本文主要讨论的是尝试使用NetworkX,构建复杂网络(CNA),初步探究Panama Papers中的隐含信息。流程大致为:1.用NetworkX构建Panama Papers的网络模型;2.用常见的网络测量指标来评估主网络和子网络的信息;3.可视化网络的信息。
1.故事的起源
最近J看到一本叫做Complex Network Analysis in Python,原本只是想学画网络图的,结果,一翻起来,仿佛发现了新大陆。文章主要介绍了Complex Network Analysis的一般方法,有介绍工具,也有传授方法,文章的叙述风格也满有趣的。J没接触过复杂网络,不喜欢看英文书,可是这应该是像J这样的初学者能找到的最适合的资源了吧?
当看到书的第七章中,提到了Panama Papers的时候,J眼前一亮,也大致了明白了文章为什么没有被翻译。不过不妄议国事,作为遵纪守法且不会翻墙的J某人来说,在花了一个晚上的时间找数据后,J意外找到了一篇不错的文章Exploring the Panama Papers Network。该文章写于2016.6,J某人决定按照文章的思路,尝试对Panama Papers的数据做个初探。(这么水的文章应该不会被查水表吧)
2、项目的成果展示
坦白说,拿Panama Papers来做复杂网络分析的第一个对手,我想我一定是疯了。。。凭借J微弱的金融会计知识,理解Panama Papers的基本数据结构已经是巨大的挑战了。ICIJ透露的数据结构主要包括entities, addresses, officers and intermediaries4个nodes数据集,和描述了上面4个数据集关系的1个edges数据集。关于各数据集的解释大致如下:
- ”Entity (offshore)”: company, trust or fund created in a low-tax, offshore jurisdiction by an agent;
- ”Officer”: person or company who plays a role in an offshore entity;
- ”Intermediary”: a go-between for someone seeking an offshore corporation and an offshore service provider - usually a law-firm or a middleman that asks an offshore service provider to create an offshore firm for a client;
- ”Address”: contact postal address as it appears in the original databases obtained by ICIJ
2.1创建一个网络图模型


import pandas as pd import matplotlib.colors as colors import matplotlib.cm as cmx import matplotlib.patches as mpatches import numpy as np import matplotlib.pyplot as plt import networkx as nx from networkx.drawing.nx_agraph import graphviz_layout
