1. 问题描述
通过这一周的学习,我学习了一个特殊的系统调用fork,即进程的创建。操作系统内核实现操作系统的三大管理功能,即进程管理、内存管理和文件系统,其中,操作系统最核心的功能是进程管理。下面来具体介绍进程的描述以及进程的创建过程,并通过gdb跟踪分析进程创建过程。
2. 解决步骤
2.1 进程描述
2.1.1 进程描述符
在linux内核中有一个数据结构struct task_struct来描述进程,以下为部分代码
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped 描述进程运行状态*/
void *stack; //指定进程的内核堆栈
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
struct task_struct *last_wakee;
unsigned long wakee_flips;
unsigned long wakee_flip_decay_ts;
int wake_cpu;
#endif
int on_rq; //运行队列
int prio, static_prio, normal_prio; //定义优先级
unsigned int rt_priority;
const struct sched_class *sched_class; //进程调度相关的定义
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
struct sched_dl_entity dl;
......struct task_struct的数据结构庞大,大概有400多行代码,可以通过下图来从总体上看清struct task_struct的结构关系
2.1.2 linux进程状态
当使用fork()创建一个新的进程时,进程的状态是TASK_RUNNING(就绪态),当调度器选择这个新创建的进程运行时,新创建的进程就切换到TASK_RUNNING(运行态)。对于一个正在运行的进程,调用用户库函数exit()会陷入内核执行该内核函数do_exit(),也就是终止进程,就会进入TASK_ZOMBIE状态(僵尸进程)。一个正在运行的进程在等待特定的事件和资源时会进入阻塞态。阻塞态也分两种:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTLBLE。TASK_INTERRUPTIBLE可以被信号和wake_up唤醒的,当信号到来时,进程会被设置为TASK_RUNNING(就绪态),而TASK_UNINTERRUPTLBLE只能被wake-up()唤醒。可以将各种状态用下图表示
2.1.3 进程结构其它重要部分
进程除了状态比较重要外,还有进程的标识符PID。在进程描述符中用pid和tgid标识进程
1330 pid_t gid;
1331 pid_t tgid;用于管理进程数据结构的双向链表struct list_head_tasks是一个很关键的进程链表
1295 struct list_head tasks;struct_list_head数据结构具体内容如下所示
struct list_head{
struct list_head *next,*prev;
}内存管理的相关代码如下所示
1301 struct mm_struct *mm,*active_mm;mm和active_mm是和进程地址空间、内存管理相关的数据结构指针。每个进程都有若干个数据段、代码段、堆栈段等,它们都是由这个数据结构统领起来的。
2.1.4 进程之间的父子、兄弟关系
进程描述符struct task_struct 数据结构中如下代码记录了当前进程父进程、子进程、兄弟进程的关系。
1342 struct task_struct _rcu *real_parent; /*real parent process*/
1343 struct task_struct _rcu *parent; /*recipient of SIGCHLD,wait4() reports*/
1347 struct list_head children; /*list of my children*/
1348 struct list_head sibling; /*linkage in my parent's chlidren list*/
1349 struct task_struct *group_leader; /*threadgroup leader*/下图为进程的父子、兄弟关系的示意图。
2.1.5 保存进程上下文CPU相关的一些状态信息的数据结构
struct thread_struct是用来保存上下文中CPU相关的一些状态信息的数据结构,struct thread_struct在进程描述符中定义的结构体变量thread如下
1411 /* CPU-specific state of this task*/
1412 struct thread_struct thread;这个struct thread_struct数据结构内部的东西比较多,其中最关键的是sp和ip。在x86-32位系统中,sp用来保存进程上下文的ESP寄存器状态,ip用来保存进程上下文的EIP寄存器状态,当然数据结构中还有很多其它和CPU相关的状态。
2.2 进程的创建
2.2.1 0号进程的创建
linux内核第一个进程的初始化
510 set_task_stack_end_magic(&init_task);其中,init_task为第一个进程(0号进程)的进程描述符结构体变量,它的初始化是通过硬编码方式固定下来的。除此之外,所有其他进程的初始化都是通过do_fork复制父进程的方式初始化的。以下为init_task进程描述符的初始化代码片段
