声明:纯属个人收藏用!
什么是大数据
大数据只是一个空洞的商业术语,就跟所谓的商业智能一样空洞无物。当然,这并不是说大数据没有意义,只是对于不同的人有不同的含义。
A.
对于投资人和创业者而言,大数据是个热门的融资标签。就和前几年流行的 SoLoMo,这几年火爆的 P2P 一样,大数据是资本泡沫的催化剂。如今任何一家(移动)互联网公司都忙着把自己标榜为大数据公司,或者干脆说自己是一家数据公司。遗憾的是,大多数中国的互联网公司都是流量驱动的企业。与其说这些公司是大数据公司,不如说它们是数据采集公司。是的,每一家互联网公司都是数据公司,因为数据(Data)是比信息(Information)要狭隘得多的词汇。换句话说,任何一家 IT 行业的公司天然地都是数据公司。但是非 IT 公司同样可以是数据公司,例如房地产企业和汽车销售公司——毕竟他们优质低价地将顾客的信息转卖给任何感兴趣的个人或实体。遗憾的是,中国并没有几家 Pure-Play 的数据公司,因此中国不太可能出现 Palantir 这样伟大的企业。我不幸见过一两家国产独角兽企业的技术/数据负责人,他们似乎并不了解这家 CIA 投资的创业公司,但这并不妨碍他们把自己的公司定位为世界级的大数据公司。我可以臆测,国内这些独角兽企业的道德底线远远低于(为美帝情报机构服务的) Palantir,只是它们还没有足够的人才和技术来充分挖掘数据中的有效信息。
对于大多数互联网公司或者工程师而言,大数据实际上只有一个意思,就是把一堆乱七八糟的数据扔到 HDFS 上面然后进行计算。计算的工具有很多,最常见的是 Map-Reduce,但是技术一直在演进,现在还流行 Impala、Spark、Presto 什么的。对于这些搞大数据的工程师而言,这是一个非常好的事情,因为要把这么多异构的数据和系统跑起来,需要很多人写很多代码,还需要有人来做运维。这么一个部门总得需要几十台机器否则还不如单机计算能力强,工程师也得有十来人。然后可能还需要数据分析师,否则这部门跟摆设也没什么区别。如果系统做得不错数据量也有了,总得配个数据科学家搞点数据挖掘或者机器学习什么的吧。所以大数据这件事情可以解决很多就业问题,毕竟很多上了规模的互联网公司都想搞大数据。
但是对于消费者或者互联网所谓的“用户”来说,大数据却是另外一个意思。大数据的意思就是尽可能地搜集跟终端消费者相关的隐私,然后进行营销。从理论上说,大数据公司通过搜集用户行为,可以更好地了解消费者的需求,增强用户体验。但是在实践上,这些所谓的智能推荐还停留在很初级的阶段,因此会有人在淘宝上搜索棺材结果在微博上不停地看到跟丧葬相关的广告。对于微博这样的公司,还意味着它会倾向于通过直接或者间接地暴露你的隐私来获得商业利益。据说,评价一家国内公司的大数据能力是跟被查水表的频繁程度正相关的。就目前而言,大数据对于终端消费者更多的是“被实名”。举一个例子,如果你在 Android 手机上使用 Facebook 账号访问某个 App,那么对不起,你在这个手机上的所有行为都有可能被 Facebook 关联到你真实的身份上。在这种能力上,国内的三巨头排序大概是 T > A >> B。所以最后这家公司的 App 特别流氓甚至超越了数字公司,如果你想帮帮这家公司就多用用他家的地图或者订点外卖。
B.
关于大数据和隐私,最核心的问题在于标识(Identity),尤其是所谓的 PII (Personal Identifiable Information)。但是要对用户进行追踪并不一定需要 PII,任何一个强度足够高的随机数都可以用来追踪单个用户。在 Web 时代,由于 Cookie 的生命周期问题,对用户进行长期追踪并不是很容易。但是最近几年,越来越多的公司使用 Flash 来进行追踪,最终演进成一种叫做数字指纹的技术。要解释这些技术需要一些应用数学背景,知乎上应该可以找到相关的问答,我就不赘述了。我很想系统地讲述在使用桌面浏览器上如何保护自己的隐私,但是似乎离题太远了。但是我还是想提醒一句,在桌面浏览器上最有效的安全习惯就是禁用 Flash(当然,如果你出于安全装了数字公司的软件,那么你可以假装我说的都是废话——毕竟数字公司连你开机时间这种信息都不放过,更何况这家公司可是以所谓的“厚数据”而闻名的)。
身份到底有多重要呢?我可以说说我自己的一些非理性的习惯。大多数地铁一卡通都是不记名的,但是我以前会定期地破坏一卡通,从而避免在一卡通里积累过多的数据。但是由于我并不能很频繁地换卡,所以我这样的非理性行为是毫无用处的——你只需要读读我的卡就知道我住在哪里又在哪里上班,误差不会超过两公里。从技术上说,任何一张非接触卡都可以可能用于追踪我的身份,以及我所在的时空坐标。虽然我知道目前的技术并不能在超过一米的距离上读出我随身携带的卡片,但是我仍然把我身上所有的非接触卡放在一个金属的名片盒中。作为一个足够偏执的人,我更相信物理隔离。遗憾的是,这些非理性的习惯在移动时代都是徒劳的。
在移动时代,身份问题变成了最严重的问题,因为智能手机在很大程度上是私人设备。大多数人都随身携带这些设备,这就意味着设备的标识和个人几乎是一一对应的。在这个问题上,就连苹果公司都没能意识到其严重性,以至于在早期的苹果设备上有一个接近完美的唯一硬件标识(UDID)。这就意味着所有的 App 开发者都可以使用这个标识来追踪设备和交换数据。换句话说,只要你在一个 App 中使用了 Facebook 账号或者提交了电话号码,那么你在这个设备中的所有行为都有可能被关联到你的 PII。苹果直到两年以前才堵上这个漏洞,并通过所谓的 IDFA 来替代 UDID。我并不喜欢苹果公司,但是我在这里提这个案例并不是为了贬低苹果公司。事实上,苹果公司是所有的智能手机制造商中最尊重用户隐私的那一家,没有之一。原因很简单,苹果公司并不是一家互联网公司,它是通过向消费者出售手机来获利的。苹果公司的硬件利润非常高,它不需要通过 App Store 和广告来获利,因此 Tim Cook 才会有底气地讨论消费者的隐私问题。而 Google 则不同,它是一家广告公司,它甚至会通过分析用户的邮件来进行精准广告投放。我并不想把 Google 妖魔化成一个侵犯消费者隐私的寡头,但是 Google 的不作为让 Android 成为了地球上最伟大的监控平台。Android 上的确没有 UDID 这么高质量的标识,但是它允许开发者直接获取 IMEI——利用 IMEI 理论上可以通过运营商获取手机号码,并且进行实时的监控。此外 Android 还允许开发者获取 MAC 地址和 Android ID 这些标识,而前者可以用于基于 Wi-Fi 的地理位置定位。这些看起来很糟糕,但还不是最糟糕的,因为 Android 还允许开发者获取安装应用列表、正在运行应用列表。换句话说,Android 不仅允许开发者监控自己的 App 使用情况,还可以监控其他的 App 的使用情况,这可是字面上的情报工作。这些在技术层面上都是 Android 允许的,对于已 Root 设备或者能够利用漏洞提权的 App 而言,Android 提供的想象空间几乎是无限的。
有些读者评论扯 Google 的 IDFA 对应物,那我举个 Google 平台上的栗子吧:
近日,多个与TalkingData合作的厂商表示在Google Play发布的产品于2016年5月25日凌晨陆续被下架。且下架的说明邮件里称:“违反了开发者条款”并指出是TalkingData的SDK的问题所导致。
TalkingData回应SDK导致下架:GooglePlay审核调整
这家公司更是毫不掩饰地展示自己侵犯隐私的能力:
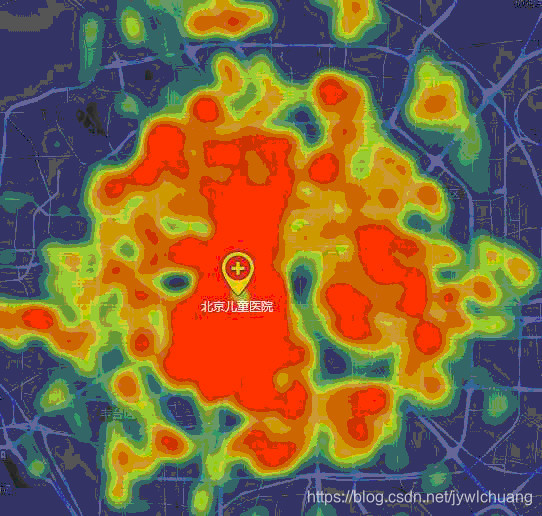
TalkingData-行为地图
那么问题来了,大家觉得他们的数据是哪里来的呢,是苹果用户还是安卓用户呢?
