前言
组件化方案由来已久,从淘宝 All in 无线,到滴滴 The one,再到蘑菇街组件化之路,越来越多的互联网公司开始采用组件化方案应对业务爆发。
我们 App 使用的是 单工程+MVVM,虽然可以满足大部分的业务需求。但是最近公司业务的发展较快,现有架构已经无法满足需求了。组件化方案有很多,每个公司的业务不同,具体的方案也会有所差别。本文是针对我们公司项目的现状并结合一些大神的博客做的一些思考。
为什么要组件化
先看一张现有业务的架构图
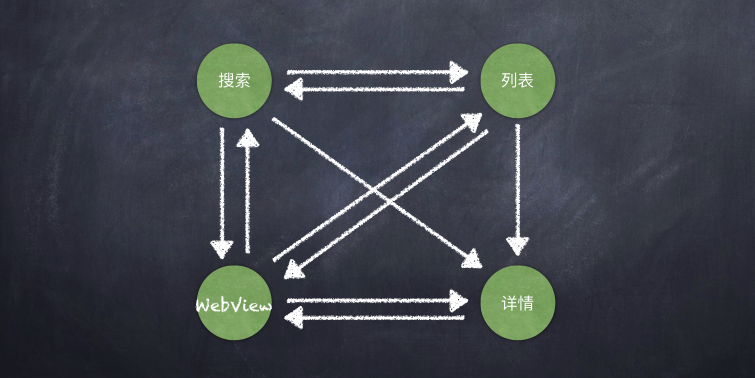
- 业务模块相互依赖,耦合比较严重
1 当一个需求需要多业务合作开发时,如果直接依赖,会导致某些依赖层上端的业务工程师在前期空转,依赖层下端的工程师任务繁重,而整个需求完成的速度会变慢,影响的是团队开发迭代速度;
2 当要开辟一个新业务时,如果已有各业务间直接依赖,新业务又依赖某个旧业务,就导致新业务的开发环境搭建困难,因为必须要把所有相关业务都塞入开发环境,新业务才能进行开发。影响的是新业务的响应速度;
3 当某一个被其他业务依赖的页面有所修改时,比如改名,涉及到的修改面就会特别大。影响的是造成任务量和维护成本都上升的结果。
- 现有业务增多,多个 APP 并行开发,代码复用度不高
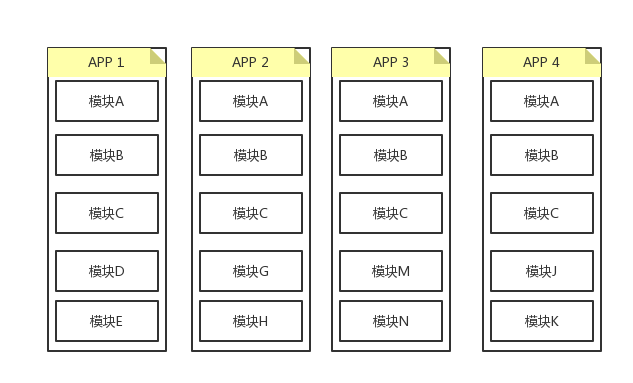
- 业务开发效率不够高
业务层只关心自己的组件,却要编译整个项目,与其他不相干的代码糅合在一起。
- 不方便测试
所有模块代码都编写在一个项目中,测试某个模块或功能,需要编译运行整个项目。
如何解决
让依赖关系下沉!