17 /* Initial task structure*/
18 struct task_struct init_task = INIT_TASK(init_task);
19 EXPORT_SYMBOL(init_task);对进程描述符的结构体变量init_task进行了初始化赋值。
2.2.2 进程创建过程分析
rest_init通过kernel_thread创建了两个内核线程:一个是kernel_init,最终把用户态的进程init给启动起来:另一个是kthreadd内核线程。kthreadd是所有内核线程的祖先,负责管理所有内核线程。这个kernel_thread创建进程的过程和shell命令行下启动一个进程时创建进程的过程在本质上是一样的,都要通过复制父进程来创建一个子进程。在系统启动时,除了0号进程的初始化过程是我们手工编码创建的之外,1号init进程的创建实际上是复制0号进程。根据1号进程的需要修改了进程pid等,然后再加载一个init可执行程序,同样地,2号kthread内核线程也是通过复制0号进程来创建的。
具体进程的创建大概就是把当前进程的描述符等相关进程资源复制一份,从而产生一个子进程,并根据子进程的需要对复制的进程描述符做一些修改,然后把创建好的子进程放入运行队列(操作系统原理中的就绪队列)。
1.用户态创建进程方法
通过以下代码,可以实现一个在用户态创建一个子进程的程序
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc,char * argv[])
{
int pid;
/*fork another process*/
pid = fork();
if(pid < 0)
{
/*error occurred*/
fprintf(stderr,"Fork Failed!");
exit(-1)
}
else if (pid == 0)
{
/*child process*/
printf("This is Child Process!\n");
}
else
{
/*parent process*/
printf("This is Child Process!\n");
}
else
{
/*parent process*/
printf("This is Parent Process!\n");
/*parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}在以上代码中,库函数fork是用户态创建一个子进程的系统调用。对于判断fork函数的返回值,在fork正常执行后,if条件判断中除了if(pid < 0)异常处理没被执行,else if(pid == 0)和else两段代码都被执行了。这是因为在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
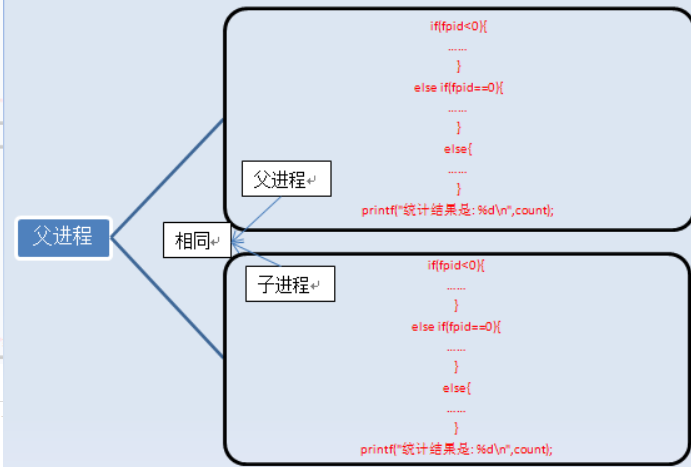
通过这一段fork代码程序,我们可以在用户态创建一个子进程。一个进程就是一条系统调用fork,只要追踪这个fork系统调用,就能进一步分析进程创建的过程。
2. 进程创建的主要过程
linux与创建进程相关的3个系统调用fork、vfork和clone以及kernel_thread内核函数都可以创建一个新进程,而且都是通过do_fork函数创建进程的,只不过传递的参数不同。fork,创建子进程 vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。 clone,主要用于创建线程。
创建一个进程是复制当前进程的信息,就是fork一个进程,这样就创建了一个新进程。因为父进程和子进程绝大部分信息是完全一样的,但是有些信息是不一样的,比如pid的值和内核堆栈。父进程创建一个子进程,应该会有一个地方复制了父进程的进程描述符task_struct结构体变量,并有很多地方来修改复制出来的进程描述符task_struct结构体变量,而fork系统调用在父子进程中分别返回到用户态,父子进程的内核堆栈中可能某些信息也不完全一样。还有thread,根据子进程复制的父进程的内核堆栈的状况,肯定要设定好EIP和ESP寄存器,即设定好子进程开始执行的位置。
需要特别说明的是,fork一个子进程的过程中,复制父进程的资源时采用了Copy On Write(写时复制)技术,不需要修改进程资源,父子进程是共享内存存储空间的。
下面就这个进程创建的框架来分析几个重点的进程创建过程中调用的函数。
(1). do_fork函数
简化代码如下
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p; //创建进程描述符指针
int trace = 0;
long nr; //子进程pid
...
// 复制进程描述符,返回创建的task_struct的指针
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
if (!IS_ERR(p)) { //如果copy_process执行成功
struct completion vfork; //定义完成量(一个执行单元等待另一个执行单元完成某事
struct pid *pid;
trace_sched_process_fork(current, p);
// 取出task结构体内的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
// 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
// 将子进程添加到调度器的队列,使得子进程有机会获得CPU
wake_up_new_task(p);
// ...