读取和构建一个网络图模型
def normalise(s, strip_punctuation=False): if pd.isnull(s): return "" s = s.strip().lower() PUNCTUATION = """.,"'()[]{}:;/!£$%^&*-=""" if strip_punctuation: for c in PUNCTUATION: s = s.replace(c, "") return s adds = pd.read_csv("Addresses.csv", low_memory=False) ents = pd.read_csv("Entities.csv", low_memory=False) ents["name"] = ents["name"].apply(normalise) inter = pd.read_csv("Intermediaries.csv", low_memory=False) inter["name"] = inter.name.apply(normalise) offi = pd.read_csv("Officers.csv", low_memory=False) offi["name"] = offi.name.apply(normalise) edges = pd.read_csv("all_edges.csv", low_memory=False)
我们会用pandas来读取数据集,使用NetworkX来构建有向图,然后根据edges文件中相似的冗余的node从网络中剔除,得到我们需要的图模型。
G = nx.DiGraph() for n,row in adds.iterrows(): G.add_node(row.node_id, node_type="address", details=row.to_dict()) for n,row in ents.iterrows(): G.add_node(row.node_id, node_type="entities", details=row.to_dict()) for n,row in inter.iterrows(): G.add_node(row.node_id, node_type="intermediates", details=row.to_dict()) for n,row in offi.iterrows(): G.add_node(row.node_id, node_type="officers", details=row.to_dict()) for n,row in edges.iterrows(): G.add_edge(row.node_1, row.node_2, rel_type=row.rel_type, details={})
当J某人看到把5个数据集的数据全部添加到图模型G里时,J的电脑从内存使用20%涨到92%时,J明白了J可能要换台电脑了。4G内存果然只是摆设,当初买神船的电脑真是因为穷和锻炼身体。把节点和边添加到模型上后,我们也要将冗余和有相似的节点删除。
SAME_NAME_REL_TYPES = [ 'similar name and address as', 'same name and registration date as', 'same address as', ] def merge_similar_names(g): edges = list(g.edges(data=True)) removed = set() while edges: current_edge = edges.pop() if current_edge[2]["rel_type"] not in SAME_NAME_REL_TYPES: continue if current_edge[0] in removed or current_edge[1] in removed: continue new_edges = merge_edge(g, current_edge) edges += new_edges removed.add(current_edge[0]) def merge_edge(g, target_edge): n_remove, n_replace = target_edge[0:2] edges_to_replace = g.edges(nbunch=n_remove, data=True) new_edges = [] for e in edges_to_replace: if (e[0],e[1]) == (n_remove, n_replace): continue if e[0] == n_remove: new_edges.append( (n_replace, e[1], e[2]) ) else: new_edges.append( (e[0], n_replace, e[2]) ) g.remove_node(n_remove) for e in new_edges: g.add_edge(e[0], e[1], **e[2]) return new_edges

由于整个网络过于庞大,我们会将总个网络模型G拆为多个子网络放到subgraphs中。
subgraphs = [g for g in nx.connected_component_subgraphs(G.to_undirected())] subgraphs = sorted(subgraphs, key=lambda x: x.number_of_nodes(), reverse=True) print([s.number_of_nodes() for s in subgraphs[:10]])

把所有的子网络按照节点数从大到小排列,我们发现90%的节点组成了一个大网络,其他的网络节点就要简单的多。(我一定是膨胀了)
我们随意画出一个子网络,来简单的分析Panama Papers中的信息。
def get_node_label(n): if n["node_type"] == "address": if pd.isnull(n["details"]["address"]): return "" return n["details"]["address"].replace(";", "\n") return n["details"]["name"] def build_patches(n2i, sm): patches = [] for k,v in n2i.items(): patches.append(mpatches.Patch(color=sm.to_rgba(v), label=k)) return patches