为了避免引起恐慌,这家公司的客户主要是某些银行和游戏,市场覆盖率并不是特别高。BAT 任何一家拥有的隐私数据都能秒杀这家公司,所以大家请保持内心的平静,睡觉前多玩玩手机。
C.
想象有这么一家智能手机厂商,它以极低的价格出售 Android 智能手机,它还声称自己是一家互联网公司,并且标榜自己是一家大数据公司。那么,这样的公司为什么会销售无线路由器呢?其实我说的不是国内的公司,而是 Google。当然这并不是什么秘密,有一段时间所有的互联网公司都想为用户提供所谓的智能路由器。
理由很充分,Wi-Fi 技术是以兼容以太网为目的局域网组网方案,它从来没有考虑过隐私和所谓的大数据带来的问题。以太网提供了一个高强度的网卡标识(即所谓的 MAC),理论上能提供 48 位的地址空间,从实际来说也足够所有的网卡制造商唯一地标识每一张网卡。最初这个网卡标识的设计目的是为了区分不同的设备,将冲突降到最低,因此对于给定的网卡,这个标识应该是永久不变的。这个标识在有线网络时代从来都不是一个真正的问题,因为 MAC 仅用于局域网通讯,任何设备在互联网上只会暴露 IP。为了无缝地兼容以太网,Wi-Fi 设备继承了这个标识,并且在扫描无线接入点的时候广播这个标识。换句话说,你随身携带的智能手机有一个几乎独一无二的永久标识,并且倾向于广播这个标识。因此对于很多大数据公司而言,这比你在脸上写着自己的姓名还要好得多。所以,苹果在最近的一次升级中改变了策略,所有的苹果手机在扫描热点的时候都会使用一个临时的 MAC。苹果这样做对于保护消费者的隐私很有帮助,但是离解决这个问题还很远。当苹果设备连接一个热点(例如咖啡厅里的免费热点)的时候,它依然会使用一个固定的网卡标识。
一个平庸的无线网卡标识为什么会跟大数据扯上关系呢?出乎标准设计者的意料,Wi-Fi 已经成为了一种主流的互联网接入方式,并且成了一种重要的辅助定位技术。不同于智能设备,大多数无线热点都是固定不动的,并且覆盖了都市的大多数区域。利用无线热点的 SSID 和 MAC,加上从智能手机采集的 GPS 信息,地理信息服务商可以利用这些信息完成误差在百米以内的定位。在 GPS 不能覆盖的室内,Wi-Fi 定位几乎是首选的解决方案。从这个角度来看,Wi-Fi 定位是一个方便消费者的福音。但是 Wi-Fi 的技术设计决定了它不是一个匿名的定位技术,在定位的过程中 Wi-Fi 热点同样可以获得智能手机的无线标识。因此从另一个角度来看,Wi-Fi 热点的运营商可以获得智能手机的一个时空坐标。这样第三方就有可能追踪智能手机在城市中的轨迹,其效果甚至可以超越运营商的监控手段。但是这并不是最糟糕的,出于统计的需求,很多 Android App 还会采集手机的 Wi-Fi 网卡标识。这些数据有可能将用户的行为和时空轨迹联系在一起,从而造成严重的隐私风险。正如 Facebook 一样,智能手机的普及是 CIA/NSA 做梦也想不到的好事。现代人进入了一个自愿监控自己的伟大时代,A Brave New World。
Snowden 在讨论 XKeyscore 的时候,其实提到过 NSA 非常喜欢这一点:
EDITED TO ADD (9/18): Marcy Wheeler comments on the second story, noting that the NSA uses this capability to map MAC addresses.
Two New Snowden Stories
当然,得益于 Palantir 的支持,NSA 的 SIGINT 能力已经不再是 Snowden 能够想象的了。
D.
