注:本文=多篇文章精华提炼+个人总结
参考博客出处:
链接:https://blog.csdn.net/l7H9JA4/article/details/80220939
作者:李雪冬 编辑:李雪冬
https://blog.csdn.net/qq_42988748/article/details/82657562
http://blog.chinaunix.net/uid-20395453-id-5775658.html
DTM参考
https://blog.csdn.net/l7h9ja4/article/details/80220939
https://blog.csdn.net/sinat_26917383/article/details/79377761
https://blog.csdn.net/weixin_38341450/article/details/90738928
——————————————————————————————
一、简介
gensim
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。 它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法。支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
语料(Corpus):一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。corpus的每一个元素对应一篇文档。
向量(Vector):由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
稀疏向量(SparseVector):通常,我们可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(key, value)的元组
模型(Model):是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
——————————————————————————————————————————————————————
TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
1. 一个词预测主题能力越强,权重就越大,反之,权重就越小。我们在网页中看到“原子能”这个词,或多或少地能了解网页的主题。我们看到“应用”一次,对主题基本上还是一无所知。因此,“原子能“的权重就应该比应用大。
2. 应删除词的权重应该是零。
—————————————————————————————————————————————————————
DTM
主要摘自https://blog.csdn.net/sinat_26917383/article/details/79377761
1.简介
https://blog.csdn.net/gdkyxy2013/article/details/85156547
对于许多集合,文档的顺序反映了一组不断变化的主题。 在动态主题模型中,我们假设数据按时间片划分,例如按年。 我们使用K分量主题模型对每个切片的文档建模,其中与切片t相关联的主题从与切片t-1相关联的主题演变而来。

在本文中,我们介绍一个动态主题模型,该模型捕获了顺序组织的文档语料库中主题的演变。 我们通过分析由Ed Edi-son于1880年创立的Jour-nal Science的100多年的OCR文章来证明其适用性。在这种模式下,文章按年份分组,每年的艺术作品都来自于去年主题演变而来的一系列主题。
在随后的部分,我们扩展了经典状态空间模型,以指定主题演化的统计模型。然后,我们开发了有效的近似后验推理技术,用于从一系列文档中确定不断变化的主题。最后,我们提供了定性结果,展示了动态主题模型如何以新的方式探索大型文档集合,以及定量结果,与静态主题模型相比,它们具有更高的预测准确性(存疑)。
一、Dynamic Topic Models
传统的时间序列建模主要关注连续数据,而主题模型则是针对分类数据而设计的。 我们的方法是在底层主题多项式的自然参数空间上使用状态空间模型,以及用于对文档特定主题比例建模的逻辑正态分布的自然参数。
首先,我们回顾静态主题模型的基本统计假设,例如潜在狄利克雷分配,也叫三层贝叶斯概率模型(LDA,Latent Dirichlet Allocation)。设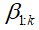 为K个主题,每个主题都是固定词汇表的分布。 在静态主题模型中,假设每个文档都来自以下生成过程:
为K个主题,每个主题都是固定词汇表的分布。 在静态主题模型中,假设每个文档都来自以下生成过程:

此过程隐含地假定文档是从同一组主题交换绘制的。然而,对于许多集合,文档的顺序反映了一组不断变化的主题。 在动态主题模型中,我们假设数据按时间片划分,例如按年。 我们使用K分量主题模型对每个切片的文档建模,其中与切片t相关联的主题从与切片t-1相关联的主题演变而来。
对于具有V项的K分量模型,令![]() 表示切片t中主题k的自然参数的V向量。 多项分布的通常表示是通过其均值参数化。 如果我们用π表示V维多项式的平均参数,则自然参数的第i个分量由映射
表示切片t中主题k的自然参数的V向量。 多项分布的通常表示是通过其均值参数化。 如果我们用π表示V维多项式的平均参数,则自然参数的第i个分量由映射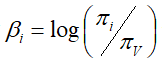 给出。在典型的语言建模应用中,Dirichlet分布用于模拟关于字的分布的不确定性。 但是,Dirichlet不适合顺序建模。相反,我们在一个随高斯噪声演化的状态空间模型中链接每个主题
给出。在典型的语言建模应用中,Dirichlet分布用于模拟关于字的分布的不确定性。 但是,Dirichlet不适合顺序建模。相反,我们在一个随高斯噪声演化的状态空间模型中链接每个主题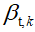 的自然参数,这种模型最简单的版本是:
的自然参数,这种模型最简单的版本是:
因此,我们的方法是通过在动态模型中链接高斯分布并将发射值映射到单纯形simplex来对组成随机变量的序列进行建模。这是正态分布对时间序列单纯形数据的扩展。
在LDA中,文档特定主题比例θ来自Dirichlet分布。 在动态主题模型中,我们使用具有平均值α的逻辑法线来表示比例的不确定性。 使用简单的动态模型再次捕获模型之间的顺序结构: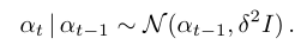
通过将主题和主题比例分布链接在一起,我们按顺序绑定了一组主题模型。 因此,序列语料库的生成过程如下:

请注意,π将多项自然参数映射到平均参数:
这个生成过程的图形模型如下图所示。当水平箭头被移除时,打破时间动态,图形模型简化为一组独立的主题模型。 利用时间动态,切片t处的第k个主题从切片t-1处的第k个主题平滑演化。

动态主题模型的图形表示(用于三个时间片)。 每个主题的自然参数随着时间演变,以及主题比例的逻辑正态分布的平均参数。
二、近似推理
使用自然参数的时间序列可以使用高斯模型来计算时间动态; 然而,由于高斯和多项式模型的非共轭性,后验推断是难以处理的。 于是,我们提出了一种近似后推理的变分方法。 我们使用变分方法作为随机模拟的确定性替代方法,以处理典型的文本分析的大数据集。 虽然Gibbs采样已经有效地用于静态主题模型,但非共轭性使得采样方法对于这种动态模型更加困难。
变分方法背后的思想是优化潜在变量上的分布的自由参数,使得分布在Kullback-Liebler(KL)发散到真实后验时接近; 然后,这种分布可以用作真正后验的替代。在动态主题模型中,潜在变量是主题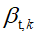 ,混合比例
,混合比例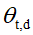 和主题指标
和主题指标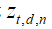 。变分分布反映了潜在变量的群体结构。每个主题的多项参数序列都有变化参数,每个文档级潜在变量都有变化参数。 近似变分后验是:
。变分分布反映了潜在变量的群体结构。每个主题的多项参数序列都有变化参数,每个文档级潜在变量都有变化参数。 近似变分后验是:
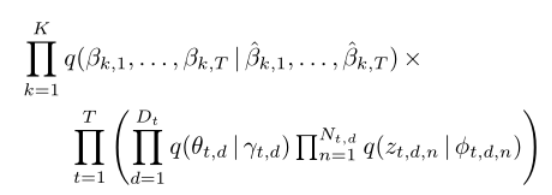
在常用的平均场近似中,每个潜在变量被认为独立于其他潜变量。 然而,在 的变分分布中,我们通过设置具有高斯“变分观测值”
的变分分布中,我们通过设置具有高斯“变分观测值”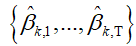 的动态模型来保留主题的顺序结构。 这些参数适合于最小化得到的后验(即高斯)和真实后验(非高斯)之间的KL发散。
的动态模型来保留主题的顺序结构。 这些参数适合于最小化得到的后验(即高斯)和真实后验(非高斯)之间的KL发散。
文档级潜变量的变分分布遵循与Blei等人相同的形式。 每个比例向量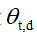 被赋予自由度Dirichlet参数
被赋予自由度Dirichlet参数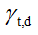 ,每个主题指示符
,每个主题指示符 被赋予自由多项式参数
被赋予自由多项式参数 ,并且优化通过坐标上升进行。文档级变分参数的更新具有封闭形式; 我们使用共轭梯度法来优化主题级变分观测。由此得到的自然主题参数
,并且优化通过坐标上升进行。文档级变分参数的更新具有封闭形式; 我们使用共轭梯度法来优化主题级变分观测。由此得到的自然主题参数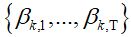 的变分近似结合了时间动态; 我们描述了两种方法,一种基于卡尔曼滤波器的近似,另一种是基于小波回归。
的变分近似结合了时间动态; 我们描述了两种方法,一种基于卡尔曼滤波器的近似,另一种是基于小波回归。
2.1 Variational Kalman Filtering(变分卡尔曼滤波器)
变分参数作为输出的视图基于高斯密度的对称性,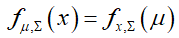 这使得能够使用线性状态空间模型的标准前向-后向计算。 图形模型及其变分近似如下图所示。这里三角形表示变分参数; 它们可以被认为是卡尔曼滤波器的“假设输出”,以便于计算。第一幅图的时间序列主题模型的变分近似的图形表示。变分参数β和α被认为是卡尔曼滤波器的输出,或者是非参数回归设置中的观测数据。
这使得能够使用线性状态空间模型的标准前向-后向计算。 图形模型及其变分近似如下图所示。这里三角形表示变分参数; 它们可以被认为是卡尔曼滤波器的“假设输出”,以便于计算。第一幅图的时间序列主题模型的变分近似的图形表示。变分参数β和α被认为是卡尔曼滤波器的输出,或者是非参数回归设置中的观测数据。

为了在更简单的设置中解释这种技术背后的主要思想,考虑unigram模型 (在自然参数化中)随时间演变的模型。 在该模型中没有主题,因此没有混合参数。 计算是我们对更一般的潜变量模型所需的那些更简单的版本,但展示了基本特征。状态空间模型是:
(在自然参数化中)随时间演变的模型。 在该模型中没有主题,因此没有混合参数。 计算是我们对更一般的潜变量模型所需的那些更简单的版本,但展示了基本特征。状态空间模型是:

我们形成变分状态空间模型:
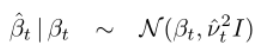
变分参数是和。使用标准卡尔曼滤波器计算(Kalman,1960),变分后验的前向均值和方差由下式给出:

初始条件由固定的和指定。然后,后向递归计算给定的的边际均值和方差:

初始条件为且。我们使用状态空间后验来近似后验。从Jensen的不等式来看,对数似然从下面被限制为:

2.2 Variational Wavelet Regression(变分小波回归)
变分卡尔曼滤波器可以用变分小波回归代替。 我们重新调整时间,使其在0和1之间。对于128年的科学,我们采用 。为了与我们之前的符号一致,我们假设:
。为了与我们之前的符号一致,我们假设:

我们的变分小波回归算法估计 ,我们将其视为观测数据,就像在卡尔曼滤波器方法中一样,以及噪声水平ν。
,我们将其视为观测数据,就像在卡尔曼滤波器方法中一样,以及噪声水平ν。
为了具体,我们使用Haar小波基来说明该技术; Daubechies小波在我们的实际例子中使用。 然后是模型:

我们对后验均值的变分估计变为:
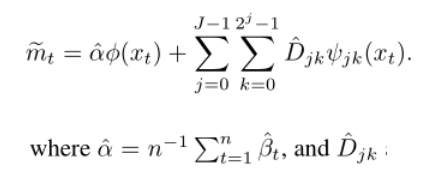
通过对系数进行阈值处理得到:
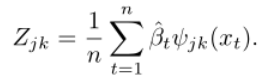
为了估计 ,我们使用梯度上升,对于卡尔曼滤波器近似,需要导数
,我们使用梯度上升,对于卡尔曼滤波器近似,需要导数 。如果使用软阈值,那么我们就有了:
。如果使用软阈值,那么我们就有了:

另请注意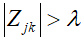 当且仅当
当且仅当 这些衍生物可以使用现成的软件在任何标准小波基中进行小波变换计算。
这些衍生物可以使用现成的软件在任何标准小波基中进行小波变换计算。
下图中给出了运行此算法和卡尔曼变分算法以逼近单字母模型的样本结果。两个变分近似消除了单字组计数中的局部波动,同时保留了可能表明期刊内容发生重大变化的尖峰。 虽然拟合类似于使用标准小波回归到(正常化)计数所获得的拟合,但是通过最小化KL分歧来获得估计,如在标准变分近似中那样。

图形解释:卡尔曼滤波器(上)和小波回归(下)变分近似与单字母模型的比较。 变分近似(红色和蓝色曲线)平滑了所示单词的单字组计数(灰色曲线)中的局部波动,同时保留了可能表明日志中内容发生重大变化的尖峰。 小波回归能够“解析”20世纪20年代爱因斯坦出现的双峰值。
三、科学的分析
我们分析了来自Science的30,000篇文章的子集,来自1881年至1999年的120年中的250篇。我们的数据由JSTOR(www.jstor.org)收集,JSTOR是一个非营利组织,维护着一个在线学术档案库。 通过在原始印刷期刊上运行光学字符识别(OCR)引擎。 JSTOR对生成的文本进行索引,并通过关键字搜索提供对原始内容的扫描图像的在线访问。
我们的语料库由大约750万个单词组成。 我们通过将每个术语插入其根,删除函数术语以及删除少于25次的术语来修剪词汇表。 总词汇量为15,955。 为了探索语料库及其主题,我们估计了一个20分量的动态主题模型。 在1.5GHZ PowerPC Macintosh笔记本电脑上进行后推理约需4小时。 结果中的两个主题如图4所示,根据使用卡尔曼滤波器变分近似估计的后验平均出现次数,显示每十年中这些主题的前几个单词,还示出了几十年来展示这些主题的示例文章。 如下图所示,该模型捕获不同的科学主题,并可用于检查其中的单词使用趋势。

图形解释:来自Science corpus估计的20主题动态模型的后验分析的例子。 对于两个主题,我们说明:(a)十年滞后推断的后验分布中的前十个词(b)来自同一两个主题的几个单词的年度函数的频率的后验估计(c)示例文章 整个集合展示了这些主题。 请注意,绘图是为了给出单词“后验概率”轨迹形状的概念。
为了定量验证动态主题模型,我们考虑了前几年所有文章预测下一年的科学任务。 我们比较了三个20个主题模型的预测能力:从前几年估计的动态主题模型,从前几年估计的静态主题模型,以及从单个前一年估计的静态主题模型。 估计所有模型具有相同的收敛标准。 从所有先前数据和动态主题模型估计的主题模型在同一点初始化。
动态主题模型表现良好; 与其他两个模型相比,它总是为下一年的文章指定更高的可能性,如下图所示。 有趣的是,多年来每种模型的预测能力都在下降。 我们可以暂时将其归因于科学语言专业化率的提高。