def plot_graph(g, label_nodes=True, label_edges=False, figsize=(15,15)): """ :param g: :return: """ node_to_int = {k: node_types.index(k) for k in node_types} node_colours = [node_to_int[n[1]["node_type"]] for n in g.nodes(data=True)] node_labels = {k:get_node_label(v) for k,v in g.nodes(data=True)} cmap = plt.cm.rainbow cNorm = colors.Normalize(vmin=0, vmax=len(node_to_int)+1) scalarMap = cmx.ScalarMappable(norm=cNorm, cmap=cmap) plt.figure(figsize=figsize) plt.legend(handles=build_patches(node_to_int, scalarMap)) pos = nx.spring_layout(g, iterations=100) # nodes nx.draw_networkx_nodes(g, pos, node_color=node_colours, cmap=cmap, vmin=0, vmax=len(node_to_int)+1) # edges nx.draw_networkx_edges(g, pos, edgelist=g.edges(), arrows=True) # labels if label_nodes: nx.draw_networkx_labels(g, pos, labels=node_labels, font_size=12, font_family='sans-serif') if label_edges: edge_labels = {(e[0], e[1]): e[2]["rel_type"] for e in g.edges(data=True)} nx.draw_networkx_edge_labels(g, pos, edge_labels
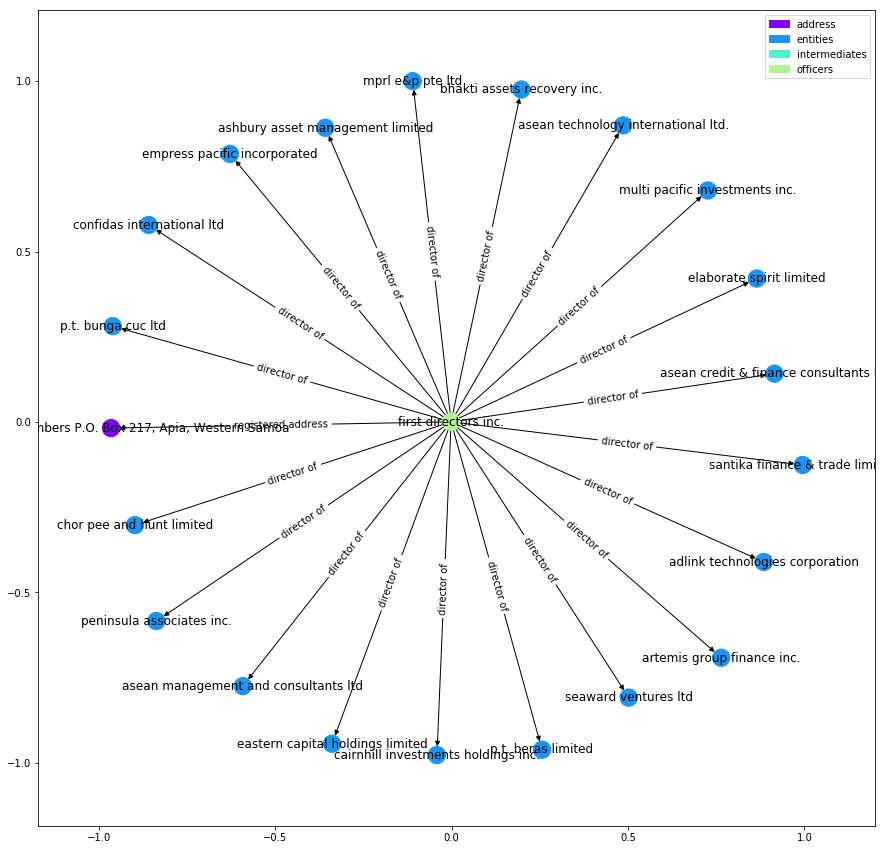
plot_graph(subgraphs[176])
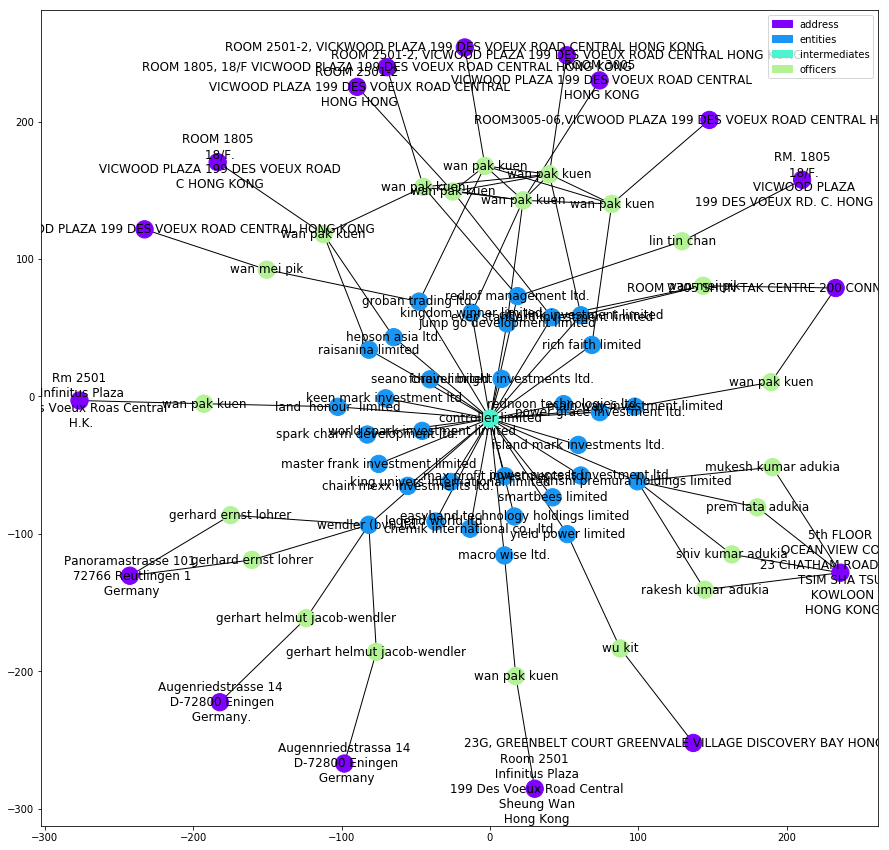
在这张网络图中的代理人为”controller limited“(分析为学术探讨,并不针对任何人和组织),我们可以看到在该网络中的entities实体企业比较复杂,而背后的officers适合比较清晰。出现比较多的是来自香港某大道的”wan pak kuen“和德国的”gerhart“。不过大部分网络中的officers大多为"the bearer" ,笔者By Iain的猜测是:His guess is that here "the bearer" refers to an infamous bearer board。关于出现了10次的”wan pak kuen“,虽然有时标题不同,有时大小写不同,当我们并不清楚ICIJ的数据处理方式和本地知识,所以很难下结论。
