文件。我们往这个 Git 数据库里存储一些文本:

$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4参数 -w 指示 hash-object 命令存储 (数据) 对象,若不指定这个参数该命令仅仅返回键值。--stdin 指定从标准输入设备 (stdin) 来读取内容,若不指定这个参数则需指定一个要存储的文件的路径。该命令输出长度为 40 个字符的校验和。这是个 SHA-1 哈希值──其值为要存储的数据加上你马上会了解到的一种头信息的校验和。现在可以查看到 Git已经存储了数据:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4可以在 objects 目录下看到一个文件。这便是 Git 存储数据内容的方式──为每份内容生成一个文件,取得该内容与头信息的 SHA-1 校验和,创建以该校验和前两个字符为名称的子目录,并以 (校验和) 剩下 38 个字符为文件命名 (保存至子目录下)。通过 cat-file 命令可以将数据内容取回。该命令是查看 Git 对象的瑞士军刀。传入 -p参数可以让该命令输出数据内容的类型:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content可以往 Git 中添加更多内容并取回了。也可以直接添加文件。比方说可以对一个文件进行简单的版本控制。首先,创建一个新文件,并把文件内容存储到数据库中:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30接着往该文件中写入一些新内容并再次保存:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a数据库中已经将文件的两个新版本连同一开始的内容保存下来了:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4再将文件恢复到第一个版本:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1或恢复到第二个版本:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2需要记住的是几个版本的文件 SHA-1 值可能与实际的值不同,其次,存储的并不是文件名而仅仅是文件内容。这种对象类型称为 blob 。通过传递 SHA-1 值给 cat-file -t 命令可以让 Git 返回任何对象的类型:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob9.2.1 tree (树) 对象
接下去来看 tree 对象,tree 对象可以存储文件名,同时也允许存储一组文件。Git 以一种类似 UNIX 文件系统但更简单的方式来存储内容。所有内容以 tree 或 blob 对象存储,其中 tree 对象对应于 UNIX 中的目录,blob 对象则大致对应于 inodes 或文件内容。一个单独的 tree 对象包含一条或多条 tree 记录,每一条记录含有一个指向 blob 或子 tree 对象的 SHA-1 指针,并附有该对象的权限模式 (mode)、类型和文件名信息。以simplegit 项目为例,最新的 tree 可能是这个样子:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libmasterˆtree 表示 branch 分支上最新提交指向的 tree 对象。请注意 lib 子目录并非一个 blob 对象,而是一个指向别一个 tree 对象的指针:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb从概念上来讲,Git 保存的数据如图 9.1 所示。你可以自己创建 tree 。通常 Git 根据你的暂存区域或 index 来创建并写入一个 tree
。因此要创建一个 tree 对象的话首先要通过将一些文件暂存从而创建一个 index 。可以使用 plumbing 命令 update-index 为一个单独文件 ── test.txt 文件的第一个版本── 创建一个 index 。通过该命令人为的将 test.txt 文件的首个版本加入到了一个新的暂存区域中。由于该文件原先并不在暂存区域中 (甚至就连暂存区域也还没被创建出来呢) ,必须传入 --add 参数;由于要添加的文件并不在当前目录下而是在数据库中,必须传入 --cacheinfo 参数。同时指定了文件模式,SHA-1 值和文件名:

$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt在本例中,指定了文件模式为 100644,表明这是一个普通文件。其他可用的模式有:100755 表示可执行文件,120000 表示符号链接。文件模式是从常规的 UNIX 文件模式中参考来的,但是没有那么灵活 ── 上述三种模式仅对 Git 中的文件 (blobs) 有效(虽然也有其他模式用于目录和子模块)。现在可以用 write-tree 命令将暂存区域的内容写到一个 tree 对象了。无需 -w 参数── 如果目标 tree 不存在,调用 write-tree 会自动根据 index 状态创建一个 tree 对象。
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt可以这样验证这确实是一个 tree 对象:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree再根据 test.txt 的第二个版本以及一个新文件创建一个新 tree 对象:
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt这时暂存区域中包含了 test.txt 的新版本及一个新文件 new.txt 。创建 (写) 该 tree对象 (将暂存区域或 index 状态写入到一个 tree 对象),然后瞧瞧它的样子:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt请注意该 tree 对象包含了两个文件记录,且 test.txt 的 SHA 值是早先值的 “第二版” (1f7a7a)。来点更有趣的,你将把第一个 tree 对象作为一个子目录加进该 tree 中。可以用 read-tree 命令将 tree 对象读到暂存区域中去。在这时,通过传一个 --prefix参数给 read-tree,将一个已有的 tree 对象作为一个子 tree 读到暂存区域中:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt如果从刚写入的新 tree 对象创建一个工作目录,将得到位于工作目录顶级的两个文件和一个名为 bak 的子目录,该子目录包含了 test.txt 文件的第一个版本。可以将 Git 用来包含这些内容的数据想象成如图 9.2 所示的样子。

9.2.2 commit (提交) 对象
你现在有三个 tree 对象,它们指向了你要跟踪的项目的不同快照,可是先前的问题依然存在:必须记往三个 SHA-1 值以获得这些快照。你也没有关于谁、何时以及为何保存了这些快照的信息。commit 对象为你保存了这些基本信息。
要创建一个 commit 对象,使用 commit-tree 命令,指定一个 tree 的 SHA-1,如果有任何前继提交对象,也可以指定。从你写的第一个 tree 开始:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d通过 cat-file 查看这个新 commit 对象:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <[email protected]> 1243040974 -0700
committer Scott Chacon <[email protected]> 1243040974 -0700
first commitcommit 对象有格式很简单:指明了该时间点项目快照的顶层树对象、作者/提交者信息(从 Git 设理发店的 user.name 和 user.email中获得)以及当前时间戳、一个空行,以及提交注释信息。
接着再写入另外两个 commit 对象,每一个都指定其之前的那个 commit 对象:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9每一个 commit 对象都指向了你创建的树对象快照。出乎意料的是,现在已经有了真实的Git 历史了,所以如果运行 git log 命令并指定最后那个 commit 对象的 SHA-1 便可以查看历史:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)真棒。你刚刚通过使用低级操作而不是那些普通命令创建了一个 Git 历史。这基本上就是运行 git add 和 git commit 命令时 Git 进行的工作 ──保存修改了的文件的blob,更新索引,创建 tree 对象,最后创建 commit 对象,这些 commit 对象指向了顶层tree 对象以及先前的 commit 对象。这三类 Git 对象 ── blob,tree 以及 tree ──都各自以文件的方式保存在 .git/objects 目录下。以下所列是目前为止样例中的所有对象,每个对象后面的注释里标明了它们保存的内容:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1如果你按照以上描述进行了操作,可以得到如图 9.3 所示的对象图。

9.2.3 对象存储
之前我提到当存储数据内容时,同时会有一个文件头被存储起来。我们花些时间来看看Git 是如何存储对象的。你将看来如何通过 Ruby 脚本语言存储一个 blob 对象 (这里以字符串 “what is up, doc?” 为例) 。使用 irb 命令进入 Ruby 交互式模式:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git 以对象类型为起始内容构造一个文件头,本例中是一个 blob。然后添加一个空格,接着是数据内容的长度,最后是一个空字节 (null byte):
>> header = "blob #{content.length}\0"
=> "blob 16\000"Git 将文件头与原始数据内容拼接起来,并计算拼接后的新内容的 SHA-1 校验和。可以在 Ruby 中使用 require 语句导入 SHA1 digest 库,然后调用 Digest::SHA1.hexdigest()方法计算字符串的 SHA-1 值:
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Git 用 zlib 对数据内容进行压缩,在 Ruby 中可以用 zlib 库来实现。首先需要导入该库,然后用 Zlib::Deflate.deflate() 对数据进行压缩:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"最后将用 zlib 压缩后的内容写入磁盘。需要指定保存对象的路径 (SHA-1 值的头两个字符作为子目录名称,剩余 38 个字符作为文件名保存至该子目录中)。在 Ruby 中,如果子目录不存在可以用 FileUtils.mkdir_p() 函数创建它。接着用 File.open 方法打开文件,并用 write() 方法将之前压缩的内容写入该文件:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32这就行了 ── 你已经创建了一个正确的 blob 对象。所有的 Git 对象都以这种方式存储,惟一的区别是类型不同 ── 除了字符串 blob,文件头起始内容还可以是 commit 或tree 。不过虽然 blob 几乎可以是任意内容,commit 和 tree 的数据却是有固定格式的。
