一、人工智能、机器学习和深度学习
- 人工智能是很宽泛的领域,让机器像人一样思考:机器学习,自动推理;让机器人像人一样听懂:语音识别;让机器像人一样看懂:视觉识别;让机器人像人一样运动:运动控制。
- 传统机器学习是使用人工智能算法使得计算机有学习能力,模拟或实现人类的学习行为,来获取新的知识或技能并根据自身结构不断完善性能。
- 深度学习属于机器学习的子类,是利用深度神经网络来解决特征表达的一种学习过程。
深度神经网络本身并非是一个全新的概念,可理解为包含多个隐含层的神经网络结构。为了提高深层神经网络的训练效果,人们对神经元的连接方法以及激活函数等方面做出了调整。其目的在于建立、模拟人脑进行分析学习的神经网络,模仿人脑的机制来解释数据,如文本、图像、声音。
三者关系如图1所示:
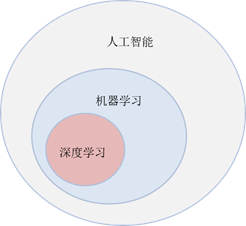
图1 人工智能、机器学习与深度学习
二、 为什么现在深度学习这么受欢迎
- 机器学习能够适应各种数据量,特别是数据量较小的场景。如果数据量迅速增加,那么深度学习的效果将更加突出,这是因为深度学习算法需要大量数据才能完美理解。随着互联网的发展,数据量这一问题被完美解决,深度学习在很多方面效果优于机器学习;
- 机器学习需要工程师手动提取特征(如图2),耗费大量时间在重复性劳动上,而深度学习可以自动提取特征(如图3),节省时间,降低工作量,提高工作效率,让工程师将更多的精力放在更有价值的研究方向上;
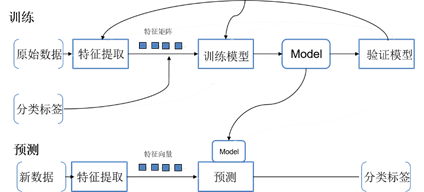
图2 机器学习步骤
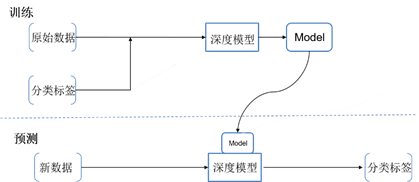
图3 深度学习步骤 - 由于数据量的增加,深度学习依赖于高端硬件设备—GPU,并且由于算法中含有很多参数,训练时间大大增加;
但是由于深度学习的高效率和高性能,受到了广泛应用。
三、深度学习基本理论
3.1 神经网络
深度学习应用的方法主要是神经网络,最简单的神经网络有以下几个部分:输入层(x),隐藏层,输出层(y)。(图4是最神经网络的基本结构)每个节点都是一个神经元,每层的每个神经元都和下一层的神经元相连接,我们称之为全连接结构(Full connected)。输入层(x)就是神经网络提取的特征,输出层(y)就是想要得到的结果。

图4 神经网络基本结构
单独取出神经元分析(图5):黄色圆圈代表隐藏层的一个神经元,经过运算:
y=f(W1×X1+W2×X2+W3×X3+b) (1)
,得到输出(f就是激活函数,目的是获得函数的非线性),常用的激活函数有sigmoid函数、ReLu函数等。
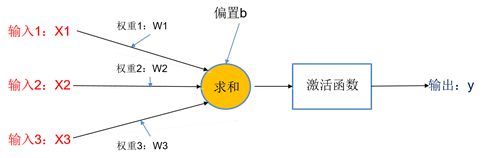
图5 神经元结构
W和b会预先设定值,经(1)公式后得到预测值y ̂(这个计算y ̂的过程成为正向传播),预测的好坏使用损失函数Loss分析:
Loss=(y ̂-y)² (2)
Loss越小,说明预测效果越好。现在常用的损失函数有mse(均方误差损失函数)、cross entropy(交叉熵损失函数)、ada(指数损失函数)
利用损失函数优化W和b,这就是神经网络的学习过程,常见的优化算法—梯度下降法(常用)(另外还有sgd、adagrad、adam)。公式(3)(4)是更新W和b的公式。更新参数的过程是从后往前的过程,我们称之为反向传播(计算出y ̂值,反过来根据y ̂值分析权重的过程)

图6 梯度下降法
W = W -η(∂ L/∂ W ) (3)(η是学习率learning rate)
b = b-η(∂ L/∂ b) (4)
在训练过程中常常会出现的两个问题:
①欠拟合根本原因是特征维度过少,模型过于简单,导致拟合的函数无法满足训练集,误差较大。解决方法:增加特征维度,增加训练数据;
②过拟合:根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。 过度的拟合了训练数据,而没有考虑到泛化能力。解决方法:(1)减少特征维度;(2)正则化,降低参数值。
3.2卷积神经网络
我们应用深度学习方法分析图像时,由于图像的特殊性质:平移不变性、旋转/视角不变性、尺寸不变性等,处理图像常用的是卷积神经网络。经典卷积神经网络结构如图7:
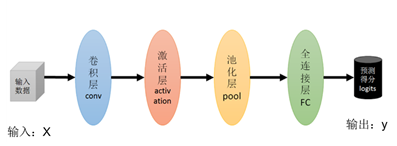
图7: 卷积神经网络
与普通神经网络相比,增加的是卷积层和池化层。
卷积过程(图8):我们通常采用3×3、5×5或7×7卷积核(卷积核中的数字就是权重)在图像做滑动卷积,自动提取图像高维特征(一个卷积核在图像上的滑动卷积,应用了权值共享的思想;由于卷积核指定的是一个区域,应用了局部感知的思想)。

图8 图像卷积
池化过程:一般采用2×2的窗口,使用最大池化和平均池化。图9使用的2×2窗口,应用最大池化(池化过程使图像数据量大大减少,应用了下采样思想)。
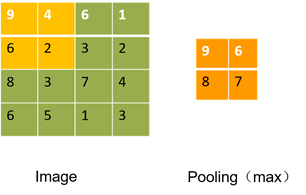
图9 池化
增加卷积层和池化层目的是减少数据量,并能提取图像的所有特征。
-
kaggle猫狗训练就是应用的卷积神经网络模型AlexNet,具体实验和源代码请参考猫狗训练