CPU多级缓存
一、CPU缓存的意义
CPU多级缓存 属于《计算机组成原理》部分的内容,但却是深入理解Java并发编程绕不开的部分。
我们了解,虽然CPU、内存、I/O 设备发展都很迅速,但是它们之前的速度差距依然是数量级的,CPU的速度远高于内存的速度,内存的速度远高于I/O设备。无奈的是程序整体的性能取决于最慢的操作——读写 I/O 设备,也就是说单方面提高 CPU 性能是无效的。
为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系机构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU 增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
本文的重点是CPU的缓存,第三部分的CPU的乱序执行的优化,要与编译程序优化指令执行次序区分开来
关于CPU缓存:
CPU缓存是位于CPU与内存之间器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU缓存一般直接跟CPU芯片集成或位于主板总线互连的独立芯片上。
左图为最简单的高速缓存的配置,数据的读取和存储都经过高速缓存,CPU核心与高速缓存有一条特殊的快速通道;主存与高速缓存都连在系统总线上(BUS)这条总线还用于其他组件的通信
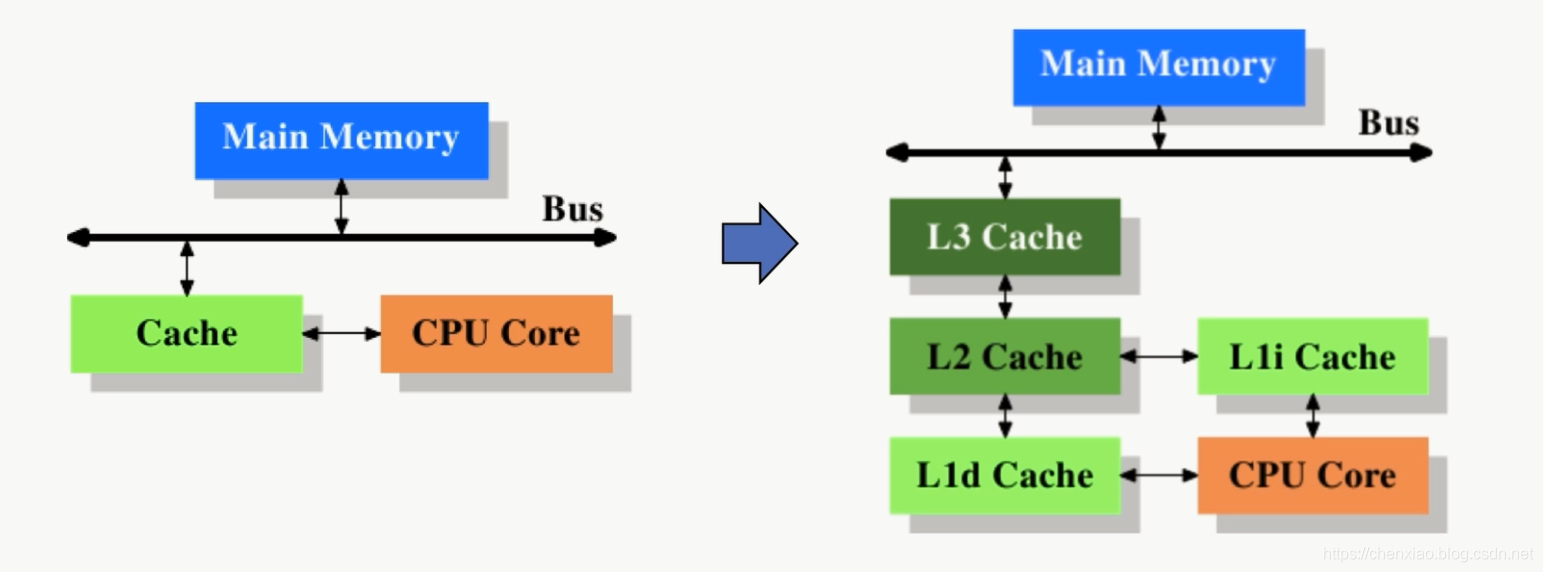
在高速缓存出现后不久,系统变得越来越复杂,高速缓存与主存之间的速度差异被拉大,直到加入了另一级缓存,但是新加入的这级缓存比第一缓存更大,并且更慢。
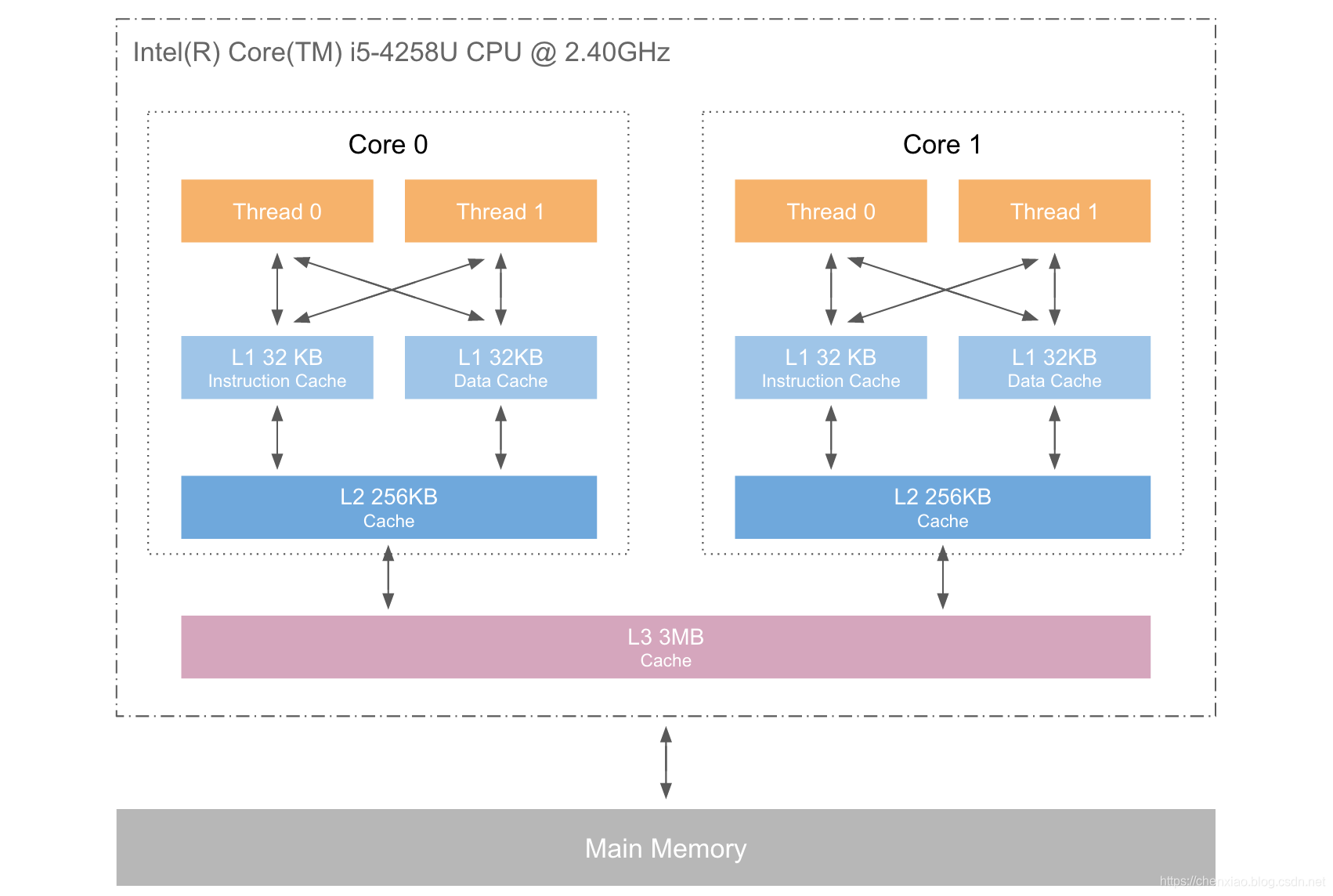
于是随着多核CPU的发展,CPU缓存通常分成了三个级别:L1,L2,L3。级别越小越接近CPU,所以速度也更快,同时也代表着容量越小。L1 是最接近CPU的, 它容量最小(例如:32K),速度最快,每个核上都有一个 L1 缓存,L1 缓存每个核上其实有两个 L1 缓存, 一个用于存数据的 L1d Cache(Data Cache),一个用于存指令的 L1i Cache(Instruction Cache)。L2 缓存 更大一些(例如:256K),速度要慢一些, 一般情况下每个核上都有一个独立的L2 缓存; L3 缓存是三级缓存中最大的一级(例如3MB),同时也是最慢的一级, 在同一个CPU插槽之间的核共享一个 L3 缓存。