2.2主网络图的分析
接下来,我们会对主图进行分析。我们将会不得不面对一个问题,我们的主网络太大了。用图来可视化我们的第176号子网络就已经有些勉强了,而90W个节点的网络,差点气的J把电脑砸了。因此我们也需要引入一些度量的方式来评估我们的网络。
g = subgraphs[0] nodes = g.nodes() g_degree = g.degree() types = [g.node[n]["node_type"] for n in nodes] degrees = [g_degree[n] for n in nodes] names = [get_node_label(g.node[n]) for n in nodes] node_degree = pd.DataFrame(data={"node_type":types, "degree":degrees, "name": names}, index=nodes)
从上面的子图中,我们可以猜测代理人可能会处于某个网络的C位,我们会测量不同的4类信息来验证我们的结论。我们会用到”度“(degree)的概念,"度"是一个节点的连接的边的个数。("degree" is the number of edges connected to a node).
node_degree.groupby("node_type").agg(["count", "mean", "median"])
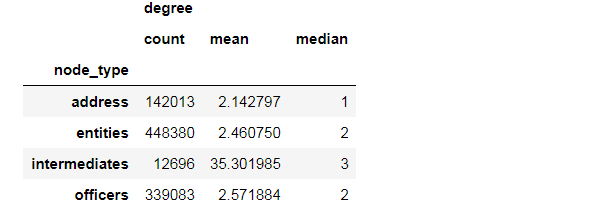
我们可以看到在4类数据信息中,中位数都比较小,50%的值都只有1-3。其中,代理人的均值很大,表明在代理人这组数据中的分布高度不均匀且尾巴较长,拖尾严重,存在少量具有大量连接的边。我们来研究一下度排行在前15的节点。
node_degree.sort_values("degree", ascending=False)[:15]
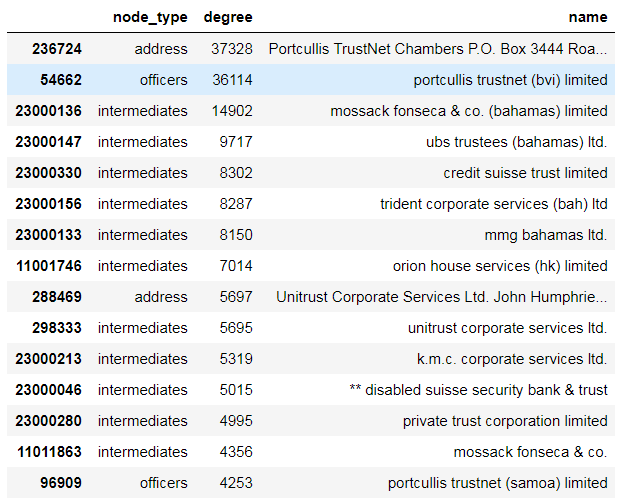
和想象中的略有不同,有最多连接边的节点是一个地址,但紧随其后的是中间人的地址:“ portcullis trustnet”(您可以在此《卫报》文章中了解到一些有关它们的信息)。 看起来这个特定地址是37,000多个实体企业(entities)的注册地址。
鉴于中介似乎是帮助创建实体的中间人,因此很容易想到每个中介人都可以链接到许多实体企业,但目前尚不清楚如何将它们链接在一起。 让我们看一下“ portcullis trustnet(bvi)limited”和“ unitrust Corporate Services Ltd.”之间的最短路径。
def plot_path(g, path): plot_graph(g.subgraph(path), label_edges=True) path = nx.shortest_path(g, source=54662, target=298333) plot_path(G, path)
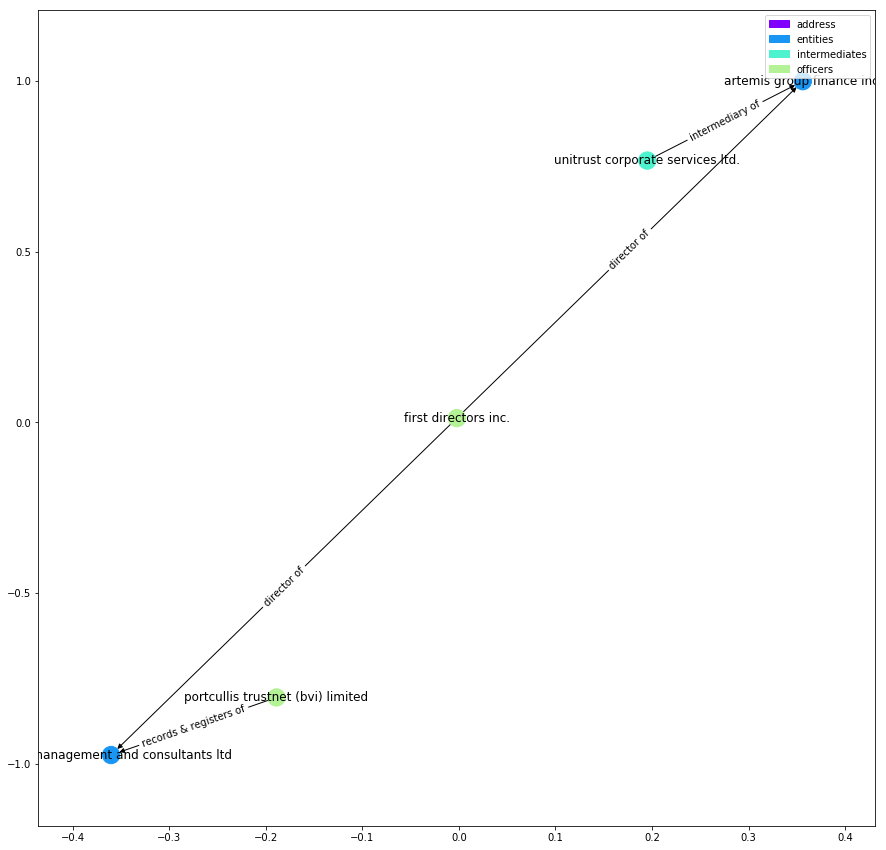
看来,这两个中介机构是通过共享共同董事“第一董事公司”的公司联系在一起的。