怎么让依赖关系下沉?引入中间件模式。
所谓引入中间件模式来让依赖关系下沉,实质上就是每次呼唤页面的时候,通过一个中间人来召唤另外一个页面,这样只要每个业务依赖这个中间人就可以了,中间人的角色就可以放在业务层的下面一层,这就是依赖关系下沉。
当A业务需要调用B业务的某个页面的时候,将请求交给中间件,然后由中间件通过某种手段获取到B业务页面的实例,交还给A就行了。在具体实现这个机制的过程中,有以下几个问题需要解决:
- 设计一套通用的请求机制,请求机制需要跟业务剥离,使得不同业务的页面请求都能够被
中间件处理 - 设计
中间件根据请求如何获取其他业务的机制,中间件需要知道如何处理请求,上哪儿去找到需要的页面
组件化能解决什么问题
- 业务划分更加清晰,新人接手更加容易,可以按组件分配开发任务;
- 项目可维护性更强,提高开发效率;
- 更好排查问题,某个组件出现问题,直接对组件进行处理;
- 开发测试过程中,可以只编译自己那部分代码,不需要编译整个项目代码。
组件化设计原则
- 越底层的组件,应该越稳定,越抽象,越具有高复用度。
稳定的最直观表现就是API很久都不用变化,所有的变化因子不要暴露出来,避免传递给依赖它的组件。 稳定性有一个特点就是会传递,比如B组件依赖了A组件,如果B组件很稳定,但是A组件不稳定,那么B组件也会变的不稳定了,因此下一个原则:
- 不要让稳定的组件依赖不稳定的组件, 减少依赖
如果B组件的确依赖了A组件里面不可或缺的代码怎么办?假设依赖的代码段为x, 现在来看x的特性,如果X是一个可能高复用的代码段,那么无妨把x从A组件里面拿出来,单做成一个组件X,那么B组件依赖X组件就好了;另一种情况,x是一个方法或函数,而且不太适合单做成一个组件,所以那就在B组件里面拷贝一份x代码就ok了,因为这样可以保证组件的稳定性和自完备性。
- 提升组件的复用度,自完备性有时候要优于代码复用
什么是自完备性,就是尽可能少的依赖组件来达到代码可复用。 举个例子,工具类 Utils 里面放了大量的工具方法等。在日常UI产品开发中,依赖这个 Utils 会很方便,但是我现在要写一个比较基础的组件,应该就要求复用度更高一些,这个时候需要用到Utils里面的几个方法,那这个时候还适合直接 大专栏 组件化方案依赖 Utils 吗?当然不合适了,这与我们上面的设计原则相悖了啊,因此我们这时候为了这个组件的自完备性,就可以重新实现下这几个方法,而不是依赖 Utils 组件。
- 每个组件只做好一件事情,不要让Common出现
组件化结构是让工程结构更清晰,每个组件都只做一件事情,都有自己的一个命名,这样这个组件才能良性发展。
组件化方案选择
组件化方案有多种,公司业务不同,方案也不同。但有一个共同点,就是单工程拆成多工程。下图是根据我们公司的业务设计的一套方案:
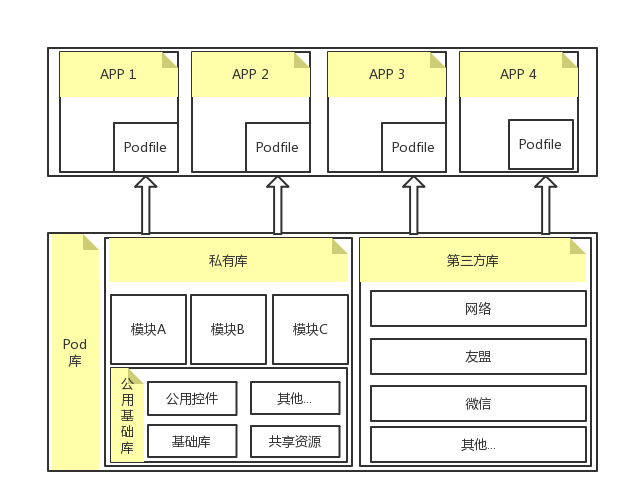
1.每个组件都是一个单独的repo,单独维护;