下面是三级缓存的处理速度参考表:
归根到底,CPU缓存就是缓解cpu与主存之间速度不匹配的问题,减少CPU等待时间,提高性能。
CPU 的缓存的意义(也是能够缓解cpu与主存之间速度不匹配的问题的原因) 可以从局部性原理看:
1)时间局部性:如果某个数据被访问,那么在不久的将来它很可能被再次访问
2)空间局部性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问
既然涉及到数据的缓存了,必定绕不开缓存的一致性问题。
二、CPU缓存一致性协议(MESI)
MESI(Modified Exclusive Shared Or Invalid)是一种广泛使用的支持写回策略的缓存一致性协议。
为了保证多个CPU缓存中共享数据的一致性,MESI定义了缓存行(Cache Line)的四种状态,而CPU对缓存行的四种操作可能会产生不一致的状态,因此缓存控制器监听到本地操作和远程操作的时候,需要对地址一致的缓存行的状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。
MESI协议中的状态
CPU中每个缓存行(Caceh line)使用4种状态进行标记,使用2bit来表示:,下面的这张图是从网上搜集资料找到的,说的很具体,但是不好理解。

根据下面的图解释一下
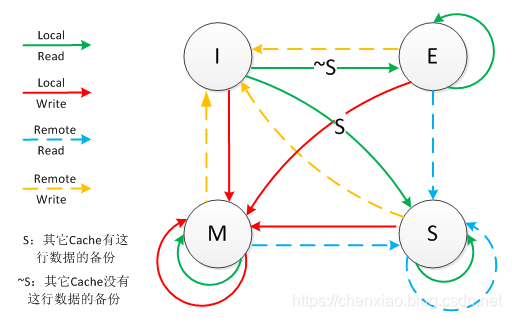
M:Modified 修改,指的是该缓存行只被缓存在该CPU的缓存中,并且是被修改过的,因此它与主存中的数据是不一致的,该缓存行中的数据需要在未来的某个时间点(允许其他CPU读取主存相应中的内容之前)写回主存,然后状态变成E(独享)
E:Exclusive 独享 缓存行只被缓存在该CPU的缓存中,是未被修改过的,与主存的数据是一致的,可以在任何时刻当有其他CPU读取该内存时,变成S(共享)状态,当CPU修改该缓存行的内容时,变成M(被修改)的状态