图形解释:该图说明了使用动态主题模型和静态主题模型进行预测的性能。 对于1900年到2000年之间的每年(以5年为增量),我们估计了那一年的三个模型。 然后,我们计算了在得到的模型下明年文章的负对数可能性的变分界限(较低的数字更好)。 DTM是动态主题模型; LDA-prev是仅在前一年的文章中估计的静态主题模型; LDA-all是所有先前文章中估计的静态主题模型。
【文章翻译自外国友人论文】
————————————————
版权声明:本文为CSDN博主「象在舞」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gdkyxy2013/article/details/85156547
2.Python实现(网)

| 函数或模型 | 作用 |
|---|---|
| print_topics | 不同时期的5个主题的情况 |
| print_topic_times | 每个主题的3个时期,主题重要词分别是什么 |
| doc_topics | 不同文档主题偏好(常规),跟LDA中get_document_topics 一致,返回内容如下:[ 5.46298825e-05 2.18468637e-01 5.46298825e-05 5.46298825e-05 7.81367474e-01] 下文称为主题偏好向量 |
| model[]新文档预测 | ldaseq[dictionary.doc2bow( [‘economy’, ‘bank’, ‘mobile’, ‘phone’, ‘markets’, ‘buy’, ‘football’, ‘united’, ‘giggs’])],返回内容:[ 0.00110497 0.00110497 0.00110497 0.00110497 0.99558011] |
| print_topics,跨时间+主题属性的文档相似性 | hellinger(doc_football_1, doc_football_2),返回的是:0.95828252517231205 |
所需材料
https://blog.csdn.net/sinat_26917383/article/details/79377761
3.Python实现(网+自己)
#基于gensim的预处理:https://blog.csdn.net/l7h9ja4/article/details/80220939
# -*- coding:utf-8 -*-
from gensim.test.utils import common_corpus, common_dictionary
from gensim.models.wrappers import DtmModel
from gensim.models.wrappers.dtmmodel import DtmModel
from gensim.corpora import Dictionary, bleicorpus
from gensim.models import ldaseqmodel
from gensim.corpora import Dictionary, bleicorpus
from gensim.matutils import hellinger
'''
#语料的预处理(以列表形式读取文件)
file=open('small预处理后.txt','r',encoding='UTF-8')
texts=[]
for ln in file:
texts.extend(ln.strip().split('aaa'))
print(type(texts))
'''
texts=[['cambodia','august','program','mekong','region','improv','mechan','inform','share','challeng','sustain','mekong','region','key','meet','mekong','river','commiss','group','strategi','region','develop','one','river','mekong','region','intergovernment','cooper','improv','among','water','mekong','river','basin','mrc','first','meet','pleas','first','bring','togeth','mekong','region','discuss','work','togeth','serv','peopl','govern','said','mr','meet','cambodia','nation','mekong','meet','cambodia','togeth','senior','repres','mekong','countri','mekong','region','cooper','repres','discuss','current','project','program','water','energi','support','mekong','discuss','dr','pich','hatda','mrc','secretariat','mechan','joint','repres','secretariat','mekong','cooper','program','cooper','strategi','cooper','cooper','lower','mekong','initi','cooper','bring','discuss','agre','continu','dialogu','repres','meet','mrc','group','strategi','partnership','also','agre','work','strateg','joint','technic','work','area','includ','water','dialogu','joint','drought','mrc','transboundari','sustain','nation','system','joint','inform','share','notif','cooper','project','water','knowledg','share','program','continu','flood','drought','cooper','mrc','group','strategi','partnership','senior','repres','member','countri','ministri','cooper','key','repres','mrc','partner','group','provid','strateg','transboundari','water','manag','issu','manag','bodi','mrc','joint','committe','mrc','strateg','plan','strategi','strateg','cooper','partnership','commiss','partnership','cooper','includ','joint','inform','share','mechan','region','initi','strengthen','mrc','role','group','strategi','partnership','togeth','group','establish','mrc','joint','committe','commiss','committe','bodi','work','group','program','editorsth','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','china','myanmar','dialogu','partner','mrc','end','inform','pleas','contactmr','sopheak','meascommun','offic','pressmekong','river','commiss','secretariatvientian','lao','pdre','sopheakmrcmekongorgp','ext','vientian','lao','pdr','august','water','jinghong','hydropow','station','china','provinc','decreas','five','accord','offici','notif','china','ministri','water','resourc','mekong','river','commiss','secretariat','notif','ministri','said','amount','water','jinghong','start','decreas','meter','ms','ms','august','decreas','made','notif','said','jinghong','part','mekong','river','mrc','monitor','water','level','mekong','river','increas','rainfal','start','water','level','lower','mekong','basin','averag','increas','meter','sinc','august','reach','longterm','averag','lao','pdr','thailand','chiang','water','averag','water','flow','jinghong','station','lower','basin','expect','chiang','jinghong','would','see','water','level','decreas','august','lao','pdr','decreas','would','rainfal','also','forecast','august','expect','part','lower','mekong','basin','area','mekong','cambodia','viet','nam','accord','rainfal','forecast','nation','flood','system','state','expect','rainfal','amount','basin','period','august','would','contribut','mekong','water','said','dr','river','forecast','mrc','sustain','decreas','water','flow','made','mekong','river','one','water','level','drought','drought','year','drought','peopl','cambodia','water','provinc','countri','water','may','govern','thailand','provinc','water','viet','nam','reach','inform','water','level','mekong','mainstream','editorsth','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','china','myanmar','dialogu','partner','mrc','end','inform','pleas','contactmr','sopheak','meascommun','offic','pressmekong','river','commiss','secretariatvientian','lao','pdre','sopheakmrcmekongorgp','ext','china','juli','peopl','china','agre','continu','share','hydrolog','data','mekong','river','commiss','contribut','better','river','monitor','flood','forecast','mekong','reach','china','mrc','agre','renew','agreement','hydrolog','inform','flood','season','mrc','secretariat','ceo','dr','pich','hatda','level','china','ministri','water','resourc','dr','agreement','china','juli','offici','part','ceo','offici','ceo','also','senior','offici','ministri','cooper','mrc','benefit','hydrolog','inform','flood','season','flood','manag','mekong','river','dr','year','five','flood','season','june','china','share','mrc','rainfal','data','two','hydrolog','station','mekong','mainstream','data','provid','china','mrc','member','countri','cambodia','lao','pdr','thailand','viet','nam','strengthen','river','monitor','improv','flood','forecast','well','renew','cooper','china','agre','period','hydrolog','data','share','share','five','start','june','mrc','dialogu','partner','sinc','also','agre','share','inform','water','level','inform','flood','lower','reach','agreement','china','mrc','cooper','china','mrc','also','continu','increas','cooper','dr','hatda','inform','also','mrc','better','role','provid','flood','drought','improv','understand','mekong','river','basin','cooper','mrc','china','first','agreement','data','share','renew','mrc','china','cooper','china','five','member','countri','mekong','cooper','lmc','also','agre','mrc','secretariat','meet','lmc','joint','work','group','water','resourc','one','joint','work','group','lmc','mechan','lmc','countri','work','water','made','mr','china','ministri','water','resourc','meet','ceo','hatda','joint','work','group','mrc','secretariat','would','establish','group','inform','share','support','work','mrc','china','mrc','secretariat','agre','work','togeth','china','mrc','water','countri','lmc','water','meet','would','mrc','discuss','share','strengthen','cooper','among','countri','mrc','lmc','peopl','countri','also','mrc','secretariat','contribut','mrc','basin','develop','strategi','cooper','plan','joint','effort','address','nation','region','challeng','mrc','china','cooper','includ','dialogu','meet','data','inform','share','joint','technic','water','resourc','develop','flood','drought','hydropow','editorsth','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','china','myanmar','dialogu','partner','mrc','end','inform','pleas','contactmr','sopheak','meascommun','offic','pressmekong','river','commiss','secretariatvientian','lao','pdre','sopheakmrcmekongorgp','ext','vientian','lao','pdr','juli','mekong','water','level','flood','season','june','juli','among','longterm','level','expect','better','end','reach','lower','mekong','basin','thailand','chiang','lao','pdr','vientian','thailand','cambodia','water','level','year','flow','current','water','level','chiang','meter','lower','longterm','averag','averag','water','level','year','period','lower','level','june','juli','year','also','vientian','water','longterm','averag','period','lower','level','june','juli','water','longterm','averag','level','june','juli','sustain','decreas','water','level','june','juli','season','flow','period','water','increas','accord','mekong','river','commiss','mrc','inform','key','contribut','current','state','region','flow','mekong','river','rainfal','mekong','basin','sinc','year','reach','lower','mekong','basin','chiang','rainfal','june','area','june','averag','rainfal','amount','rainfal','june','averag','lower','mekong','basin','also','region','contribut','mekong','amount','water','flow','part','basin','mekong','also','contribut','flow','accord','notif','china','start','juli','amount','water','flow','jinghong','provinc','would','meter','ms','ms','expect','juli','part','region','thailand','lao','pdr','myanmar','countri','would','accord','current','state','lower','water','basin','improv','end','may','develop','part','region','mekong','includ','lower','mekong','countri','inform','water','level','mekong','mainstream','editorsth','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','china','myanmar','dialogu','partner','mrc','end','inform','pleas','contactmr','sopheak','meascommun','offic','pressmekong','river','commiss','secretariatvientian','lao','pdre','sopheakmrcmekongorgp','ext','vientian','lao','pdr','juli','water','jinghong','hydropow','station','china','provinc','juli','accord','offici','notif','china','ministri','water','resourc','mekong','