让我用一个思维实验来展示一个 Android 用户在这个大数据生态链中的位置吧(当然任何一个读者都可以亲自尝试,用 iPhone 手机效果会大打折扣)。某个周末,你来到了某个商场,在一个咖啡厅里面点了一杯咖啡,然后开始用智能手机上网。咖啡厅提供了免费 Wi-Fi 网络,由于法规要求需要你提供手机号进行实名认证,你毫不犹豫地输入了手机号。于是免费 Wi-Fi 的服务商知道了你的信息:你的手机号和智能手机的 MAC。然后你开始刷微博,由于微博的 API 通常不使用加密信道,于是 Wi-Fi 热点通过偷窥 HTTP 请求获得了你的微博账号。通过你的微博,Wi-Fi 服务商有可能了解你的性别年龄工作等信息。此外通过该热点请求的很多元信息都会被服务商保留,虽然它们未必知道怎么挖掘这些元信息,但是它们会尽量将你的身份和这些信息关联在一起并长期保留。喝完咖啡,你开始逛街,这时候你的手机会开始扫描热点,商场可以通过 Wi-Fi 探针追踪你的位置。如果商场使用的 Wi-Fi 服务商和咖啡厅是同一家,或者与服务商建立了数据交换的协议,那么商场有可能实名地追踪你的轨迹。商场的 Wi-Fi 服务商同样会非常有耐心地存储你的信息,以备不时之需。在逛街的过程中,你打开了一些购物 App 用于比价,顺便拍了一些照片发给好友。其中一些 App 会把你的 MAC 地址和通过 Wi-Fi 完成的定位信息也发送出去。如果存在一个完备的数据交易网络,任何对你感兴趣的人都有可能获得以下信息:你的电话号码、手机的 MAC、微博账号,何时出现在这个商场,在商场停留了多久,其间使用了哪些 App,在咖啡厅访问了哪些网站。而这一切都离不开 Wi-Fi 和 MAC。如果更极端一点,你使用了专车软件来这个商场,并且你经常来这家商场,那么你很可能已经在商场的常客数据库里了,你的家庭住址也不再是个秘密。
这个思维实验当然是虚构的,因为利益冲突无关公司之间很难达成信任,它们很少进行实质性的数据交换。但是寡头们可以通过收购和战略投资将第三方变成第二方,甚至亲自介入 Wi-Fi 热点的服务。利用这些数据和技术,大数据公司事实上可以将营销做到无孔不入。例如,利用上述信息,商场中的餐厅可以针对最近到过商场的用户推送折扣信息,并且根据情况选择短信或微博作为送达渠道。当然现实社会中的餐厅并不会走得这么远,它们更倾向于使用微信服务号一类的技术来建立会员机制。各种 P2P 金融公司、讨债公司对数据更加饥渴,它们会愿意为你的信息(尤其是位置信息)付大价钱。所以从某种意义上说,数据寡头更可能看重你的隐私的长期价值。
正因为如此,中国的三大寡头都参与了商业 Wi-Fi 的布局。除了微信 Wi-Fi,相信大多数人都没有注意过相关的报道。事实上新闻报道披露的仅仅是冰山一角。
本报讯公共交通领域最大的WIFI建设运营商16WIFI日前宣布,已完成由百度领投、荣之联等跟投的A轮融资,融资金额超过1亿元。这也标志着在商业WIFI领域,BAT(即百度、阿里、腾讯)再次到齐。
E.
还是来点轻松的吧,看看 Google 是怎么利用大数据投放精准广告的:
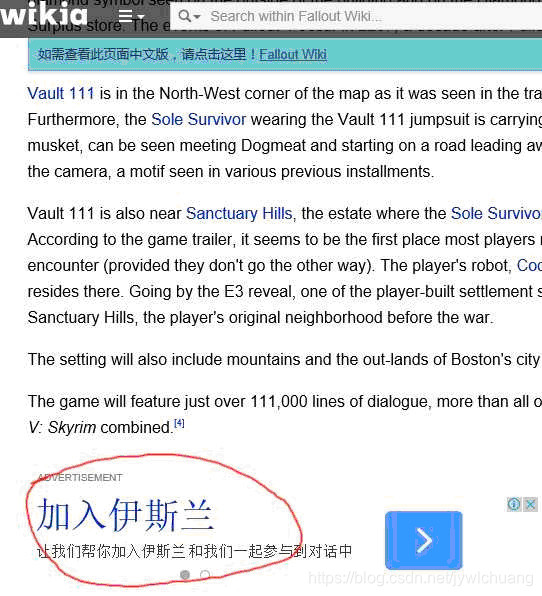
莫非喜欢 Fallout 的死宅更容易接受某教?我并不是想讽刺 Google 的算法或者宗教布道者的 SEM 策略,只是觉得这对于下面讨论的计算神学而言,是一个绝佳的隐喻。
计算神学是一种对计算的绝对信仰,其基本教义派别甚至认为整个宇宙都是一台量子计算机,可以用 Universal Wave Function 来完备地描述。在大数据流行起来之前,计算神学属于边缘学科(或者说伪科学),几乎无人问津。但是在大数据时代,计算能力和数据量都不再是问题,计算神学一下就成了主流的意识形态。经过大数据修正过的计算神学摒弃了科学的实证主义传统,试图将一切问题简化成数据处理。吊诡的是,很多计算神学的信徒获得了数据科学家的称号,这无异于将占星师当作天文学家,或者将炼金术士称为化学家(sadly, it was true before we had hard science)。
这些年我还真见过不少计算神学的布道者,他们开始张口就是大数据和机器学习,后来开始扯深度学习和人工智能。然而有一次我问某个信徒,他用的模型对性别的预测精度有多高,他居然诚实地回答接近 60%。如果需要考虑 Facebook 那么多种非常规的性别,这 60% 还是相当不错的,比扔硬币强不少呢。我之前的公司不幸跟某寡头有非平凡的合作,有幸跟对方的祭司阶级聊了几句,我发现这帮人对数据的理解连频率主义者都不如,连什么是信号什么是噪声都分不清楚。当然这圈子里面也有聪明人,并不是真诚地相信这些鬼话——据说某公司做了两三位数样本的问卷攒了份报告就卖了很多钱。
大数据是个系统工程,从采集数据到计算到应用到决策有很长的流水线。在这个流水线上的每一个环节,都存在严重的人才空缺。当然,更稀缺的是搞清楚整个流水线的综合性人才。计算神学的信徒们根本没有意识到这一点,或者他们也不关心。幸运的是,官僚们欣赏这些人的盲目乐观。所以这是个让人宽慰的好消息,这些个大数据公司里面还是以蠢货和官僚为主。
短期来说上述判断应该是靠谱的,至于更长期的我就不杞人忧天了。毕竟某位大师说过,in the long run, we are all dead.
所以,天朝把 Google 挡在外面是多么的英明神武啊。如果国内的公司都有了 AlphaGo 这样的暴力计算系统来搞大数据,我也该洗洗睡了改行做水管工算了。总体来说我还是一个悲观的存在主义者,要不了多久所有的 CCTV 都会成为面部识别算法的数据源。我感觉,计算神学训练出来的 AI 都是些反社会的自闭症患者,而不再是充满浪漫主义气息的面盲症患者。
我毫无痕迹地插入了一条原生公益广告:什么是自闭症?(请不要被我的修辞手法误导,自闭症患者几乎不可能反社会,而任何互联网广告系统都是天然反社会的。)。
Z.