9.3 Git References
你可以执行像 git log 1a410e 这样的命令来查看完整的历史,但是这样你就要记得1a410e 是你最后一次提交,这样才能在提交历史中找到这些对象。你需要一个文件来用一个简单的名字来记录这些 SHA-1 值,这样你就可以用这些指针而不是原来的 SHA-1 值去检索了。
在 Git 中,我们称之为“引用”(references 或者 refs,译者注)。你可以在 .git/refs 目录下面找到这些包含 SHA-1 值的文件。在这个项目里,这个目录还没不包含任何文件,但是包含这样一个简单的结构:
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/tags
$ find .git/refs -type f
$如果想要创建一个新的引用帮助你记住最后一次提交,技术上你可以这样做:
$ echo "1a410efbd13591db07496601ebc7a059dd55cfe9" > .git/refs/heads/master现在,你就可以在 Git 命令中使用你刚才创建的引用而不是 SHA-1 值:
$ git log --pretty=oneline master
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit当然,我们并不鼓励你直接修改这些引用文件。如果你确实需要更新一个引用,Git 提供
了一个安全的命令 update-ref:
$ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9基本上 Git 中的一个分支其实就是一个指向某个工作版本一条 HEAD 记录的指针或引
用。你可以用这条命令创建一个指向第二次提交的分支:
$ git update-ref refs/heads/test cac0ca这样你的分支将会只包含那次提交以及之前的工作:
$ git log --pretty=oneline test
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit现在,你的 Git 数据库应该看起来像图 9.4 一样。
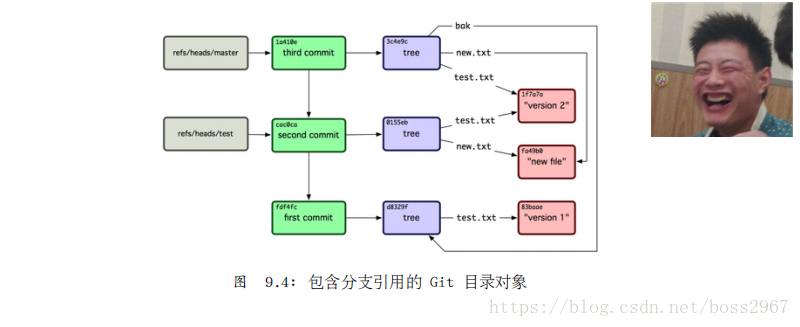
每当你执行 git branch (分支名称) 这样的命令,Git 基本上就是执行 update-ref 命令,把你现在所在分支中最后一次提交的 SHA-1 值,添加到你要创建的分支的引用。
9.3.1 HEAD 标记
现在的问题是,当你执行 git branch (分支名称) 这条命令的时候,Git 怎么知道最后一次提交的 SHA-1 值呢?答案就是 HEAD 文件。HEAD 文件是一个指向你当前所在分支的引用标识符。这样的引用标识符——它看起来并不像一个普通的引用——其实并不包含 SHA-1
值,而是一个指向另外一个引用的指针。如果你看一下这个文件,通常你将会看到这样的内容:
$ cat .git/HEAD
ref: refs/heads/master如果你执行 git checkout test,Git 就会更新这个文件,看起来像这样:
$ cat .git/HEAD
ref: refs/heads/test当你再执行 git commit 命令,它就创建了一个 commit 对象,把这个 commit 对象的父级设置为 HEAD 指向的引用的 SHA-1 值。你也可以手动编辑这个文件,但是同样有一个更安全的方法可以这样做:symbolic-ref。你可以用下面这条命令读取 HEAD 的值:
$ git symbolic-ref HEAD
refs/heads/master你也可以设置 HEAD 的值:
$ git symbolic-ref HEAD refs/heads/test
$ cat .git/HEAD
ref: refs/heads/test但是你不能设置成 refs 以外的形式:
$ git symbolic-ref HEAD test
fatal: Refusing to point HEAD outside of refs/9.3.2 Tags
你刚刚已经重温过了 Git 的三个主要对象类型,现在这是第四种。Tag 对象非常像一个commit 对象——包含一个标签,一组数据,一个消息和一个指针。最主要的区别就是 Tag对象指向一个 commit 而不是一个 tree。它就像是一个分支引用,但是不会变化——永远指向同一个 commit,仅仅是提供一个更加友好的名字。正如我们在第二章所讨论的,Tag 有两种类型:annotated 和 lightweight 。你可以类似下面这样的命令建立一个 lightweight tag:
$ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d这就是 lightweight tag 的全部 —— 一个永远不会发生变化的分支。 annotated tag要更复杂一点。如果你创建一个 annotated tag,Git 会创建一个 tag 对象,然后写入一个指向指向它而不是直接指向 commit 的 reference。你可以这样创建一个 annotatedtag(-a 参数表明这是一个 annotated tag):
$ git tag -a v1.1 1a410efbd13591db07496601ebc7a059dd55cfe9 –m 'test tag'这是所创建对象的 SHA-1 值:
$ cat .git/refs/tags/v1.1
9585191f37f7b0fb9444f35a9bf50de191beadc2现在你可以运行 cat-file 命令检查这个 SHA-1 值:
$ git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2
