1 业务高可用的保障:异地多活架构
高可用计算架构和高可用存储架构,其本质的设计目的都是为了解决部分服务器故障的场景下,如何保证系统能够继续提供服务。
但在一些极端场景下,有可能所有服务器都出现故障。例如,典型的有机房断电、机房火灾、地震、水灾……这些极端情况会导致某个系统所有服务器都故障,或者业务整体瘫痪,而且即使有其他地区的备份,把备份业务系统全部恢复到能够正常提供业务,花费的时间也比较长,可能是半小时,也可能是 12 小时。因为备份系统平时不对外提供服务,可能会存在很多隐藏的问题没有发现。
如果业务期望达到即使在此类灾难性故障的情况下,业务也不受影响,或者在几分钟内就能够很快恢复,那么就需要设计异地多活架构。
1.1 概念
异地就是指地理位置上不同的地方,类似于“不要把鸡蛋都放在同一篮子里”;
多活就是指不同地理位置上的系统都能够提供业务服务,这里的“活”是活动、活跃的意思。
判断一个系统是否符合异地多活,需要满足两个标准:
- 正常情况下,用户无论访问哪一个地点的业务系统,都能够得到正确的业务服务。
- 某个地方业务异常的时候,用户访问其他地方正常的业务系统,能够得到正确的业务服务。
1.2 架构模式
根据地理位置上的距离来划分,异地多活架构可以分为同城异区、跨城异地、跨国异地。
1.2.1 同城异区
将业务部署在同一个城市不同区的多个机房,然后将几个机房用专用的高速网络连接在一起。
同城的两个机房,距离上一般大约就是几十千米,通过搭建高速的网络,同城异区的两个机房能够实现和同一个机房内几乎一样的网络传输速度。这就意味着虽然是两个不同地理位置上的机房,但逻辑上可以将它们看作同一个机房,这样的设计大大降低了复杂度,减少了异地多活的设计和实现复杂度及成本。
1.2.2 跨城异地
跨城异地指的是业务部署在不同城市的多个机房,而且距离最好要远一些。
可以解决极端事件
对数据一致性要求不那么高,或者数据不怎么改变,或者即使数据丢失影响也不大的业务,跨城异地多活就可以使用
1.2.3 跨国异地
业务部署在不同国家的多个机房。
用来为不同地区用户提供服务(淘宝中国、淘宝美国)、只读类业务做多活(搜索引擎)
1.2.4 疑问
假设做了前面提到的高可用存储架构中的数据分区备份,又通过自动化运维能够保证 1 分钟就能将全部系统正常启动,那是否意味着没有必要做异地多活了?
不是,原因如下:
1 备份系统平常没有流量,如果直接上线可能触发平常测试不到的bug
2 再实时的系统也会有数据延时,如果涉及到金融这种系统,仍然是不敢直接切换的。
3 系统运行过程中会有很多中间数据,缓存数据等。系统不经过预热直接把流量倒过来,大流量会直接把系统拖垮
2 异地多活四大设计技巧
2.1 技巧一:保证核心业务的异地多活
如果所有业务都要实现的话是很难的,有些问题甚至是无解的,因此要优先实现核心业务的异地多活架构
2.2 技巧二:保证核心数据最终一致性
异地多活理论上不可能很快,因为这是物理定律决定的,因此就有一个矛盾:业务上要求数据快速同步,物理上正好做不到数据快速同步,因此所有数据都实时同步,实际上是一个无法达到的目标
尽量减少影响的方法:
尽量减少异地多活机房的距离,搭建高速网络