river','commiss','secretariat','forecast','season','start','notif','ministri','said','juli','amount','water','flow','jinghong','station','start','decreas','meter','ms','period','juli','amount','water','flow','ms','ms','water','flow','increas','juli','ms','water','flow','made','jinghong','hydropow','station','notif','said','jinghong','part','mekong','river','china','pich','hatda','mrc','secretariat','offic','said','secretariat','notif','china','countri','mekong','mainstream','accord','mrc','forecast','water','level','station','mekong','mainstream','lao','pdr','thailand','would','decreas','water','level','water','flow','thailand','chiang','may','see','meter','water','level','decreas','juli','water','flow','juli','water','level','vientian','lao','pdr','thailand','see','decreas','water','level','thailand','cambodia','increas','meter','juli','rainfal','forecast','lower','part','lower','mekong','season','start','sinc','june','bring','rainfal','lower','mekong','basin','water','jinghong','station','lower','reach','hydrolog','contribut','water','china','mekong','mainstream','season','june','water','lower','mekong','basin','rainfal','editorsth','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','china','myanmar','dialogu','partner','mrc','end','inform','pleas','contactmr','sopheak','meascommun','offic','pressmekong','river','commiss','secretariatvientian','lao','pdre','sopheakmrcmekongorgp','ext','aaa','vientian','lao','pdr','june','develop','partner','mekong','river','commiss','mrc','work','first','key','area','commiss','strateg','donor','group','current','australia','state','mrc','inform','develop','partner','meet','lao','pdr','develop','partner','pleas','see','achiev','made','mrc','mrc','develop','partner','group','mr','also','lao','pdr','said','meet','peopl','joint','donor','group','mrc','secretariat','member','countri','hydropow','project','joint','also','govern','lao','joint','plan','hydropow','project','donor','also','effort','made','mrc','group','implement','key','mrc','group','encourag','mrc','partnership','support','member','countri','nation','level','includ','organ','mrc','govern','technic','develop','partner','effort','mrc','member','countri','implement','nation','program','encourag','member','nation','region','plan','group','mrc','sustain','hydropow','develop','strategi','nation','region','base','benefit','peopl','mekong','river','donor','also','secretariat','effort','data','inform','system','mrc','encourag','mrc','improv','data','inform','nation','region','intergovernment','climat','chang','mekong','river','basin','among','region','climat','chang','donor','group','mrc','basin','develop','strategi','strateg','plan','nation','group','also','encourag','mrc','continu','effort','mainstream','role','achiev','sustain','develop','encourag','mrc','develop','basin','strategi','achiev','mrc','mekong','river','mrc','member','countri','donor','encourag','develop','partner','would','see','sustain','mekong','river','basin','peopl','address','mrc','joint','committe','dr','inform','develop','partner','meet','provid','platform','mrc','develop','partner','donor','govern','organ','discuss','made','first','year','implement','current','strateg','plan','strateg','editorsth','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','end','inform','pleas','contactmr','sopheak','meascommun','offic','mekong','river','commiss','secretariatvientian','lao','pdr','ext'],['australia','june','mekong','plan','monitor','flood','drought','manag','climat','chang','key','area','benefit','renew','partnership','mekong','river','commiss','mrc','basin','technic','mrc','two','bodi','reach','agreement','continu','cooper','mrc','secretariat','ceo','dr','pich','hatda','ceo','mr','understand','offici','australia','mekong','senior','energi','senior','strengthen','also','contribut','address','current','challeng','mekong','basin','ceo','hatda','said','increas','climat','chang','develop','water','expect','area','two','basin','bring','mekong','mrc','key','role','region','knowledg','hub','water','diplomaci','platform','mr','said','technic','cooper','two','basin','one','year','mrc','establish','australia','support','partnership','cooper','year','base','one','renew','see','technic','water','plan','monitor','drought','flood','manag','plan','manag','climat','chang','plan','first','energi','dialogu','bring','senior','energi','offici','cambodia','lao','pdr','thailand','viet','nam','myanmar','june','meet','australia','renew','energi','dialogu','provid','mekong','offici','australia','renew','energi','water','manag','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','end','inform','pleas','contactmr','sopheak','meascommun','offic','pressmekong','river','commiss','secretariatvientian','lao','pdre','sopheakmrcmekongorgp','ext','australia','may','repres','group','mekong','river','commiss','mrc','region','current