object 1a410efbd13591db07496601ebc7a059dd55cfe9
type commit
tag v1.1
tagger Scott Chacon <[email protected]> Sat May 23 16:48:58 2009 -0700
test tag值得注意的是这个对象指向你所标记的 commit 对象的 SHA-1 值。同时需要注意的是它并不是必须要指向一个 commit 对象;你可以标记任何 Git 对象。例如,在 Git 的源代码里,管理者添加了一个 GPG 公钥(这是一个 blob 对象)对它做了一个标签。你就可以运行:
$ git cat-file blob junio-gpg-pub来查看 Git 源代码里的公钥. Linux kernel 也有一个不是指向 commit 对象的 tag—— 第一个 tag 是在导入源代码的时候创建的,它指向初始 tree (initial tree,译者注)。
9.3.3 Remotes
你将会看到的第四种 reference 是 remote reference(远程引用,译者注)。如果你添加了一个 remote 然后推送代码过去,Git 会把你最后一次推送到这个 remote 的每个分支的值都记录在 refs/remotes 目录下。例如,你可以添加一个叫做 origin 的 remote 然后把你的 master 分支推送上去:
$ git remote add origin [email protected]:schacon/simplegit-progit.git
$ git push origin master
Counting objects: 11, done.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (7/7), 716 bytes, done.
Total 7 (delta 2), reused 4 (delta 1)
To [email protected]:schacon/simplegit-progit.git
a11bef0..ca82a6d master -> master然后查看 refs/remotes/origin/master 这个文件,你就会发现 origin remote 中的master 分支就是你最后一次和服务器的通信。
$ cat .git/refs/remotes/origin/master
ca82a6dff817ec66f44342007202690a93763949Remote 应用和分支主要区别在于他们是不能被 check out 的。Git 把他们当作是标记这些了这些分支在服务器上最后状态的一种书签。
9.4 Packfiles
我们再来看一下 test Git 仓库。目前为止,有 11 个对象 ── 4 个 blob,3 个tree,3 个 commit 以及一个 tag:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/95/85191f37f7b0fb9444f35a9bf50de191beadc2 # tag
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Git 用 zlib 压缩文件内容,因此这些文件并没有占用太多空间,所有文件加起来总共仅用了 925 字节。接下去你会添加一些大文件以演示 Git 的一个很有意思的功能。将你之前用到过的 Grit 库中的 repo.rb 文件加进去 ── 这个源代码文件大小约为 12K:
$ curl http://github.com/mojombo/grit/raw/master/lib/grit/repo.rb > repo.rb
$ git add repo.rb
$ git commit -m 'added repo.rb'
[master 484a592] added repo.rb
3 files changed, 459 insertions(+), 2 deletions(-)
delete mode 100644 bak/test.txt
create mode 100644 repo.rb
rewrite test.txt (100%)如果查看一下生成的 tree,可以看到 repo.rb 文件的 blob 对象的 SHA-1 值:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt然后可以用 git cat-file 命令查看这个对象有多大:
$ git cat-file -s 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e
12898稍微修改一下些文件,看会发生些什么:
$ echo '# testing' >> repo.rb
$ git commit -am 'modified repo a bit'
[master ab1afef] modified repo a bit
1 files changed, 1 insertions(+), 0 deletions(-)查看这个 commit 生成的 tree,可以看到一些有趣的东西:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 05408d195263d853f09dca71d55116663690c27c repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txtblob 对象与之前的已经不同了。这说明虽然只是往一个 400 行的文件最后加入了一行内容,Git 却用一个全新的对象来保存新的文件内容:
$ git cat-file -s 05408d195263d853f09dca71d55116663690c27c
12908你的磁盘上有了两个几乎完全相同的 12K 的对象。如果 Git 只完整保存其中一个,并保存另一个对象的差异内容,岂不更好?
