前言
接着上次的短文本匹配初探。深度文本匹配作为检索式对话的单轮匹配问答,无法完成多轮的任务,在单轮的基础上,加入其它 feature 的提取技巧,可以完成多轮对话。
Multi-view
Multi-view Response Selection for Human-Computer Conversation EMNLP2016
作者提供了一种直接的单轮转多轮思路——将多轮问答语句合并为一列, 连接处用_SOS_隔开, 将整个对话历史视为"一句话"去匹配下一句。将整个对话历史合并为一列, 做word embedding后通过GRU模块提取词汇级特征, 与候选的response做匹配。

不过每次直接把 word embedding sequence 输入网络得到整个多轮对话的表示(context embedding)用GRU是很难学习的,所以文中提出将每个文本也做一次匹配,用的 TextCNN+pooling+GRU结构,以上就是 word-level 和 utterance-level 的结合。

从这篇论文后的大部分论文也follow了这种对每条utterance分别进行处理(表示或交互),而后对utterance embedding sequence用Gated RNN进行过滤和得到context embedding的思路。
集成的模型最后用的 loss 函数是disagreement-loss(LD)和likelihood-loss(LL):
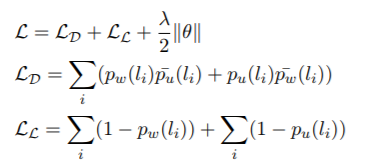
总结:
- 多粒度文本特征来表征多轮
- 还是文本匹配的本质,从这个模型本身上创新没有质的改变
SMN
如果说第一篇Multi-view模型是单轮问答表示模型的扩展, 那这一篇就是单轮问答交互模型的扩展,作者认为构建问答历史语句和候选回复的交互表示是重要的特征信息, 因此借鉴语义匹配中的匹配矩阵, 并结合CNN和GRU构造模型:

与Multi-view模型类似, 这里作者也考虑同事提取词汇级和语句级的特征,不过作者在这里把两个文本的相似度矩阵看成一个图像,然后使用图像分类模型CNN来得到更高level的相似度特征表示(比如phrase level, segment level等),进而最终得到全局的相似度匹配特征,这个做法借鉴了之前的单轮匹配中的论文:Text Matching as Image Recognition
SMN给定一个candidate response,在生成word-level的每个utterance的向量表示的时候,首先计算出历史上每个utterance跟该response的对齐矩阵,然后对每个对齐矩阵,均使用上面这种图像分类的思想生成high-level表征文本对相似度的特征向量作为该utterance的向量表示(utterance embedding)。
之后就是使用前面Multi-view中的做法,从这个utterance embedding sequence中得到整个对话的context embedding,最后将该context embedding和之前的word-level下得到的context embedding与response的向量去计算相似度了。
计算匹配矩阵时,这里结合使用了原始的 word embedding 和用了 GRU对文本encoding之后的隐状态(即编码过上下文信息的word embedding,可以看作phrase-level的"word embedding"),然后这样将两份对齐矩阵作为两个channel丢进“图像分类模型”,从而保证了即使图像分类模型很浅,也能抽取出比较high-level的特征,得到高质量的utterance embedding。
最后的context embedding中作者使用比较了三种隐变量
方式:
- 只用最后一个隐变量
- linearly-combined将所有 输出线性加权
- 用attention计算
权重
实验结果表明attention最好,但计算开销较大,可以只用最后一个输出。
总结:
- 多粒度的必要性再一次证明
- 依赖刚开始的retrieval得到的response的准确性,要是没有检索到正确结果那后面都是徒劳
logical consistency层面的信息没有体现,可以匹配出与上下文相关的response,但是逻辑上不一定能说通
DUA
Modeling Multi-turn Conversation with Deep Utterance Aggregation COLING2018
Multi-view和SMN模型都是将对话历史视为整体, 或者说每一句对于response都是平等的, 这样做会忽略对话历史的内部特征, 例如一段对话过程经常包含多个主题; 此外一段对话中的词和句的重要性也都不同. 针对这些对话历史中的信息特征, 作者设计了下图所示的DUA模型:

第一步还是 utterence embedding 加 GRU,接着对于历史交互的问题,作者认为虽然history中的多句话都对response有影响, 但最后一句通常是最关键的,每个utterance(除最后一句)和response都和最后一句utterence做aggregation操作, aggregation操作有三种: 连接(concatenation), 元素加(element-wise summation), 元素乘(element-wise multiplication), 其中连接操作的效果最好。
然后以utterance为单元做self-attention, 目的是过滤冗余(比如无意义的空洞词句), 提取关键信息, 由于self-attention会失去序列信息,作者这里又把encoding后的utterance embedding跟encoding前的utterance embedding拼接起来又过了一层Gated RNN,Gated RNN(GRU、LSTM等)一方面可以按照时序进一步encoding,另一方面里面的输入门也起到了filter的作用,正好可以在加强encoding的同时把无用的信息过滤掉。
在后面的做法和SMN交互层一样,用第一层的词向量和上一层的GRU输出分别构建词汇级和语句级的匹配矩阵, 过CNN+Pooling获得交互特征,最后将交互特征传给一层GRU获得隐状态h, 再对h和上一部分的GRU输出做attention操作, 将输出传给softmax获得预测匹配结果。
总结:
- 侧重于对词汇和语句都做多层特征提取
- 一个utterance包含多个intention或者一段对话包含多个topic情况下难以解决回复的准确性
- 轮次多的情况下会误判正确response
DAM
Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network ACL2018
本文对于context和response语义上的联系更进一步,将 attention 应用于多轮对话,打破之前的 RNN 和 CNN 结构,在多轮上速度快,达到了目前最好效果。其次,本文使用 self-attention 和 cross-attention 来提取 response 和 context 的特征。