plot_graph(G.subgraph(nx.ego_graph(g, 24663, radius=1).nodes()), label_edges=True)
3用常用的测量指标来分析网络
3.1度的分布
在上面我们已经解释过度的概念了,现在我们可以分析整个主网络的度的分布。
max_bin = max(degrees) n_bins = 20 log_bins = [10 ** ((i/n_bins) * np.log10(max_bin)) for i in range(0,n_bins)] fig, ax = plt.subplots() node_degree.degree.value_counts().hist(bins=log_bins,log=True) ax.set_xscale('log') ax.set_xlim(0,max(log_bins)) plt.xlabel("Number of Nodes") plt.ylabel("Number of Degrees") plt.title("Distribution of Degree");
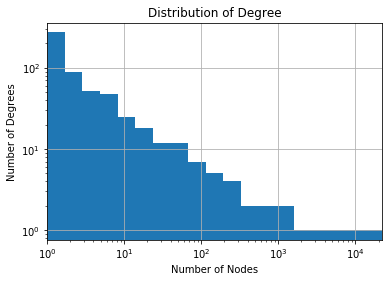
关于度的讨论大致和上面的一致。
3.2节点的重要度
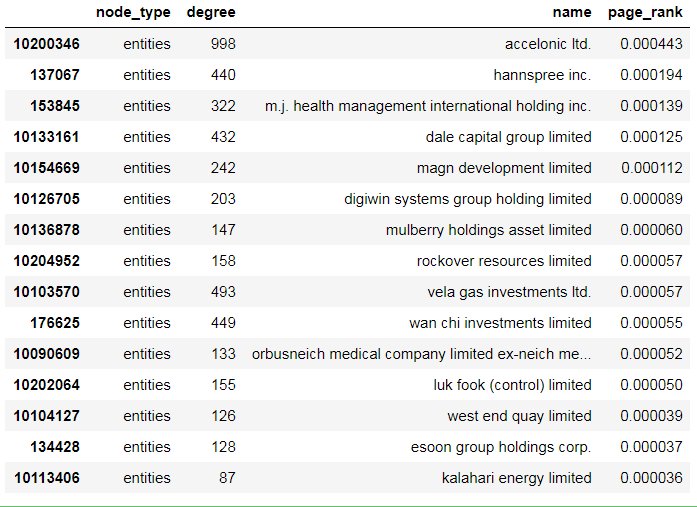
衡量节点重要性的常用方法是页面排名(Page Rank)。 Page Rank是Google用来确定网页重要性的一种措施。 本质上,如果我们随机的遍历整个图,然后不时地跳转到随机页面,则在每个节点上花费的时间与其页面排名Page Rank成正比。
pr = nx.pagerank_scipy(g) node_degree["page_rank"] = node_degree.index.map(lambda x: pr[x]) #node_degree.sort_values("page_rank", ascending=False)[0:15] node_degree[node_degree.node_type == "entities"].sort_values("page_rank", ascending=False)[0:15]
t = nx.ego_graph(g, 10165699, radius=1)
plot_graph(t, label_edges=True)

对于Page Rank比较大的节点,在我们看来最终也只是拥有大量股东和使用高级别中介机构的实体。
3.3聚类系数
我们可以用聚类系数(clustering coefficient)对图的“形状”进行的另一种度量。你可以将其视为对图的局部结构的度量:邻居中有多少部分节点,并且这些节点也互为邻居节点(what fraction of a nodes neighbours are also neighbours of each other)。
cl = nx.clustering(g) fig, ax = plt.subplots() node_degree["clustering_coefficient"] = node_degree.index.map(lambda x: cl[x]) node_degree.clustering_coefficient.hist() ax.set_xlim(0,1) plt.xlabel("Number of Nodes") plt.ylabel("Number of clustering_coefficient") plt.title("Distribution of clustering_coefficient");