评论里面有人问大数据有什么不侵犯隐私的用途,我觉得有必要澄清一下,我并不是在写一篇讨伐大数据的檄文。数据和分析能解决很多实际的问题,而且并不总是需要以隐私作为代价。但是技术几乎总是双刃剑,风险与机遇并存。说个相对远一点的,如果新的基因测序技术能将全基因组测学成本降到足够低,利用大数据技术将有可能定量地测量很多遗传疾病的基因风险,这可是造福人类的善举。但是,这也意味着保险公司可以更加精确地估计投保人的健康状况,换句话说可以利用这些信息来进行歧视(美国已经有相关的立法,禁止保险公司利用基因相关的隐私)。再说一个相对近一点的,某公司垄断了天朝的搜索市场,几乎是躺着在挣钱,但是为了追求利润什么骗子广告都愿意打,还会往用户的电脑上装几乎无法卸载的全家桶。几乎所有的人都在说大数据是一座金矿,但是很少有人意识到提炼金子是个技术活,而且现在很多矿山的黄金生产成本已经高于期货价格了(写于黄金价格低点 $1000 左右)。利用数据变现还是颇有技术含量的,用常理就可以推断守着金矿不能赚钱是个什么样的感觉。至少在天朝,真正的问题在于有很多没有技术的公司守着大量的数据干着急——它们其实也很想卖点假药什么的,但是它们能卖的也仅仅是用户的隐私。
据说,某些输入法会把你所有的输入都送回服务器,这样你也为大数据事业做出了贡献。现在大家应该很清楚,这些大数据都是从哪里来的了吧。
搜狗和百度输入法被爆泄露用户隐私
大数据 Big Data
据说,词源出自Alvin Toffler,上世纪70年代的作品《第三次浪潮》。
逝者 | 阿尔文•托夫勒:如何化解未来的冲击
虽然大数据是一个泛泛的概念词,但是关于大数据,关于大数据处理分析的话题近来持续升温,现在基本成了新一轮工业革命级别的话题。
大数据是什么,作为数据采集团队 ,我们很长的时间里一直也在思考,什么是大数据,大数据的前景和价值在哪里。
这篇文章里,我会跟大家一起分享我的看法以及各种有趣的内容和资源,它们关于:
- 什么是大数据
- 大数据的实践
- 大数据的应用场景
硬广:我们团队的帮助你零门槛采集数据:
造数 - 最好用的云爬虫工具 进击的爬虫工具!
最近都在说裁员,如果想知道互联网裁员潮对就业薪资是不是真的产生了持久的负面影响,可以用我们的工具,帮你定时每天采集几次生成列表看一看。
(一)什么是大数据
先听听行家的说法:
大数据就是多,就是多。原来的设备存不下、算不动。
————啪菠萝•毕加索
大数据,不是随机样本,而是所有数据;不是精确性,而是混杂性;不是因果关系,而是相关关系。_______Schönberger
移步ted:Kenneth Cukier: Big data is better data
America’s favorite pie is?
Audience: Apple. Kenneth
Cukier: Apple. Of course it is. How do we know it? Because of data. You look at supermarket sales. You look at supermarket sales of 30-centimeter pies that are frozen, and apple wins, no contest. The majority of the sales are apple. But then supermarkets started selling smaller, 11-centimeter pies, and suddenly, apple fell to fourth or fifth place. Why? What happened? Okay, think about it. When you buy a 30-centimeter pie, the whole family has to agree, and apple is everyone’s second favorite. (Laughter) But when you buy an individual 11-centimeter pie, you can buy the one that you want. You can get your first choice. You have more data. You can see something that you couldn’t see when you only had smaller amounts of it.
曾经人们以为最爱吃的派都是苹果派,不过当你有了更细致的数据,你会发现,苹果派受欢迎其实是一种妥协的结果:苹果派是每个人第二喜欢的口味。
拿到小尺寸派的数据以后你更发现,其实苹果派只能排到第四,第五位的样子了。
你有了更多数据,你就能看到之前你看不到的信息。
大数据最核心的价值是什么? - 商业 - 知乎 推荐@Han Hsiao这篇内容的结构十分清晰,对大数据的正面意义提出了非常清晰地探讨。
大数据听着很牛,实际上也很牛吗? - 人工智能 - 知乎 这里 @陈萌萌说的也特别好,怀疑她是不是真的是一个ai。
大数据最核心的价值是什么? - 商业 - 知乎,依然是这个问题, @刘飞的文章。
大数据是大数据的采集
大数据行业,本身是依托于数据源存在的服务性行业。
大数据最根本之处在于信息收集方式出现了重大变化与革新。大数据的出现与大量信息直接在网络呈现关系非常紧密。
微博、天猫、淘宝、微信等等都直接产生了大量包括定位、消息记录、消费记录、评价、阅读等等殊为庞大的信息,可以说互联网企业都自然的带有数据企业的标签。不过如果我们从数据的源头看的更仔细一些,还是会发现,其实很多数据依然是有巨大的采集与归类的需求。
Joel Selanikio:Transcript of "The big-data revolution in healthcare"
There’s a concept that people talk about nowadays called “big data.” And what they’re talking about is all of the information that we’re generating through our interaction with and over the Internet, everything from Facebook and Twitter to music downloads, movies, streaming, all this kind of stuff, the live streaming of TED. And the folks who work with big data, for them, they talk about that their biggest problem is we have so much information. The biggest problem is: how do we organize all that information?
现在人人都说大数据,但其实大家说的是 facebook,twitter,streaming 等等站点上每天产生的信息,做大数据的人呢,会觉得我们有的数据量实在太大了。
(组织信息仍然是最难的问题)
I can tell you that, working in global health, that is not our biggest problem. Because for us, even though the light is better on the Internet, the data that would help us solve the problems we’re trying to solve is not actually present on the Internet. So we don’t know, for example, how many people right now are being affected by disasters or by conflict situations. We don’t know for, really, basically, any of the clinicsin the developing world, which ones have medicines and which ones don’t. We have no idea of what the supply chain is for those clinics. We don’t know – and this is really amazing to me – we don’t know how many children were born – or how many children there are – in Bolivia or Botswana or Bhutan. We don’t know how many kids died last week in any of those countries. We don’t know the needs of the elderly, the mentally ill. For all of these different critically important problems or critically important areas that we want to solve problems in, we basically know nothing at all.