以下分为三个部分来讲:
Representation

在输入词向量embedding后传给 Transformer 的 encoder模块,对话历史以句子为单位, 与response一起通过L个Attentive Module, 每个utterance和response都获得了L个矩阵
和
, 就是结构图第三列, 蓝色是每个句子
的L个矩阵合并的
, 绿色是response对应的L矩阵组成的
。
Matching
这里DAM模型同样有两种匹配矩阵, 是整个模型的核心部分, 其中第一列
称为自注意力匹配(self-attention-match), 第二列
称为交叉注意力匹配(cross-attention-match)
的构建相对简单, 由上一层每个句子得到了
和response得到的L个矩阵构成的
和
进行 attention:
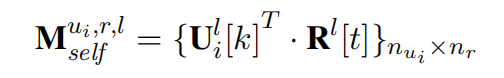
这里的
就是指的第
级粒度,
是指的第i个utterance,
有
个词,response有
个词。这里就是说,对于每级语义粒度的每个 utterance,都是将其中的每个词
去跟response中该粒度下的每个词
去算内积,从而得到一个
的对齐矩阵。
对于传统的attention,如果两个词在semantic或syntactic上离得近,就容易得到比较大的匹配值(如run和runs, do和what)。然而对于一些比较深层和隐晦的语义关系就很难直接匹配了, 论文这里加入了cross-attention来构造
:

这里先通过传统的attention来把utterance和response中的每个词用对面文本的词加权表示,得到新的utterance的word embeding sequence表示和新的response的word embedding sequence表示,之后再用一层传统的attention来计算出一个对齐矩阵来作为第二个对齐矩阵。
Aggregation
经过这么深层的匹配后,每个utterance中的每个词位都包含了2(L+1)维的匹配信息(L为Transformer encoder的层数,1为原始的word embedding,2为对齐矩阵的数量),作者这里又把utterances堆叠到一起,就形成了这个3D立方体,这个大立方体的三个维度分别代表对话上下文中的每个utterance、utterance中的每个词(位)、response中的每个词(位)。
最后用两层3D的CNN处理这个立方体, 得到的特征传给单层MLP估计匹配程度.
总结:
- 深度attention(Transformer模型)在NLP任务上的有效性
- 近年的论文表明图像中的CNN提取高维特征信息在这里有一定成效
MRFN
Multi-Representation Fusion Network for Multi-turn Response Selection in Retrieval-based Chatbots WSDM2019
在DAM的两种粒度的基础上增加了一种局部信息的粒度,主要有三种形式的粒度6种表示形式:
Word: char embedding + word2vecContextual: Sequential(GRU编码得到句子上下文关系) + Local(利用CNN一维卷积池化获取N-gram的信息)Attention-based:跟DAM一样 self-attention + cross-attention
加入词向量解决了OOV问题,Contexrtual是对于局部短时信息的提取(short-term),attention部分就是长时间依赖(long-term)。整体Model如下图:

左边就是embedding和三种粒度的representation部分,右边三块是把fusion步骤分别放在网络前、中、后期的三种比较,fusion就是将各粒度信息融合的步骤,往往是矩阵拼接(concatenation)的过程,实验证明fusion放在网络后期效果最好。interaction部分是用的SUBMULT+NN的交互形式:
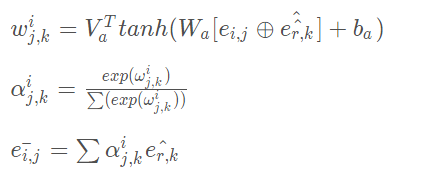
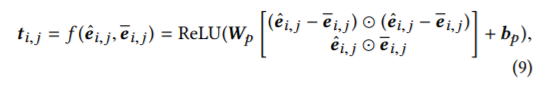
interaction之后的GRU提取相似度矩阵的高维特征得到一维向量
最后每条utterance再用一层GRU拼接起来再放到最后的MLP层得到score。其实直观的来看放到后期性能最好的原因还是因为保留的初始信息最多吧,早做fusion在GRU的过程中已经有所损失了。
另外实验也做了很多详细的实验比较三种粒度的贡献以及对话的轮次和utterance长短对于三种粒度的影响,最后结论是Contextual贡献最大,轮次少和很多的时候Contextual比Attention效果更好,轮次少的时候可能RNN系列性能的确可以和attention相抗衡,轮次多的时候可以理解为当前的回复其实更多与附近的对话相关,与较远的对话关系反而远了,所以对于局部前文信息把握更多的Contextual可能会更好。utterance越长attention的优势被证明更明显,这是可以理解的。

总结:
- 大量的对比试验证明了一些检索式多轮对话中的trick,还是很有意义的
- 初始的三种粒度其实是对于不同情况下多轮对话数据集的一种适应
总结
检索式多轮对话感觉不会再专门去看论文了,其实从SMN开始就可以看见这种交互式模型基本就是embedding到representation到matching到aggregation最后输出score的过程,每个部分其实都可以做改进,其实也是各粒度的叠加和一些小trick的使用,不过感觉这种做法很难落地,实用性有待考究。
Reference
1、小哥哥,检索式chatbot了解一下?
2、检索式多轮问答系统模型总结
3、浅谈多轮检索式对话最近的两篇SOTA-『MRFN』&『IMN』