事实上 Git 可以那样做。Git 往磁盘保存对象时默认使用的格式叫松散对象 (looseobject) 格式。Git 时不时地将这些对象打包至一个叫 packfile 的二进制文件以节省空间并提高效率。当仓库中有太多的松散对象,或是手工调用 git gc 命令,或推送至远程服务器时,Git 都会这样做。手工调用 git gc 命令让 Git 将库中对象打包并看会发生些什么:
$ git gc
Counting objects: 17, done.
Delta compression using 2 threads.
Compressing objects: 100% (13/13), done.
Writing objects: 100% (17/17), done.
Total 17 (delta 1), reused 10 (delta 0)查看一下 objects 目录,会发现大部分对象都不在了,与此同时出现了两个新文件:
$ find .git/objects -type f
.git/objects/71/08f7ecb345ee9d0084193f147cdad4d2998293
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/info/packs
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack仍保留着的几个对象是未被任何 commit 引用的 blob ── 在此例中是你之前创建的“what is up, doc?” 和 “test content” 这两个示例 blob。你从没将他们添加至任何commit,所以 Git 认为它们是 “悬空” 的,不会将它们打包进 packfile 。剩下的文件是新创建的 packfile 以及一个索引。packfile 文件包含了刚才从文件系统中移除的所有对象。索引文件包含了 packfile 的偏移信息,这样就可以快速定位任意一个指定对象。有意思的是运行 gc 命令前磁盘上的对象大小约为 12K ,而这个新生成的packfile 仅为 6K 大小。通过打包对象减少了一半磁盘使用空间。Git 是如何做到这点的?Git 打包对象时,会查找命名及尺寸相近的文件,并只保存文件不同版本之间的差异内容。可以查看一下 packfile ,观察它是如何节省空间的。gitverify-pack 命令用于显示已打包的内容:
$ git verify-pack -v \
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 5400
05408d195263d853f09dca71d55116663690c27c blob 12908 3478 874
09f01cea547666f58d6a8d809583841a7c6f0130 tree 106 107 5086
1a410efbd13591db07496601ebc7a059dd55cfe9 commit 225 151 322
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 5381
3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 101 105 5211
484a59275031909e19aadb7c92262719cfcdf19a commit 226 153 169
83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 5362
9585191f37f7b0fb9444f35a9bf50de191beadc2 tag 136 127 5476
9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e blob 7 18 5193 1
05408d195263d853f09dca71d55116663690c27c \
ab1afef80fac8e34258ff41fc1b867c702daa24b commit 232 157 12
cac0cab538b970a37ea1e769cbbde608743bc96d commit 226 154 473
d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 5316
e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4352
f8f51d7d8a1760462eca26eebafde32087499533 tree 106 107 749
fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 856
fdf4fc3344e67ab068f836878b6c4951e3b15f3d commit 177 122 627
chain length = 1: 1 object
pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack: ok如果你还记得的话, 9bc1d 这个 blob 是 repo.rb 文件的第一个版本,这个 blob 引用了 05408 这个 blob,即该文件的第二个版本。命令输出内容的第三列显示的是对象大小,可以看到 05408 占用了 12K 空间,而 9bc1d 仅为 7 字节。非常有趣的是第二个版本才是完整保存文件内容的对象,而第一个版本是以差异方式保存的 ── 这是因为大部分情况下需要快速访问文件的最新版本。最妙的是可以随时进行重新打包。Git 自动定期对仓库进行重新打包以节省空间。当然也可以手工运行 git gc 命令来这么做。
9.5 The Refspec
这本书读到这里,你已经使用过一些简单的远程分支到本地引用的映射方式了,这种映射可以更为复杂。 假设你像这样添加了一项远程仓库:
$ git remote add origin [email protected]:schacon/simplegit-progit.git