许多有效的数据还完全不在网络上,要依靠原始的方法来收集。数据方面还有很多基本层面的问题在非常多的领域非常明显。
有哪些「神奇」的数据获取方式? - Liu Cao 的回答 - 知乎 看到这里推荐一个 @Liu Cao
的回答。
严澜(lanceyan)的博客 - 技术分享 框架交流 大数据处理 架构搭建 机器人
强烈推荐:如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?其中 @Xiaoyu Ma
(二)大数据的实践
工具看这里:大数据分析一般用什么工具分析? - JavaScript - 知乎
最近看到个例子,说pokemon go 带给玩家运动量上的变化:
1、应用中的数据分析示例:•
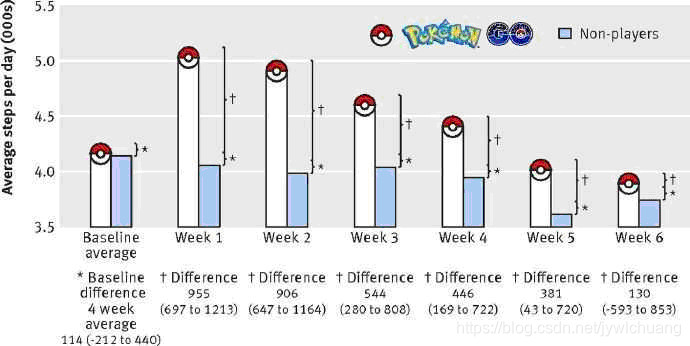
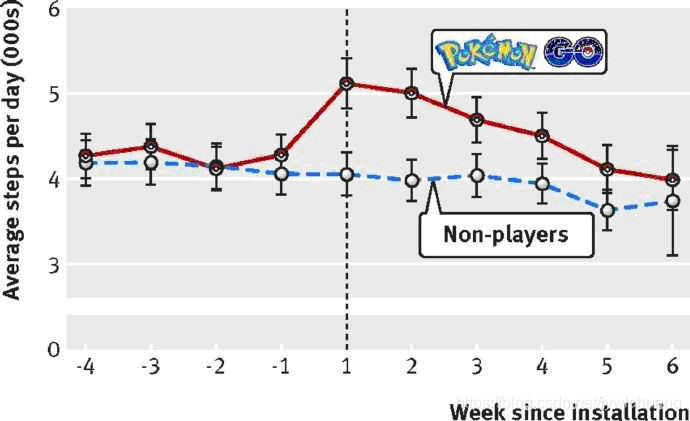
六个月以后,大部分pokemon go 的玩家的运动量逐渐和 non-player基本一致了。
看来确实是一个能用相当效果的游戏。
2、交通状况大数据分析示例:
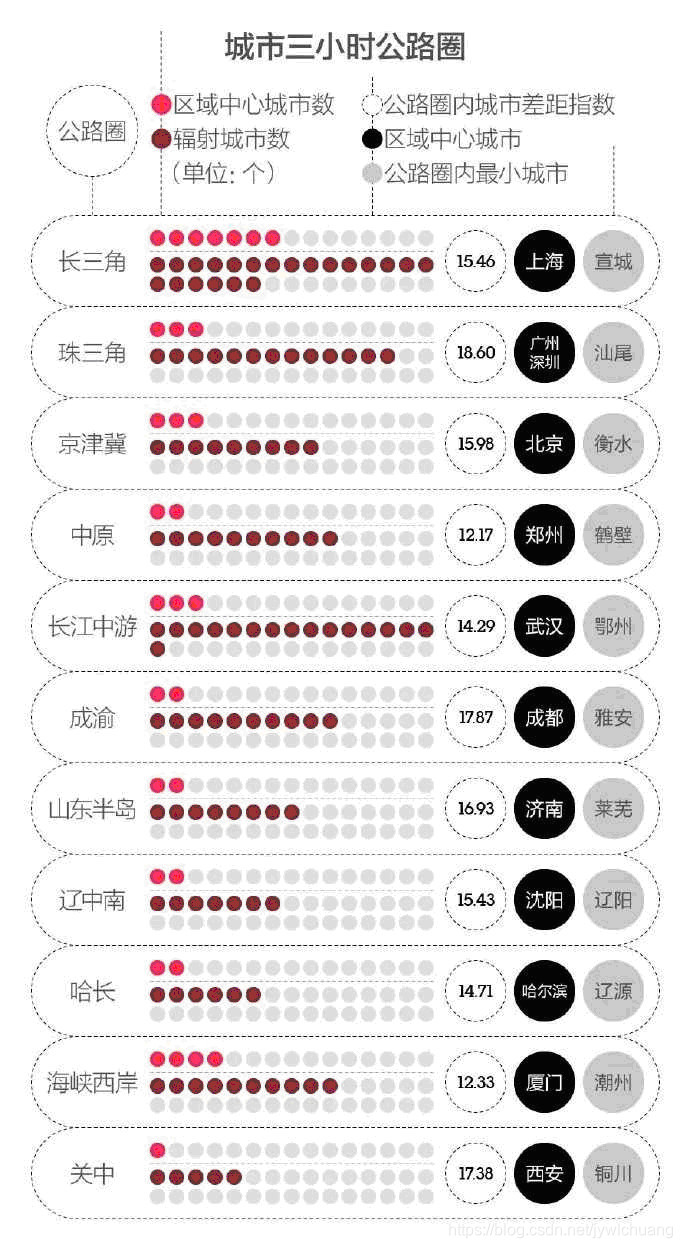


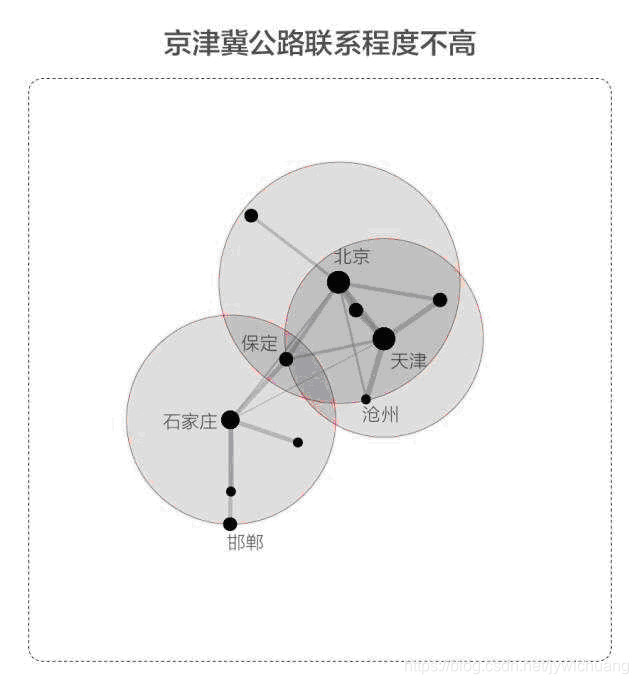
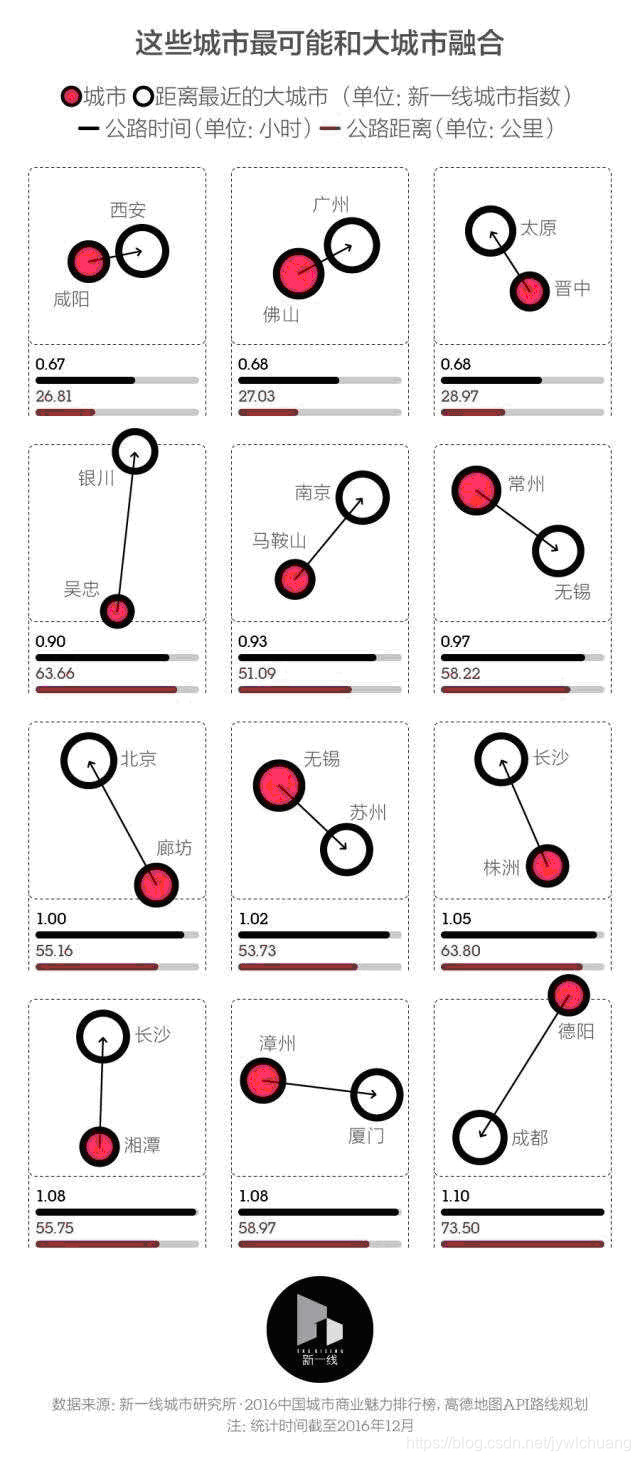
Susan Etlinger: What do we do with all this big data?