','joint','effort','better','address','challeng','mekong','includ','repres','cambodia','lao','pdr','thailand','viet','nam','china','myanmar','well','develop','partner','achiev','work','togeth','issu','mrc','mekong','water','resourc','manag','project','project','mrc','member','countri','cambodia','lao','pdr','thailand','viet','nam','work','togeth','five','initi','sinc','strengthen','transboundari','dialogu','water','resourc','manag','level','includ','mekong','nam','achiev','includ','understand','issu','transboundari','mechan','joint','plan','strengthen','data','inform','discuss','address','continu','challeng','region','nation','level','key','area','cooper','share','among','mekong','countri','mrc','data','inform','system','improv','share','data','inform','water','resourc','manag','benefit','share','plan','project','implement','includ','strengthen','peopl','understand','inform','contribut','transboundari','lower','mekong','countri','govern','work','togeth','transboundari','challeng','said','mr','offic','nation','water','resourc','nation','mekong','committe','secretariat','pleas','transboundari','project','countri','understand','key','water','issu','cooper','share','water','resourc','pich','hatda','ceo','mekong','river','commiss','secretariat','transboundari','cooper','provid','climat','chang','flood','drought','increas','benefit','achiev','climat','chang','mekong','river','commiss','transboundari','cooper','joint','project','among','member','countri','support','member','countri','peopl','cooper','editorsth','mekong','river','commiss','intergovernment','bodi','cooper','sustain','manag','mekong','basin','member','includ','cambodia','lao','pdr','thailand','viet','nam','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','bodi','commiss','work','issu','includ','sustain','flood','manag','issu','climat','chang','flood','drought','inform','pleas','offic','mekong','river','commiss','secretariat','thailand','may','offici','nation','mekong','committe','cambodia','thailand','agre','key','flood','drought','joint','project','flood','drought','manag','cambodia','two','countri','committe','meet','five','project','joint','mechan','includ','flood','drought','plan','flood','drought','manag','plan','provinc','manag','flood','drought','improv','region','flood','drought','issu','share','understand','water','resourc','develop','challeng','mechan','work','better','flood','drought','thailand','offic','nation','water','resourc','dr','said','cambodia','thailand','share','understand','bring','transboundari','challeng','work','togeth','countri','work','better','address','water','resourc','manag','challeng','state','cambodia','ministri','water','resourc','mr','said','joint','project','may','develop','ministri','cooper','part','achiev','plan','joint','project','support','transboundari','cooper','among','mrc','member','countri','cooper','program','dr','project','transboundari','better','understand','manag','water','resourc','develop','manag','address','develop','challeng','two','countri','part','nation','plan','two','countri','implement','mekong','basin','develop','strategi','cooper','plan','joint','effort','address','nation','region','challeng','plan','joint','project','discuss','develop','flood','drought','implement','vientian','lao','pdr','may','govern','provid','support','mekong','river','commiss','implement','initi','data','inform','system','provid','inform','mrc','member','vientian','mrc','secretariat','made','technic','implement','manag','govern','organ','support','australia','mrc','work','role','platform','technic','water','cooper','mekong','region','lao','pdr','mr','said','mrc','data','inform','system','initi','mrc','govern','bodi','joint','committe','meet','viet','nam','area','includ','data','manag','system','data','manag','system','river','monitor','forecast','inform','secretariat','offic','dr','pich','hatda','said','provid','address','chang','climat','chang','water','river','basin','basin','state','develop','strengthen','one','mrc','key','role','region','knowledg','initi','would','partner','support','cooper','would','current','data','inform','end','year','discuss','joint','committe','implement','support','develop','partner','ceo','hatda','said','australia','one','longterm','develop','partner','mrc','sinc','commiss','provid','continu','support','mrc','strateg','work','togeth','support','develop','partner','strengthen','mrc','region','river','basin','organ','support','sustain','manag','develop','share','water','resourc','countri','benefit','peopl','lower','mekong','editorsth','mrc','intergovernment','organ','region','dialogu','cooper','lower','mekong','river','basin','establish','base','mekong','agreement','cambodia','lao','pdr','thailand','viet','nam','organ','serv','region','platform','water','diplomaci','well','knowledg','hub','water','resourc','manag','sustain','develop','region','end','mr','sopheak','meascommun','offic','pressmekong','river','commiss','secretariatvientian','lao','pdre','sopheakmrcmekongorgp','ext']]