// 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间
// 保证子进程优先于父进程运行
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p); //错误处理
}
return nr; //返回子进程pid(父进程的fork函数返回的值为子进程pid的原因)
}下面是do_fork的参数
- clone_flags:子进程创建相关标志,通过此标志可以对父进程的资源进行有效的复制。
- stack_start:子进程用户堆栈的地址。
- regs:指向pt_regs结构体的指针。当系统发生系统调用时,int指令和SAVE_ALL保存现场等会将CPU寄存器中的值按顺序压入内核栈。为了便于访问操作,这部分数据被定义为pt_regs结构体。
- stack_size:用户态栈的大小,通常是不必要的,总被设置为0。
parent_tidptr和child_tidptr:父进程,子进程用户态下的pid地址。
do_fork()主要完成了调用copy_process()复制父进程信息、获得pid、调用wake_up_new_task将子进程加入调度器队列等待获得分配CPU资源运行、通过clone_flags标志做一些辅助工作,其中copy_process()是创建一个进程内容的主要的代码。(2). copy_process
代码如下
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
retval = security_task_create(clone_flags); //安全性检查
if (retval)
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current); //复制PCB,为子进程创建内核栈,进程描述符
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
//检查该用户进程数是否超过max_threads,后者取决于内存的大小
if (atomic_read(&p->real_cred->user->processes) >=
p->signal->rlim[RLIMIT_NPROC].rlim_cur) {
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) &&
p->real_cred->user != INIT_USER)
goto bad_fork_free;
}
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p);
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock); //初始化自旋锁
init_sigpending(&p->pending); //初始化挂起信号
p->utime = cputime_zero;
p->stime = cputime_zero;
p->gtime = cputime_zero;
p->utimescaled = cputime_zero;
p->stimescaled = cputime_zero;
p->prev_utime = cputime_zero;
p->prev_stime = cputime_zero;
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p); //初始化CPU定时器
p->lock_depth = -1; /* -1 = no lock */
do_posix_clock_monotonic_gettime(&p->start_time);
p->real_start_time = p->start_time;
monotonic_to_bootbased(&p->real_start_time);
p->io_context = NULL;
p->audit_context = NULL;
cgroup_fork(p);
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_cgroup;
}
mpol_fix_fork_child_flag(p);
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
#ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW
p->hardirqs_enabled = 1;
#else
p->hardirqs_enabled = 0;
#endif
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet */
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
p->bts = NULL;
/* Perform scheduler related setup. Assign this task to a CPU. */
sched_fork(p, clone_flags); //初始化新进程调度程序数据结构,把新进程的状态设置为TASK_RUNNING,并禁止内核抢占
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
if ((retval = audit_alloc(p)))
goto bad_fork_cleanup_policy;
/* copy all the process information */
if ((retval = copy_semundo(clone_flags, p)))
goto bad_fork_cleanup_audit;
if ((retval = copy_files(clone_flags, p)))
goto bad_fork_cleanup_semundo;
if ((retval = copy_fs(clone_flags, p)))
goto bad_fork_cleanup_files;
if ((retval = copy_sighand(clone_flags, p)))
goto bad_fork_cleanup_fs;
if ((retval = copy_signal(clone_flags, p)))
goto bad_fork_cleanup_sighand;
if ((retval = copy_mm(clone_flags, p)))
goto bad_fork_cleanup_signal;
if ((retval = copy_namespaces(clone_flags, p)))
goto bad_fork_cleanup_mm;
if ((retval = copy_io(clone_flags, p)))
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
if (clone_flags & CLONE_NEWPID) {
retval = pid_ns_prepare_proc(p->nsproxy->pid_ns);
if (retval < 0)
goto bad_fork_free_pid;
}
}
p->pid = pid_nr(pid); //根据结构体中获得进程pid
p->tgid = p->pid; //组号tgid是它自己的pid
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid; //子进程继承父进程的tgid
if (current->nsproxy != p->nsproxy) {
retval = ns_cgroup_clone(p, pid);
if (retval)
goto bad_fork_free_pid;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ?child_tidptr: NULL;
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing should be turned off in the child regardless
* of CLONE_PTRACE.
*/
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
/*
* Ok, make it visible to the rest of the system.
* We dont wake it up yet.