Now, there’s a group of data scientists out of the University of Illinois-Chicago, and they’re called the Health Media Collaboratory, and they’ve been working with the Centers for Disease Control to better understand how people talk about quitting smoking, how they talk about electronic cigarettes, and what they can do collectively to help them quit. The interesting thing is, if you want to understand how people talk about smoking, first you have to understand what they mean when they say “smoking.” And on Twitter, there are four main categories: number one, smoking cigarettes; number two, smoking marijuana;number three, smoking ribs; and number four, smoking hot women.
这里非常有趣
(三)大数据的应用场景
先贴两个新闻观察:
京津冀大数据产业发展现状 | 报告 | 数据观 | 中国大数据产业观察_大数据门户 数据观 | 中国大数据产业观察_大数据门户
如今,在政策上,国家战略层面上,大数据受到的重视程度都越来越高。
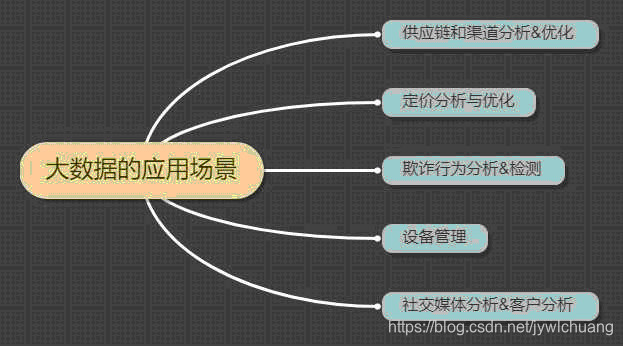
应用场景上,现在分布在:
- 供应链和渠道分析&优化
- 定价分析与优化
- 欺诈行为分析&检测
- 设备管理
- 社交媒体分析&客户分析
《大数据时代》一书作者维克托认为大数据时代有三大转变:
“第一,我们可以分析更多的数据,有时候甚至可以处理和某个特别现象相关的所有数据,而不是依赖于随机采样。更高的精确性可使我们发现更多的细节。
第二,研究数据如此之多,以至于我们不再热衷于追求精确度。适当忽略微观层面的精确度,将带来更好的洞察力和更大的商业利益。
第三,不再热衷于寻找因果关系,而是事物之间的相关关系。例如,不去探究机票价格变动的原因,但是关注买机票的最佳时机。”大数据打破了企业传统数据的边界,改变了过去商业智能仅仅依靠企业内部业务数据的局面,而大数据则使数据来源更加多样化,不仅包括企业内部数据,也包括企业外部数据,尤其是和消费者相关的数据
据野史记载,中亚古国花剌子模有一古怪的风俗,凡是给君王带来好消息的信使,就会得到提升,给君王带来坏消息的人则会被送去喂老虎。从前的人喜欢批评这位君王的天真品性,以为奖励带来好消息的人,就能鼓励好消息的到来,处死带来坏消息的人,就能根绝坏消息。
在今天这个信息爆炸的时代,我们不一定能让信使一定送来好消息,但你可以让我们的爬虫定时给你送来最有用最合你需求的信息。
大数据
大数据这个概念,是在12年火起来的。概念火了这么久,但是直到现在,不仅很多外行人不清楚大数据究竟是什么,甚至我接触过的很多内行人,对这个概念的本质也是一窍不通。
舍恩伯格在《大数据时代》这本书里总结的大数据的三个特征,业内人早已耳熟能详,但也争议颇多。但实际上,我觉得这三个看似不起眼的特征的背后,蕴含着对大数据深刻的理解和洞察。
那些贬低、或否定这三个特征的人,我想其眼界还是有待提高。
我们如果站在人类科学史和思维方法论的宏观视角来看待大数据,那么你会发现这三条简洁而优美的特征总结背后的深刻智慧。
所以今天我主要想从大数据的这三个特征入手,做一个大数据的科普,并阐述一些我个人的理解和看法。
一、不是随机样本,而是全体数据。
在过去,一方面由于技术、经济、人力等多个层面的限制,我们探索客观规律的时候,主要是依靠抽样数据、片面数据、或片面数据。所以就会导致有很多小概率事件覆盖不到,容易出现黑天鹅事件。
甚至有些时候我们都不是基于实证检验,而只是凭借经验,假设,和价值观,就对客观规律做出了总结。
这就导致过去很多时候,人类对于客观世界的认知,是肤浅的、表面的、错误的。
另一方面,过去我们对于客观规律的探究,出发点和探究的维度都是较为“狭隘”的。
比如我们想分析某商业机构的发展前景,可能过去我们的分析素材只集中在和商业、宏观政策等这些与我们的分析对象有着潜在的、或较为明显的因果关系的相关事物上。
但是大数据的分析对象会更广、更杂、更全面。可能对于这一商业机构的分析素材还会包括天气变化、90后消费倾向、某市人们点外卖的习惯等等这些“看上去”可能和我们的分析目的没有什么联系的“无关因素”。
但是通过大数据的分析,我们会发现很多我们无法马上理解和接受的、两种事物之间的相关关系。比如:男性顾客买尿布的时候喜欢顺带买啤酒,通过分析词汇检索可以预测到流感传播,咖啡和信用卡或房贷有强相关关系等。
随着信息技术的发展,我们获取数据变得更便捷、渠道更多、也更迅速、更具时效性,来自互联网的海量数据可以为我们所用。
