自定义聚合函数 UDAF 目前有点麻烦,PandasUDFType.GROUPED_AGG 在2.3.2的版本中不知怎么回事,不能使用!
这样的话只能曲线救国了!
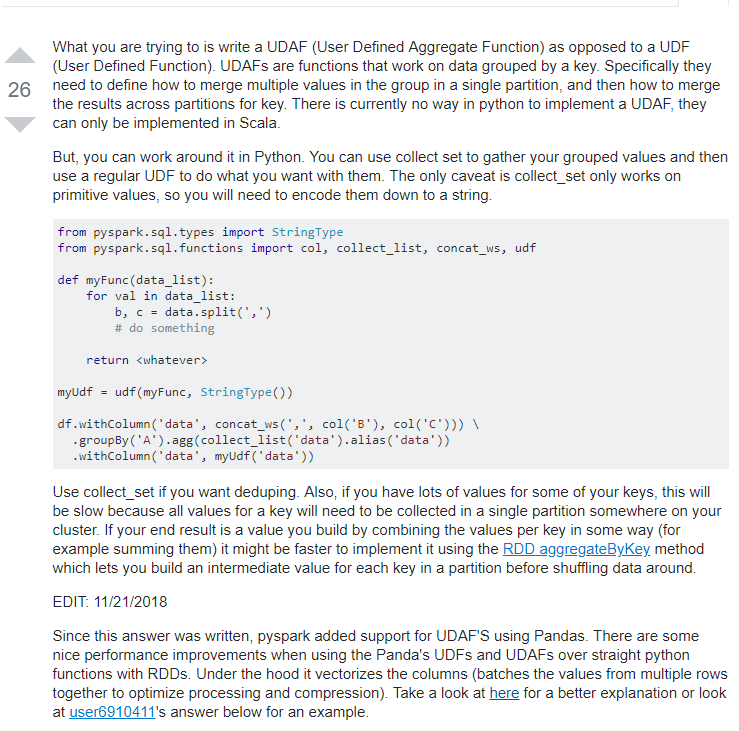
PySpark有一组很好的聚合函数(例如,count,countDistinct,min,max,avg,sum),但这些并不适用于所有情况(特别是如果你试图避免代价高昂的Shuffle操作)。
PySpark目前有pandas_udfs,它可以创建自定义聚合器,但是你一次只能“应用”一个pandas_udf。如果你想使用多个,你必须预先形成多个groupBys ......并且避免那些改组。
在这篇文章中,我描述了一个小黑客,它使您能够创建简单的python UDF,它们对聚合数据起作用(此功能只应存在于Scala中!)。
1
2
3
4
5
6 7 8 |
|
| ID | 值 |
|---|---|
| 1 | '一个' |
| 1 | 'B' |
| 1 | 'B' |
| 2 | 'C' |
我使用collect_list将给定组中的所有数据放入一行。我打印下面这个操作的输出。
1
|
|
| ID | VALUE_LIST |
|---|---|
| 1 | ['a','b','b'] |
| 2 | ['C'] |
然后我创建一个UDF,它将计算这些列表中字母'a'的所有出现(这可以很容易地在没有UDF的情况下完成,但是你明白了)。此UDF包含collect_list,因此它作用于collect_list的输出。
1
2
3
4
5
6 7 8 9 10 11 |
|
| ID | A_COUNT |
|---|---|
| 1 | 1 |
| 2 | 0 |
我们去!作用于聚合数据的UDF!接下来,我展示了这种方法的强大功能,结合何时让我们控制哪些数据进入F.collect_list。
首先,让我们创建一个带有额外列的数据框。
1
2
3
4
5
6 7 8 9 |
|
| ID | 值1 | 值2 |
|---|---|---|
| 1 | 1 | '一个' |
| 1 | 2 | '一个' |
| 1 | 1 | 'B' |
| 1 | 2 | 'B' |
| 2 | 1 | 'C' |
请注意,我如何在collect_list中包含一个when。请注意,UDF仍然包含collect_list。
1
|
|
| ID | A_COUNT |
|---|---|
| 1 | 1 |
| 2 | 0 |
https://danvatterott.com/blog/2018/09/06/python-aggregate-udfs-in-pyspark/
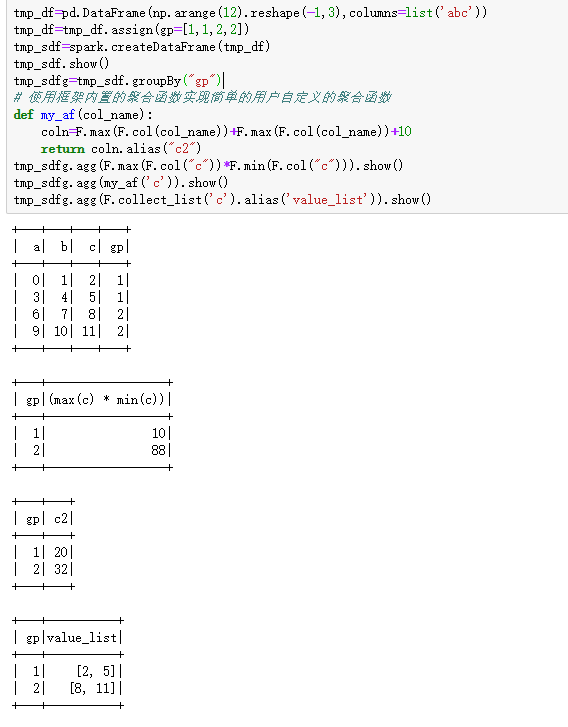
还有一种做法就是用pandas_udf, 然后按照聚合的得到的列去重