版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
Flink算子学习
点关注不迷路,欢迎再访!
算子将一个或多个DataStream转换为新的DataStream。程序可以将多个转换组合成复杂的数据流拓扑。
一.DataStream转换
map可以理解为映射,对每个元素进行一定的变换后,映射为另一个元素
| 转型 | 描述 |
|---|---|
| 映射 DataStream→DataStream | 采用一个数据元并生成一个数据元。一个map函数,它将输入流的值加倍: |
| FlatMap DataStream→DataStream | 采用一个数据元并生成零个,一个或多个数据元。将句子分割为单词的flatmap函数: |
| KeyBy DataStream→KeyedStream | 逻辑上将流分区为不相交的分区。具有相同Keys的所有记录都分配给同一分区。在内部,keyBy()是使用散列分区实现的。指定键有不同的方法。 |
| Filter DataStream→DataStream | 计算每个数据元的布尔函数,并保存函数返回true的数据元。过滤掉零值的过滤器: |
| 折叠 KeyedStream→DataStream | 具有初始值的被Keys化数据流上的“滚动”折叠。将当前数据元与最后折叠的值组合并发出新值。折叠函数,当应用于序列(1,2,3,4,5)时,发出序列“start-1”,“start-1-2”,“start-1-2-3”,. … |
| 聚合 KeyedStream→DataStream | 在被Keys化数据流上滚动聚合。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具有最小值的数据元(max和maxBy相同)。 |
| Window KeyedStream→WindowedStream | 可以在已经分区的KeyedStream上定义Windows。Windows根据某些特征(例如,在最后5秒内到达的数据)对每个Keys中的数据进行分组。有关窗口的完整说明,请参见windows。dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data |
| WindowAll DataStream→AllWindowedStream | Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数据)对所有流事件进行分组。有关窗口的完整说明,请参见windows。警告:在许多情况下,这是非并行转换。所有记录将收集在windowAll 算子的一个任务中。dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data |
| Window Reduce WindowedStream→DataStream | 将函数缩减函数应用于窗口并返回缩小的值。 |
| Window Fold WindowedStream→DataStream | 将函数折叠函数应用于窗口并返回折叠值。示例函数应用于序列(1,2,3,4,5)时,将序列折叠为字符串“start-1-2-3-4-5” |
| Union DataStream *→DataStream | 两个或多个数据流的联合,创建包含来自所有流的所有数据元的新流。注意:如果将数据流与自身联合,则会在结果流中获取两次数据元。dataStream.union(otherStream1, otherStream2, …); |
| Window Join DataStream,DataStream→DataStream | 在给定Keys和公共窗口上连接两个数据流。 |
| 拆分 DataStream→SplitStream | 根据某些标准将流拆分为两个或更多个流。 |
| 提取时间戳 DataStream→DataStream | 从记录中提取时间戳,以便使用使用事件时间语义的窗口。查看活动时间。stream.assignTimestamps (new TimeStampExtractor() {…}); |
| 选择 SplitStream→DataStream | 从拆分流中选择一个或多个流。SplitStream split;DataStream even = split.select(“even”);DataStream odd = split.select(“odd”);DataStream all = split.select(“even”,“odd”); |
| Window ApplyWindowedStream→DataStream AllWindowedStream→DataStream | 将一般函数应用于整个窗口。下面是一个手动求和窗口数据元的函数。注意:如果您正在使用windowAll转换,则需要使用AllWindowFunction。 |
二.案例分析
1.映射 DataStream→DataStream
/**
* @author ex_sunqi
*
*/
@Component
public class KafkaFlinkJob implements ApplicationRunner {
private final static Logger logger = LoggerFactory.getLogger(KafkaFlinkJob.class);
@SuppressWarnings("all")
@Override
public void run(ApplicationArguments args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(6000);
env.setStateBackend( new FsStateBackend("file:///opt/tpapp/flinkdata", true ));
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.setParallelism(1);
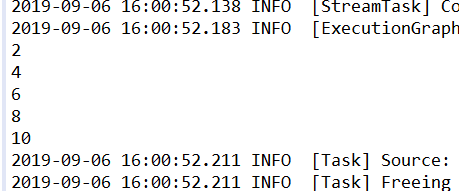
DataStream<Integer> sourceStream = env.fromElements(1, 2, 3, 4, 5);
DataStream<Integer> dataStream=sourceStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
dataStream.print();
env.execute("flink-score-job");
}
}
结果:
2.FlatMap DataStream→DataStream
/**
* @author ex-sunqi
*
*/
@Component
public class KafkaFlinkJob implements ApplicationRunner {