因此我们的某个对象的分析不再是抽样调查,而是能覆盖这个对象全体,可以全方位、多维度的对其进行分析。
由此既消除了小概率事件的不确定性,又能够在对事物的分析中发现更多的可能性和相关性。
总体而言,这条特征反映出来的是:大数据的『量变』引发了人类进行分析和思考的核心层面上的『质变』。
在更专业的层面上,大数据的简单算法比小数据的复杂算法更有效,随着数据量的提升,我们获得的结论和答案的精准度也会逐渐提升。
二、不是精确性,而是混杂性。
以最通俗的语言来说,就是在庞大的数据体量面前,每一个小的数据的精确性可以变得不是那么的重要,因为庞大的数量可以消除或极大地稀释那些不准确的部分。
比如我们发100份调查问卷,里面如果有5个人是胡乱回答的,那可能就会极大地影响我们的调查结果;
但如果我们发了10万份调查问卷,那么即便是有50个人可以捣乱,那也不会对最终结果有太大的影响。
同时,如我们在前面所提到的,看上去混杂无章的数据,可以将原来看似无关的维度联系起来。
我们对这些不同维度的信息进行挖掘、加 工和整理,就能够获得有价值的统计规律。
因此,在这个时候,数据的混杂性反而成为了大数据的优势,通过对不同维度的数据的分析,使这些维度开始出现相互交叉,数据之间的关联性获得了极大地增强,我们也因此能够获得更多的新的规律。
三、不是因果关系,而是相关关系。
这个特征应该是最为人所诟病的了。甚至《大数据时代》这本书的译者周涛在这本书的“序”中就直接表明了对这一点的不认可。
我个人也认为,作者在书中对“因果关系”的否定态度确实太过狂妄了。但事实上,因果关系和相关关系其实本质上并没有什么区别。
“相关关系只是还没有被理解的、复杂的因果关系。”
因果律是最基本、最底层的逻辑规律。但只是过去人们习惯了对因果律的“简化”理解——人们绝大多数时候提到因果关系其实都只是在说“单因果关系”。
问题是世界上万事万物之间的联系是很复杂的,现实情况下的因果关系通常都是“多因果关系”,也就是事物之间的相互作用是多因多果的。
我们无法分析清楚复杂的、非线性的因果关系,故而将这些多因果关系称之为是“相关关系”。
大数据提倡关注“相关关系”,关注“是什么”而不是“为什么”,这并非是对『因果关系』的否定,反而是对客观世界真相的承认与接纳——承认世界是复杂的,联系紧密的。
同时也是站在一个更实用的立场上,专注于具体问题的解决或做出更优的决策。
如果我们发现在门口种一颗柳树,让一只狗绕着这棵树跑三圈,我们再狠狠地羞辱这只狗,就能够增加这家公司的利润,那么对这家公司来说,放在第一位的是赶紧这样去做、并开更多的店复制这种做法,第二位的才是要探究这种做法之所以起效的原因。
大数据并不是说因果关系不重要,而是说实用性才是最重要的,因果关系可以以后、或者交给别人去探究。
最后如果总结来说的话,其实大数据无非就是体量很大的数据集。但关键在于在这背后的:人类数据处理能力的提升、数据量的累积,分析方法的发展、思维的转变等等,这些才是『大数据』这个词的真正含义。
现在大数据这个词已经不“火”了。但我觉得大数据的发展和应用一定会越来越好、越来越广的。人工智能,金融交易,医疗研发等这些前沿领域无不需要大数据作为助力和支撑。
过去大数据作为一个很火的“概念”,反而令很多人忽略了它真正的价值。
大数据的发展和应用是未来的一个『趋势』。『趋势』都是由人类的思维方式、社会结构、科技发展这三者交互作用而催生的。
而大数据正是科技发展量变累积、和人类思维方法论革新交汇作用下的产物。
期待看到大数据为世界产生更多的价值。
什么是大数据?
这问题看似简单,实际不简单,也许一千个人会有一千个答案。是的,每个人对大数据都有自己的理解,就像小智问朋友,“重庆什么菜最好吃?”分分钟都能收获上百个答案。
今天,小智尝试从吃货的角度,给大家举栗说明一下,什么是大数据?
*举个栗子
1.大数据是什么?怎么理解大数据?
如果把数据比作地球上的水,个人的数据(电脑里的各种文档、歌曲、电影、程序等等),就好像一颗小水珠,最多能在累的时候解解渴;企业级的数据略有些不同,根据规模的大小,有些可以算作水坑、有些是池塘,已经可以养些小鱼小虾打打牙祭了;还有一些企业的数据(比如Facebook,2012年每天需要处理的数据量就达到了500TB)已经算得上是一个大的湖泊了,可以实现大型的捕捞、规模化的养殖。但是,在湖泊之外,还有更广阔的世界,也就是说还有更多的数据值得我们去发现。
比如,外国人常常埋怨中国菜不够“精确”,很多配料都用“少许”“适当”“足量”粗略地进行描述,实际操作起来很难学到精髓。有了大数据以后,主材、配料的数量、比例,油盐酱醋的多少,都可以进行精准地记录,甚至哪里产的猪肉,配上哪里的青椒、豆瓣做出来的回锅肉最好吃,都可以形成数据被记录下来。这些以前不被重视、不被采集的数据,就是我们大数据领域隐藏的“水滴”“池塘”“湖泊”。已有的大量数据,以及尚未被发现、记录的数据,共同构成了大数据时代的发展基础。
水滴、池塘、湖泊发现得多了,就能够汇聚成海洋。大数据海洋里面的水(数据),多到数不清楚,里面的物产、资源(大数据产生的价值)也丰富到无以复加。原来我们在湖泊里面养养“青草鲢鳙”四大家鱼,有了数据海洋,想吃生蚝、鳕鱼、金枪鱼等等都可以轻松搞定。
这么说,你明白大数据了吗?就是把超级多数据信息汇集到一起,然后在里面“钓大鱼”。
*数据海洋里面“钓大鱼”

2.都说大数据有4V的特征,是什么意思?