尽量减少数据同步,只同步核心业务相关的数据
保证最终一致性,不保证实时一致性
2.3 技巧三:采用多种手段同步数据
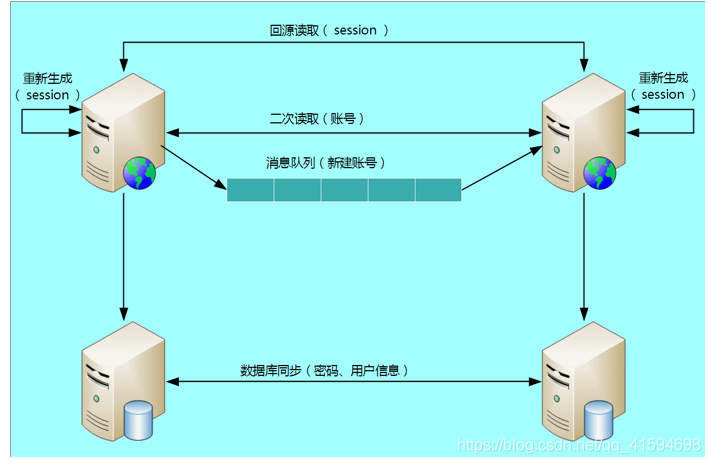
数据同步是异地多活架构设计的核心,而存储系统本身自带的同步功能,在某些场景下是无法满足业务需要的,因此要避免只使用存储系统的同步功能,可以将多种手段配合存储系统的同步来使用,甚至可以不采用存储系统的同步方案,改用自己的同步方案。
方式:
消息队列方式
二次读取方式
存储系统同步方式
回源读取方式
重新生成数据方式
如用户子系统:
2.4 技巧 4:只保证绝大部分用户的异地多活
异地多活无法保证 100% 的业务可用,这是由物理规律决定的
无法做到 100% 可用性,只能采取一些措施对用户进行安抚或者补偿
2.5 核心思想
采用多种手段,保证绝大部分用户的核心业务异地多活,根据经济能力、所需时间及业务要求有先后地选择异地多活的业务及业务多活的形式。
3 异地多活设计四步骤
3.1 第一步:业务分级
按照一定的标准将业务进行分级,挑选出核心的业务,只为核心业务设计异地多活,降低方案整体复杂度和实现成本。
常见的分级标准:
访问量大的业务
核心业务
产生大量收入的业务
3.2 第二步:数据分类
挑选出核心业务后,需要对核心业务相关的数据进一步分析,目的在于识别所有的数据及数据特征,这些数据特征会影响后面的方案设计。
常见的数据特征分析维度有:
数据量
唯一性
实时性
可丢失性
可恢复性
3.3 第三步:数据同步
确定数据的特点后,可以根据不同的数据设计不同的同步方案。
常见的数据同步方案有:
存储系统同步
消息队列同步:适合无事务性或者无时序性要求的数据。
重复生成
3.4 第四步:异常处理
异常处理主要有以下几个目的:
问题发生时,避免少量数据异常导致整体业务不可用。
问题恢复后,将异常的数据进行修正。
对用户进行安抚,弥补用户损失。
常见的异常处理措施:
多通道同步,一般为双
同步和访问结合
日志记录
用户补偿
4 接口故障
异地多活方案主要应对系统级的故障,例如,机器宕机、机房故障、网络故障等问题,这些系统级的故障虽然影响很大,但发生概率较小。
而接口级的故障在实际业务运行过程中,影响可能没有系统级那么大,但发生的概率较高
典型表现:系统并没有宕机,网络也没有中断,但业务却出现问题了。
原因:
内部原因:程序bug,数据库慢查询
外部原因:黑客攻击,双十一、第三方系统问题
解决问题的核心思想和异地多活基本类似:优先保证核心业务和优先保证绝大部分用户。
降级
熔断
限流
排队
4.1 案例
设计一个整点限量秒杀系统,包括登录、抢购、支付(依赖支付宝)等功能,如何设计接口级的故障应对手段?
1 对于用户服务,在抢购期间可以准备降级策略,压力过大时保证用户登录的可用,注册和修改信息可以做降级处理
2 抢购下单涉及到订单,库存,和商品查询。可通过请求排队来限流,超出库存的请求直接返回或排队
为了应对库存和商品服务可能发生的故障,可以提前对商品数据和库存数据做缓存,如果对端服务故障,本地也可以提供服务3 支付依赖第三方系统,合理设置熔断策略,做出补偿或容错措施,如支付平均时长超过限制可提示用户稍晚做支付