dictionary=texts
from gensim import corpora
dictionary = corpora.Dictionary(texts)
corpus1 = [dictionary.doc2bow(text) for text in texts]
#print('dictionary:',dictionary)
print('corpus:',corpus1)
from gensim import models
tfidf = models.TfidfModel(corpus1)
print(tfidf)
print(tfidf[corpus1])
ldaseq = ldaseqmodel.LdaSeqModel(corpus=corpus1, id2word=dictionary, time_slice=[5,5], num_topics=2)
#print(ldaseq.print_topics(time=1))
print(ldaseq.print_topic_times(topic=0))
#可视化
from gensim.models.wrappers.dtmmodel import DtmModel
from gensim.corpora import Dictionary, bleicorpus
import pyLDAvis
dtm_path = "D:\湄公河NLP 实验数据\DTM\dtm-win64.exe"
#dtm_model = DtmModel(dtm_path, corpus1, time_slice=[1,1,1], num_topics=2, id2word=dictionary, initialize_lda=True)
#dtm_model.save('dtm_news')
#if we've saved before simply load the model
#ldaseq_chain.save('dtm_news')
#dtm_model = DtmModel.load('dtm_news')
doc_topic, topic_term, doc_lengths, term_frequency, vocab = ldaseq.dtm_vis(time=0, corpus=corpus1)
vis_wrapper = pyLDAvis.prepare(topic_term_dists=topic_term, doc_topic_dists=doc_topic, doc_lengths=doc_lengths, vocab=vocab, term_frequency=term_frequency)
pyLDAvis.show(vis_wrapper)
LDA文档主题生成模型
LDA是一种文档主题生成模型,包含词、主题和文档三层结构。
所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息。它采用了词袋的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
二、使用流程
1.训练语料的预处理
将文档中原始的字符文本转换成Gensim模型所能理解的稀疏向量。由于语言和应用的多样性,我们需要先对原始的文本进行分词、去除停用词等操作,得到每一篇文档的特征列表。例如,在词袋模型中,文档的特征就是其包含的word。
接下来,我们可以调用Gensim提供的API建立语料特征(此处即是word)的索引字典,并将文本特征的原始表达转化成词袋模型对应的稀疏向量的表达。依然以词袋模型为例:
from gensim import corpora #corpora用于构造词典
dictionary = corpora.Dictionary(texts) #分词,并存储
corpus = [dictionary.doc2bow(text) for text in texts] #寻找整篇语料的词典、所有词
print corpus[0] # [(0, 1), (1, 1), (2, 1)]到这里,训练语料的预处理工作就完成了。我们得到了语料中每一篇文档对应的稀疏向量(这里是bow向量);向量的每一个元素代表了一个word在这篇文档中出现的次数。值得注意的是,虽然词袋模型是很多主题模型的基本假设,这里介绍的doc2bow函数并不是将文本转化成稀疏向量的唯一途径。在下一小节里我们将介绍更多的向量变换函数。
最后,出于内存优化的考虑,Gensim支持文档的流式处理。我们需要做的,只是将上面的列表封装成一个Python迭代器;每一次迭代都返回一个稀疏向量即可。
class MyCorpus(object):
def __iter__(self):
for line in open('mycorpus.txt'):
# assume there's one document per line, tokens separated by whitespace
yield dictionary.doc2bow(line.lower().split())2.主题向量的变换
预处理语料之后,分支一:BOW词袋模型;分支二:TFIDF
对文本向量的变换是Gensim的核心。通过挖掘语料中隐藏的语义结构特征,我们最终可以变换出一个简洁高效的文本向量。在Gensim中,每一个向量变换的操作都对应着一个主题模型,例如上一小节提到的对应着词袋模型的doc2bow变换。每一个模型又都是一个标准的Python对象。下面以TF-IDF模型为例,介绍Gensim模型的一般使用方法。
首先是模型对象的初始化。通常,Gensim模型都接受一段训练语料(注意在Gensim中,语料对应着一个稀疏向量的迭代器)作为初始化的参数。显然,越复杂的模型需要配置的参数越多。
from gensim import models
tfidf = models.TfidfModel(corpus)其中,corpus是一个返回bow向量的迭代器。这两行代码将完成对corpus中出现的每一个特征的IDF值的统计工作。
接下来,我们可以调用这个模型将任意一段语料(依然是bow向量的迭代器)转化成TFIDF向量(的迭代器)。需要注意的是,这里的bow向量必须与训练语料的bow向量共享同一个特征字典(即共享同一个向量空间)。
doc_bow = [(0, 1), (1, 1)]
print tfidf[doc_bow] # [(0, 0.70710678), (1, 0.70710678)]注意,同样是出于内存的考虑,model[corpus]方法返回的是一个迭代器。如果要多次访问model[corpus]的返回结果,可以先将结果向量序列化到磁盘上。我们也可以将训练好的模型持久化到磁盘上,以便下一次使用:
tfidf.save("./model.tfidf")
tfidf = models.TfidfModel.load("./model.tfidf")Gensim内置了多种主题模型的向量变换,包括LDA,LSI,RP,HDP等。这些模型通常以bow向量或tfidf向量的语料为输入,生成相应的主题向量。所有的模型都支持流式计算。关于Gensim模型更多的介绍,可以参考这里:API Referencehttps://radimrehurek.com/gensim/apiref.html
3.文档相似度的计算
在得到每一篇文档对应的主题向量后,我们就可以计算文档之间的相似度,进而完成如文本聚类、信息检索之类的任务。在Gensim中,也提供了这一类任务的API接口。
以信息检索为例。对于一篇待检索的query,我们的目标是从文本集合中检索出主题相似度最高的文档。
首先,我们需要将待检索的query和文本放在同一个向量空间里进行表达(以LSI向量空间为例):
# 构造LSI模型并将待检索的query和文本转化为LSI主题向量
# 转换之前的corpus和query均是BOW向量
lsi_model = models.LsiModel(corpus, id2word=dictionary,num_topics=2)
documents = lsi_model[corpus]
query_vec = lsi_model[query]
接下来,我们用待检索的文档向量初始化一个相似度计算的对象:
index = similarities.MatrixSimilarity(documents)我们也可以通过save()和load()方法持久化这个相似度矩阵:
index.save('/tmp/test.index')
index = similarities.MatrixSimilarity.load('/tmp/test.index')注意,如果待检索的目标文档过多,使用similarities.MatrixSimilarity类往往会带来内存不够用的问题。此时,可以改用similarities.Similarity类。二者的接口基本保持一致。
最后,我们借助index对象计算任意一段query和所有文档的(余弦)相似度:
sims = index[query_vec]
#返回一个元组类型的迭代器:(idx, sim)三、代码简例
gensim 是一个通过衡量词组(或更高级结构,如整句或文档)模式来挖掘文档语义结构的工具。
三大核心概念:文集(语料)–>向量–>模型
- 文集:将原始的文档处理后生成语料库
#将原始的文档处理后生成语料库
from gensim import corpora
import jieba
documents = ['工业互联网平台的核心技术是什么',
'工业现场生产过程优化场景有哪些']
def word_cut(doc):
seg = [jieba.lcut(w) for w in doc]
return seg
texts= word_cut(documents)
##为语料库中出现的所有单词分配了一个唯一的整数id
dictionary = corpora.Dictionary(texts)
print(dictionary.token2id)
#结果:{'互联网': 0, '什么': 1, '工业': 2, '平台': 3, '是': 4, '核心技术': 5, '的': 6, '优化': 7, '哪些': 8, '场景': 9, '有': 10, '现场': 11, '生产': 12, '过程': 13}- 向量:将文档表示为向量
##该函数doc2bow()只计算每个不同单词的出现次数,将单词转换为整数单词id,并将结果作为稀疏向量返回
bow_corpus = [dictionary.doc2bow(text) for text in texts]
bow_corpus
# 每个元组的第一项对应词典中符号的 ID,第二项对应该符号出现的次数- 模型
from gensim import models
# train the model
tfidf = models.TfidfModel(bow_corpus)