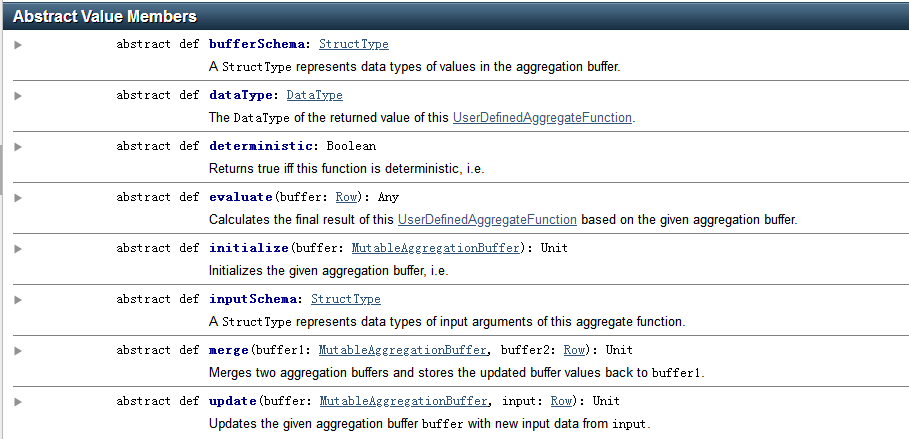
样例代码:
import java.util.ArrayList; import java.util.List; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.expressions.MutableAggregationBuffer; import org.apache.spark.sql.expressions.UserDefinedAggregateFunction; import org.apache.spark.sql.types.DataType; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; public static class MyAverage extends UserDefinedAggregateFunction { private StructType inputSchema; private StructType bufferSchema; public MyAverage() { List<StructField> inputFields = new ArrayList<>(); inputFields.add(DataTypes.createStructField("inputColumn", DataTypes.LongType, true)); inputSchema = DataTypes.createStructType(inputFields); List<StructField> bufferFields = new ArrayList<>(); bufferFields.add(DataTypes.createStructField("sum", DataTypes.LongType, true)); bufferFields.add(DataTypes.createStructField("count", DataTypes.LongType, true)); bufferSchema = DataTypes.createStructType(bufferFields); } // Data types of input arguments of this aggregate function public StructType inputSchema() { return inputSchema; } // Data types of values in the aggregation buffer public StructType bufferSchema() { return bufferSchema; } // The data type of the returned value public DataType dataType() { return DataTypes.DoubleType; } // Whether this function always returns the same output on the identical 相同的 input public boolean deterministic() { return true; } // Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to // standard methods like retrieving 获取 a value at an index (e.g., get(), getBoolean()), provides // the opportunity 方式 to update its values. Note that arrays and maps inside the buffer are still // immutable 不可变的. public void initialize(MutableAggregationBuffer buffer) { buffer.update(0, 0L); buffer.update(1, 0L); } // Updates the given aggregation buffer `buffer` with new input data from `input` public void update(MutableAggregationBuffer buffer, Row input) { if (!input.isNullAt(0)) { long updatedSum = buffer.getLong(0) + input.getLong(0); long updatedCount = buffer.getLong(1) + 1; buffer.update(0, updatedSum); buffer.update(1, updatedCount); } } // Merges two aggregation buffers and stores the updated buffer values back to `buffer1` public void merge(MutableAggregationBuffer buffer1, Row buffer2) { long mergedSum = buffer1.getLong(0) + buffer2.getLong(0); long mergedCount = buffer1.getLong(1) + buffer2.getLong(1); buffer1.update(0, mergedSum); buffer1.update(1, mergedCount); } // Calculates the final result public Double evaluate(Row buffer) { return ((double) buffer.getLong(0)) / buffer.getLong(1); } } // Register the function to access it spark.udf().register("myAverage", new MyAverage()); Dataset<Row> df = spark.read().json("examples/src/main/resources/employees.json"); df.createOrReplaceTempView("employees"); df.show(); // +-------+------+ // | name|salary| // +-------+------+ // |Michael| 3000| // | Andy| 4500| // | Justin| 3500| // | Berta| 4000| // +-------+------+ Dataset<Row> result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees"); result.show(); // +--------------+ // |average_salary| // +--------------+ // | 3750.0| // +--------------+