大数据的4V,就是“容量大Volume”“多样性Variety”“价值高Value”“速度快Velocity”,同样以海洋和里面的美食进行类比:
A.容量大:地球表面有70%左右都是海洋,想想里面都有多少水滴,有多少好吃的?大数据时代,每一个人、每一种食材、甚至每一秒风味与口感的变化关系,都能够形成一系列随时更新的数据,数据规模空前庞大,其中隐藏的价值也远远超出大部分人的预期。
B.多样性:海洋里面的物质非常多样化,有资源、也有杂物;有海胆、生蚝、象鼻蚌等小而鲜嫩的海产,也有黄鱼、鳕鱼、金枪鱼等大型鱼类……大数据的结构也和海洋一样复杂,仅仅以文件类型为例,就有图片、文字、声音、视频等等,还有各种非结构化数据,所以在利用这些资源之前,需要把他们“排排站”进行分类、处理,才能“吃果果”。
C.价值高:这个就不用说了,鳗鱼、龙虾、三文鱼……动辄每100克3~4万元的黄唇鱼,还有危急时刻能救人命的秋刀鱼。(前几年就出过一个日本青年因吃到炭烤秋刀鱼而放弃轻生的新闻,小智会乱说?)在实际应用中,大数据可以用于提升优化企业的管理效率,发现新的商业机会,也能够对事物的发展做出准确的分析、预测等等,各种商业价值就看你怎么用;

*传说中的炭烤秋刀鱼
D.速度快:先来吃肉、后来喝汤,这个道理想必大家都懂。数据海洋很大,想要比别人抢先一步找到美味,速度一定要快,这就要求我们要能对整个数据海洋进行快速的扫描、筛选、处理。如果只有两条小渔船,就算给你整个太平洋,也不见得能奔上小康。
PS:第4个V的比喻有点牵强,但不影响小智的发挥哈,他们说“想要吃肉,脸皮要厚”……
3.对大数据的处理,还是以在大海里面抓鱼为例:
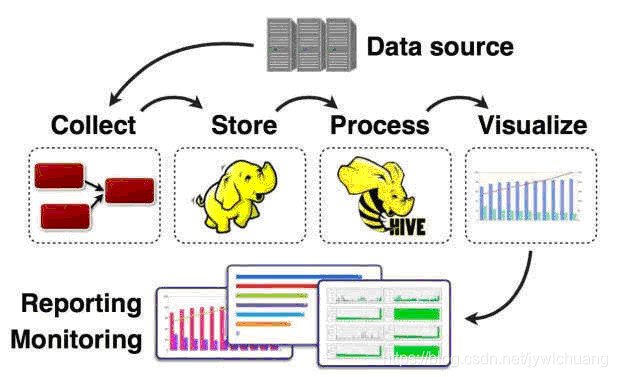
通过技术手段,发现隐藏在海水中的丰富物产的过程,就是数据挖掘;(从大量的数据中通过算法搜索隐藏于其中信息)
找到的东西里面,哪些是有用的,哪些是杂草、沙石先大概做一个分析,顺手把错误的、不合适的、没价值东西排除掉,这是数据清洗;(发现并纠正数据文件中可识别的错误)
在进行过初步筛选的“海域”里,进一步扫描出哪些是矿产、哪些是渔产,渔产里面有哪些鱼类,分别的种类划分、经济价值如何、数量多少……这是数据分析;(对收集来的大量数据进行分析,提取有用信息和形成结论)
把一眼看起来有些面目狰狞的海鲜(各种数字、表格)进行加工、处理,做成精美的大餐送上餐桌,色香味俱全地呈现在用户面前(精美、直观的图表),就是我们说的数据可视化。

*客官,您要的“数据可视化”已经上齐了
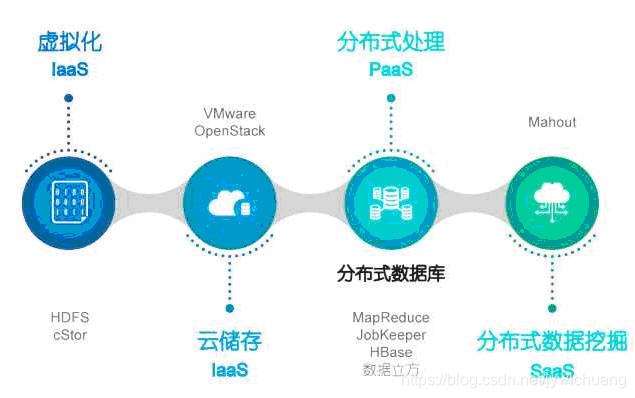
4.IaaS,PaaS,SaaS?
IaaS是基础设施服务。IaaS是所有计算基础设施的利用,包括处理CPU、内存、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序。就好像给你一个码头,配备好了各种硬件设备。机会和能力给了你,还需要靠自己的平台、工具,到海洋里面获取资源。
PaaS是平台服务。提供给消费者的服务是把客户采用提供的开发语言和工具(例如Java,python,.Net等)开发的或收购的应用程序部署到供应商的云计算基础设施上去。除了码头,又给了一艘船,还给你配齐船长、大副、水手,有了一个系统可以直接面对海洋的各种资源了。不过怎么抓鱼,用什么工具抓鱼,还是你自己的事情。
SaaS是软件服务,提供给客户的服务是运营商运行在云计算基础设施上的应用程序,用户可以在各种设备上通过客户端界面访问,如浏览器。这次就落实到具体的工具上面来,捕捞方案、抓鱼的网、开船路线都配齐了,只需要安排下去:去哪片海域抓什么鱼就行。

*你想在数据海洋里面捞什么鱼?
5.这几年说大数据,必定说Hadoop,后来又多了个Spark,是什么意思呢?
假如我的家族世代以打鱼为生,以前都是聚集在一个岛上,驾驶一艘大船出海打鱼,整个家族能打到多少鱼就和这艘船的航行速度(计算能力)、装载数量(存储能力)有关。它的速度再快、捞得再多,由于只有一艘船,能够搜寻的海域就相当有限。
现在我们改变了策略,一艘船的能力不行,就找N多艘船一起。整个家族的人分散到世界海洋各地,和其他家族一起共同分享各自的船只。必要的时候,我们可以联合几百艘船一起出动捕捞,由于覆盖的海域足够广,能够装载的收获足够多,对应的捕捞能力也可以实现指数式的增长。
hadoop就是这样一个分布式系统的基础构架,通过将文件进行分布式(切块、分散)管理,充分利用集体的威力进行高速运算和存储。

*Hadoop生态系统 2.0时代
至于spark嘛,就是船上以前有艘快艇,本来是用来逃生的,如今也被利用当成抓鱼的主要工具。(Spark是一种与hadoop类似的开源计算集群环境,启用了内存分布数据集,直接从内存读数据,运算速度最快能比从硬盘读取数据提升10倍水平)。
6.大数据用来做什么?
大数据有很多应用场景,比如精准营销,就是打鱼的人通过多年海上经验,知道哪片海域的海鲜多又能卖好价钱;比如舆情分析,就像海啸预警,通过对海量信息的分析、比对,找出可能产生海啸灾害的区域……当然,最大的用处还是“预测”,比如通过分析多年的洋流运动,能够分析出你今天在好望角错过的鱼群下个月会出现在哪里。什么?你说鱼对你没有吸引力?那如果预测的是未来股票的涨跌呢?如果预测的是未来行业的风口呢?
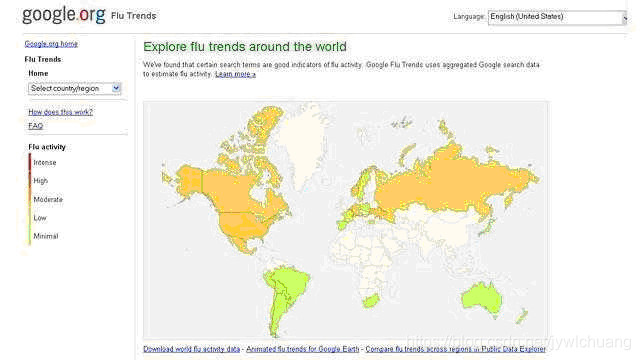
*谷歌尝试通过大数据进行流感爆发趋势预测
7.大数据企业都提供哪些服务?
第一类,云平台服务商,像亚马逊、阿里云这些,就好比世界上一个个国家,管理各自的海域,你可以去他的海域里面捕鱼,可以将你的海域交给他们管理,也可以直接买他们捕捞到的成品;
第二类,数据交易中介,他们自身提供一些数据,更主要的是搭建一个交易平台,撮合数据提供者与数据使用者实现数据交换,促成数据价值的实现,这有点像买卖各种湖泊、海洋的商人,买家拿到这些数据后,可以融合到自己的“海洋”里面去,让自己的海洋变得更大,物产更丰富;
第三类,大数据解决方案提供商,就是在数据海洋的各个角落派遣捕鱼船队,提供海洋开拓、资源扫描、采矿捕捞、加工销售的一系列服务,你想在数据大航海时代做的所有事情,他们都能帮你处理。