概述:
mq是web架构中经常用到的异步消息交互系统,是解决异构系统中消息处理中间件。
本文不介绍具体的代码调用,相信网上这方面的资料已经相当多了,本文主要介绍使用过程中的一些建议和心得。
场景:
先说下使用场景,mq场景还是比较多的:
1.复杂业务场景拆分:
web应用经常出现一些复杂业务,但是这些业务又不是强依赖业务,往往并不关注具体代码的先后顺序,并且业务点调用对系统响应有一定影响;这种系统往往就适合做异步过程处理。
模拟一种场景:
x包含a,b,c,d四个业务处理,分别耗时500ms,300ms,200ms,1000ms。
如图:
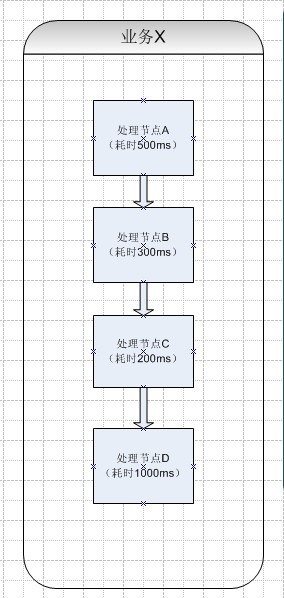
而节点A其实和节点B不存在耦合,也就是说没有前后关系,这样节点A是否可以移出,这样总共的响应时间将会提高500ms。
试想“任务X”结构变成这样,
如图:

当然消息处理本身也会消耗,所以需要权衡那些特别耗时的业务点。
常见的业务场景如:
1.数据监控
2.多节点数据。
2.多数据源:
这种场景往往是历史包袱造成的,早期的数据性能并不是很好,导致很多架构在设计时采用了读写分离数据库设置方式,这种方式的好处是,面对用户的数据库是低写入,低操作,高响应;面对后端服务人员是高并发,低响应。解决用户响应问题。
但是由于多数据源导致的数据一致性就存在了。这时mq方式有比较适用这种场景。当然目前架构有很多能解决类似问题,比如mysql的数据库可以使用log同步变更,或者master-slave等,这些方案更加用户场景来使用。
如图:
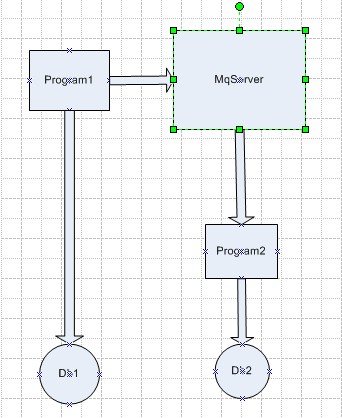
这种是解决多数据源系统信息同步的一种方式。
3.信息通知:
很多系统并发孤立点。往往变更一个信息会影响到其他系统,比如实时search,比如数据统计,虽然数据是某个系统的,但是这些信息也是其他部门共用的,我们需要通知到对方我们的变更。这有点类似于2但又有区别。
针对这种类型的需求,建立发布订阅的消息往往能很好的解决这些需求的问题,消息提供方是我们点,我们约定好消息格式,由各个系统根据消息进来去执行自身业务,包括更新自身索引,或者统计数据。这种架构图和发布订阅很象,这里就不划了。
建议:
1.同步信息最好是string,非业务对象:
业务对象就存在序列化和反序列化问题,但是这样的系统存在问题,当业务需要重构时,消息格式需要变更时往往变得更困难。
string的扩展性还是不错的,
举例:原先的数据结构是:
offerId|memberId|time
现在需要增加一个companyId,可简单的追加一个offerId|memberId|time|companyId
这种方式不但不引入序列化带来的性能消耗,消息信息也很清晰。
2.同步只是消息,具体信息数据库取
由于mq在设置时一般不设置前后顺序的约束,主要是减少性能消耗;
这样不可避免存在消息前后问题,可能早先的消息是后来的,而后面的消息是之前的,如果取同步消息反而会导致两端数据存在不一致的风险。
因此建议消息只是通知,具体去数据库取信息
3.同步注意消息的细分力度,细能精准控制,但也会引入大量修改点,尤其是以后逻辑修改
比如对于一个会员,可能存在登录,修改信息,这个力度的消息格式就需要两个就能区别,同时也比较直观;
但是如果要区分用户是否修改密码,是否更新过用户名,如果要消息区别这个粒度,就需要把修改消息拆分成3个。
似乎很清理,但如如果还要区分如何,继续拆,那么你的业务逻辑就变得非常庞大。所以在细分时一定要仔细考虑清楚以后的影响
4.维护好同步列表,避免以后大家不了机信息导致修改问题
异步减少了系统的耦合,也是用户关注的更加集中,结果就是同步忽略,遗忘,无视,最终变得不可控制。
一改动代码就出现故障,这个问题是我在维护类似问题经常遇到的。所以一份必要的同步列表往往能记录所有变更。
经验之谈,thanks;
如有更好建议,请指正