private final static Logger logger = LoggerFactory.getLogger(KafkaFlinkJob.class);
@Autowired
private Properties kafkaProps;
@SuppressWarnings("all")
@Override
public void run(ApplicationArguments args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(6000);
env.setStateBackend( new FsStateBackend("file:///opt/tpapp/flinkdata", true ));
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.setParallelism(1);
DataStream<String> sourceStream = readFromKafka(env,kafkaProps);
logger.info("************************获取到kafka数据开始转换业务数据*********************************");
DataStream<String> dataStream=sourceStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)
throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
logger.info("************************获取到kafka数据转换业务数据结束*********************************");
dataStream.print();
env.execute("flink-score-job");
}
public static DataStream<String> readFromKafka(StreamExecutionEnvironment env,Properties kafkaProps) {
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer09<>("score-topic-1", new SimpleStringSchema(), kafkaProps))
.name("kafka-source")
.setParallelism(1);
return stream;
}
}
结果:

3.Filter DataStream→DataStream
/**
* @author ex_sunqi
*
*/
@Component
public class KafkaFlinkJob implements ApplicationRunner {
private final static Logger logger = LoggerFactory.getLogger(KafkaFlinkJob.class);
@Autowired
private Properties kafkaProps;
@SuppressWarnings("all")
@Override
public void run(ApplicationArguments args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(6000);
env.setStateBackend( new FsStateBackend("file:///opt/tpapp/flinkdata", true ));
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.setParallelism(1);
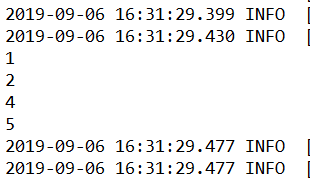
DataStream<Integer> sourceStream = env.fromElements(1, 2, 3, 4, 5);
DataStream<Integer> dataStream =sourceStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 3;
}
});
dataStream.print();
env.execute("flink-score-job");
}
}
结果:
4.生产者测试类
/**
* @author ex_sunqi
*
*/
public class ProducerTest {
@Test
public void msgSendTest() throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "XX.XX.XX.XX:XXXX"); //kafka服务地址
props.put("acks", "1");//leader收到消息,表示消息发送成功;all所有分区节点收到消息,表示消息发送成功。
props.put("retries", 3);
props.put("batch.size", 8388608);//8M 发送消息最大size
props.put("linger.ms", 20);//20ms触发一次消息发送
props.put("max.request.size", 16777216);//16M 生产者发送请求的大小
props.put("buffer.memory", 67108864);//64M 生产者内存缓冲区大小
props.put("session.timeout.ms", "48000000");
props.put("request.timeout.ms", "72000000");//消息发送的最长等待时间
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
String msg = "aa bb cc" ;
//生产消息发送kafka主题 score-topic-1
producer.send(new ProducerRecord<String, String>("score-topic-1", "score-key", msg), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (metadata != null) {
System.out.println("发送成功:offset: "+metadata.offset()+" partition: "+metadata.partition()+" topic: "+metadata.topic());
}
if (exception != null) {
System.out.println("异常:"+exception.getMessage());
}
}
});
Thread.sleep(40);
producer.close();
}
}