*/
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
/* Now that the task is set up, run cgroup callbacks if
* necessary. We need to run them before the task is visible
* on the tasklist. */
cgroup_fork_callbacks(p);
cgroup_callbacks_done = 1;
/* Need tasklist lock for parent etc handling! */
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
//若 clone_flags包含CLONE_THREAD标志,说明子进程和父进程在同一个线程组
if (clone_flags & CLONE_THREAD) {
atomic_inc(¤t->signal->count);
atomic_inc(¤t->signal->live);
//将线程组的leader设为子进程的组leader
p->group_leader = current->group_leader;
list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
}
if (likely(p->pid)) {
list_add_tail(&p->sibling, &p->real_parent->children);
tracehook_finish_clone(p, clone_flags, trace);
if (thread_group_leader(p)) {
if (clone_flags & CLONE_NEWPID)
p->nsproxy->pid_ns->child_reaper = p;
p->signal->leader_pid = pid;
tty_kref_put(p->signal->tty);
p->signal->tty = tty_kref_get(current->signal->tty);
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__get_cpu_var(process_counts)++;
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
perf_event_fork(p);
return p;
bad_fork_free_pid:
//若传进来的pid指针和全局结构体变量init_struct_pid的地址不相同,就要为子进程分配新的pid
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
put_io_context(p->io_context);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
__cleanup_signal(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_cgroup:
#endif
cgroup_exit(p, cgroup_callbacks_done);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
}copy_process函数主要完成了调用dup_task_struct复制当前进程(父进程)描述符task_struct、信息检查、初始化、把进程状态设置为TASK_RUNNING(此时子进程置为就绪态)、采用写时复制技术逐一复制所有其他进程资源、调用copy_thread初始化子进程内核栈、设置子进程pid等。其中最关键的就是dup_task_struct复制当前进程(父进程)描述符task_struct和copy_thread初始化子进程内核栈。
(3). dup_task_struct
简化代码如下
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
int node = tsk_fork_get_node(orig);
int err;
tsk = alloc_task_struct_node(node); //为子进程创建进程描述符分配存储空间
...
ti = alloc_thread_info_node(tsk,node); //实际上创建了两个页,一部分用来存放thread_info,另一部分就是内核堆栈
...
err = arch_dup_task_struct(tsk,orig); //复制父进程的task_struct信息
tsk->stack = ti; // 将栈底的值赋给新结点的stack
//对子进程的thread_info结构进行初始化(复制父进程的thread_info结构,然后将task指针指向子进程的进程描述符)
setup_thread_stack(tsk,org);
...
return tsk;
...
}thread_info结构被称为小型的进程描述符,内存区域大小为8KB,占据两个连续的页框。该结构通过task指针指向进程描述符。
(4). copy_thread
上述dup_task_struct函数为子进程分配好了内核栈,copy_thread才能真正完成内核栈关键信息的初始化。代码如下
int copy_thread(unisgned long clone_flags,unsigned long sp,unsigned long arg,sturct task_struct *p)
{
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs + 1);
memset(p->thread.ptrace_bps,0,sizeof(p->thread.ptrace_bps));
if(unlikely(p->flags & PE_KTHREAD) {
/*kernel thread*/
meset(childregs,0,sizeof(struct pt_regs));
//如果创建的是内核线程,则从ret_from_kernel_thread开始执行
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = _KERNEL_STACK_CANARY;
childregs->ds = _USER_DS;
childregs->es = _USER_DS;
childregs->fs = _KERNEL_PERCPU;
childregs->bx = sp; /*function*/
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = _KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
//复制内核堆栈(复制父进程的寄存器信息,即系统调用int指令和SAVE_ALL压栈的那一部分内容)
*childregs = *current_pt_regs();
childregs->ax = 0;
...
//ip指向ret_from_frok,子进程从此处开始执行
p->thread.ip = (unsigned long) ret_from_fork;
task_user_gs(p) = get_user_gs(current_pt_regs());
...
return err;
}如上代码对子进程开始执行的起点ret_from_kernel_thread(内核线程)或ret_from_fork(用户态进程),以及在子进程中fork系统调用的返回值等都给予了注释说明。
总的来说,进程的创建过程大致是复制进程描述符、一一复制其他进程资源(采用写时复制技术)、分配子进程的内核堆栈并对内核堆栈关键信息进行初始化。
2.3 使用gdb跟踪分析进程的创建过程
这里使用的是实验楼下的linux环境,删除menu,然后克隆一份新的,还要把test.c覆盖掉(上周用过test.c)。
可以看到test.c中增加了fork函数
使用如下代码进入gdb调试分析,并设置断点
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -S -s
gdb
file linux-3.18.6/vmlinux
target remote:1234
c设置断点然后执行fork
调用函数sys_clone
使用命令s单步调试,到下一个断点调用do_fork函数
调用copy_process函数
调用dup_task_struct函数
调用copy_thread函数
调用ret_from_fork函数
综上所述,设定完断点后执行fork,发现只输出了一个命令描述,后面没有执行,而是停在了sys_clone这里。如果继续执行,会停在do_fork的位置,从do_fork继续执行,停在copy_process,继续执行,停在dup_task_struct函数。进入dup_task_struct函数内部,将当前进程内核堆栈压的那一部分寄存器复制到子进程中,以及赋值子进程的起点,最后运行到ret_from_fork。
3. 总结
通过这一周的学习,我初步了解了在用户态中创建一个子进程的具体过程,通过对进程创建过程的分析,对linux内核的工作机制有了更进一步的了解。