S:Share 共享,意味着该缓存行可能会被多个CPU进行缓存,并且该缓存中的数据与主存数据是一致的,当有一个CPU修改该缓存行时,其他CPU中该缓存行是可以作废的,变成I(无效的)
I:Invalid 无效的,代表这个缓存是无效的,可能是有其他CPU修改了该缓存行
关于Local Read、Local Write、Remote Write、Remote Read其实是MESI状态转换,这里我们肯定要好好说一下。
Local Read指的是读本地缓存中的数据
Local Write指的是将数据写到本地缓存里面
Remote Write指的是将内存中的数据读取过来
Remote Read指的是将数据写到内存中去
下图表示了当一个缓存行(Cache line)的调整的状态的时候,其他的该缓存行(Cache line)需要调整的状态,一共16种状态。(这里还是要强调一下,我们这里说的一直是多核CPU)
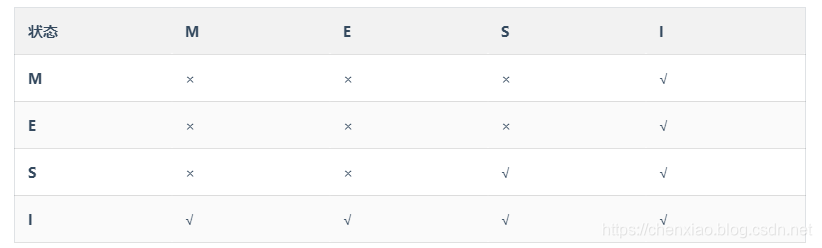
对于M和E状态而言总是精确的,它们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。
如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务。
三、CPU的乱序执行
这个其实是CPU为提高运算速度而做出违背代码原有顺序的优化。(下面的例子,假设编译器没有进行编译优化)
比如下面的代码:
#include<stdio.h>
int main(){
int a = 1;
int b = 200;
int result = a * b;
return 0;
}
正常来说,应该是 a = 10 --> b = 200 --> 计算出result = a * b
但实际可能会这样执行 b = 200 --> a = 10 --> 计算出result = a * b
代码是比较简单的,单核CPU下,这种优化不会出现什么问题,但是如果是多核CPU的话,首先每个核中执行的指令都可能是乱序的,其次每个核还有缓存,如果不做任何防护措施,肯定会出问题的。