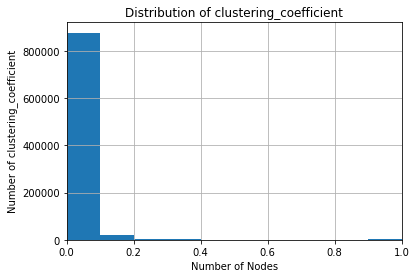
事实证明,整个网络并没有太多的具体明显的局部结构。大多数节点的聚类系数为零。 而少数具有非零值的节点,却趋向于具有比较小的度。 这意味着Panama Papers网络不是小型世界网络。
要查看几种聚类系数非零情况呢,我们可以看下面的示例子图:
t = nx.ego_graph(g, 122762, radius=1)
plot_graph(G.subgraph(t), label_edges=True)
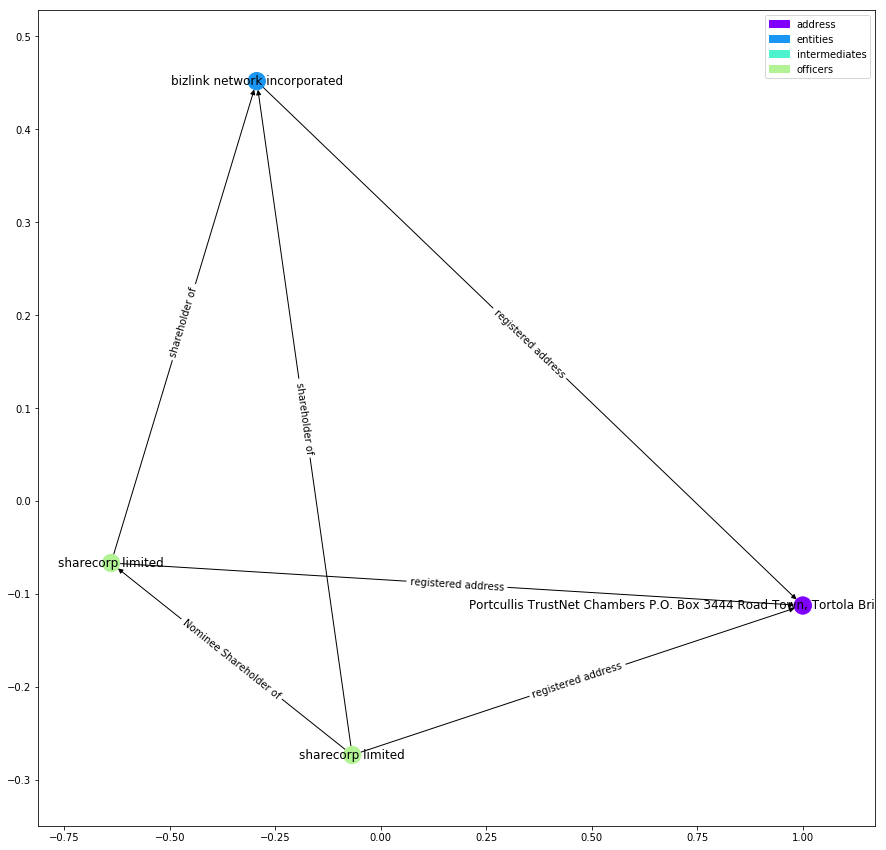
我们会发现,聚类系数非零的节点们似乎是一些规模并不大,但有高关联,比如共享同一个地址的节点。
3.4子图的度的中位数(the largest median node degree)
为了探索一些更有趣的结构,我们可以查看具有最大中间节点度的子网络图。
avg_deg = pd.Series(data=[np.median([d[1] for d in sg.degree()]) for sg in subgraphs], index=range(0,len(subgraphs))) tt = subgraphs[372].nodes() plot_graph(G.subgraph(tt)) #avg_deg.sort_values(ascending=False)[0:10]

我们会发现,对于这种网络的话,更像是规模中等,数量较多,且拥有相同所有者的公司和企业。
4.关于本次项目的思考
- 额,我这两天的时间都拿来干什么了?还我青春,还我休息时间。在做研究的时候,课题的选择是很重要的,Panama Papers需要大量的金融会计知识,做为网络的初级研究视乎并不十分合适。
- NetworkX的优势在于文档详实,但底层并不是有JAVA或C编写的,随然和matplotlib很配,但使用时注意要节省内存
J某人对自己说的话
这个月依稀有4位朋友找过我,J某人因为有些个人的原因没有去搭理,还是要悄悄咪咪的道个歉。国庆在爸妈那边好好休息了3、4天,每天吃的真的是要什么有什么,还好就胖了5斤。(⊙v⊙)嗯,除了差点被抓取相亲其他都很完美。
前段时间是又累又浮躁,J某人家的上一辈都是小生意人,耳堵目燃的勤劳和精打细算能学多多还是要学多少的。(⊙v⊙)新的场子环境比以前的好不少,听说是因为打电话给表舅诉苦,省下了不少租金,看来亲戚还是要多走动的。也希望陈老板继续努力,没准J在有生之年还能当富二代。
妈妈说我应该买点补水的东西。。开玩笑,J某人天生丽质,需要那种东西?还是减肥要紧。
上个月买的神奇宝贝特别篇漫画,一本都没看完。虽然可能该叫宝可梦了,虽然也早就从其他途径知道小黄打败了龙系天王的飞行系神奇宝贝。但没没翻开就会想起16年前的北京的大杂院,想起3个人捉20个跑的捉迷藏,想起10几个人用树叶堆起的烧烤,想起替我收拾打翻墨水的少女,想起那个充满各种可能的夏天。
风筝的线断了,就拿来扎头发吧。