2.模块下层是公共基础库,基础库负责提供基础功能,与业务层无关;
3.所有组件通过cocoapod管理;
4.第三方库跟公共基础库是平行的,位于模块的下层;
5.每个APP表现为一个主工程,主工程负责组装各个业务模块。每个业务模块在Podfile中配置。
中间件
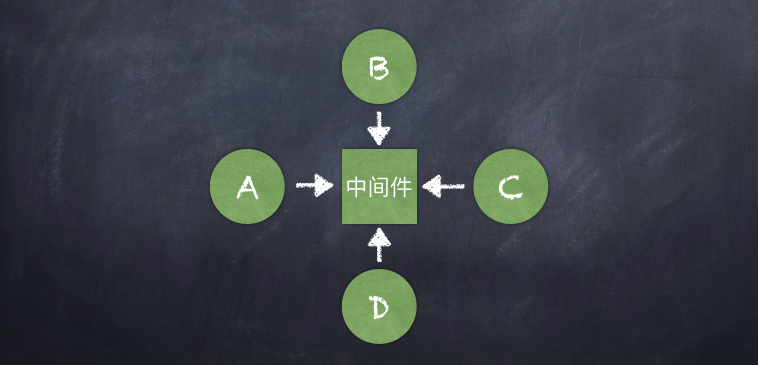
如前文所述,中间件的职责是让依赖下沉,将业务层之间的依赖交由中间件调度。中间件的架构见下图:
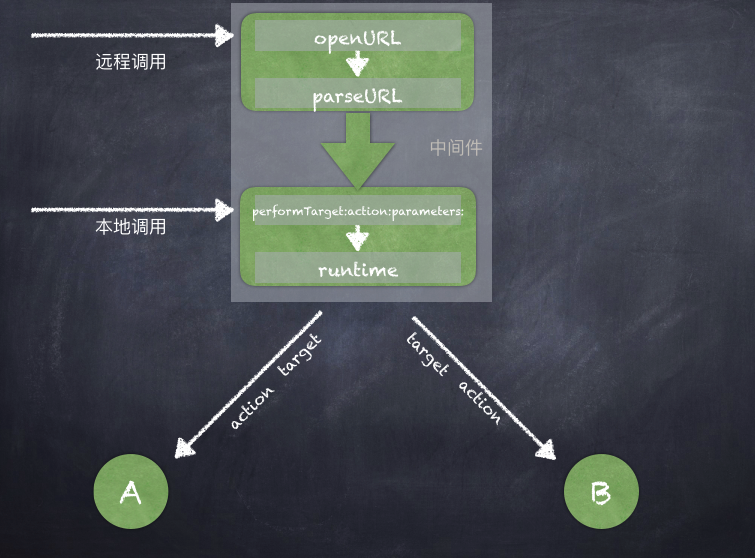
1.本地调用:本地组件A向中间件发起跨组件调用,中间件根据获得到的target和action信息,在底层通过objective-C的runtime转化为target实例和action选择子,最终完成调用逻辑。
2.远程调用:AppDelegate接收到URL之后,调起中间件的openURL:方法将接收到的URL信息传入。然后中间件通过解析URL,将请求路由到target和action,进入本地调用流程,完成调起逻辑。
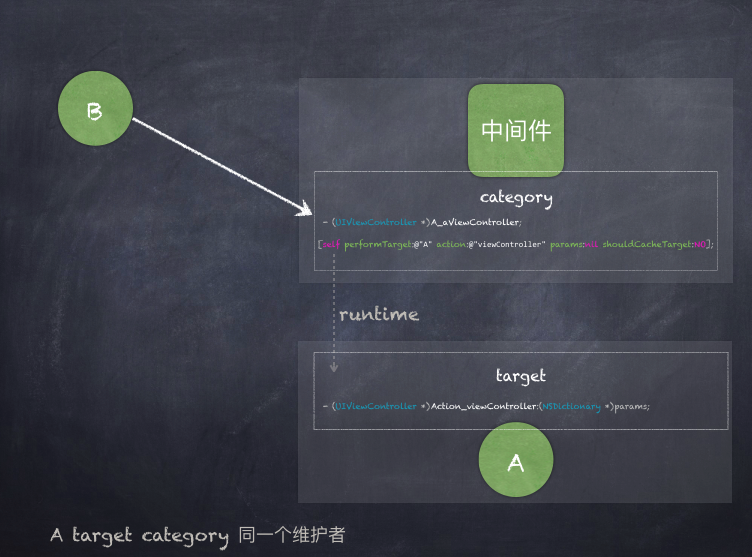
组件暴露Action为中间件提供调用接口
所有组件自带target-action,将调度接口固化在target-action层,以避免对业务层的侵入。
中间件以category方式实现调度组件。
去Model
组件内部全部采用去Model化设计,使用字典+key表征数据模型。组件间以字典形式传递参数。
为什么不使用对象模型呢?使用对象模型在转化时成本是很大的,主要表现在:
1.数组内容的转化成本较高:数组里面每项都要转化成Item对象,如果Item对象中还有类似数组,就很头疼。
2.转化之后的数据在大部分情况是不能直接被展示的,为了能够被展示,还需要第二次转化。
3.只有在API返回的数据高度标准化时,这些对象原型(Item)的可复用程度才高,否则容易出现类型爆炸,提高维护成本。
4.调试时通过对象原型查看数据内容不如直接通过NSDictionary/NSArray直观。
5.同一API的数据被不同View展示时,难以控制数据转化的代码,它们有可能会散落在任何需要的地方。
开始
1.搭建私有库
私有Pod库用来保存所有的基础库和业务模块,每个组件是一个单独的 repo,单独开发,单独测试。
2.网络库选择
网络库不多介绍,直接选取猿题库开源的网络库。
3.数据存储方案选择
考虑到客户端数据量不大,数据层可采取 key-value 方式存储。可以满足绝大多数的业务需求。
4.视图层布局
视图层的布局采取 xib 和 storyboard 方式,这也与苹果的理念相符。
5.资源文件管理
对于一些确定只在固定模块内使用的资源文件,可单独放在该模块内。其他资源文件放在公共的地方,以组件的形式存在。
6.远程推送 & 统计 & 分享 等
统一以组件的方式提供服务
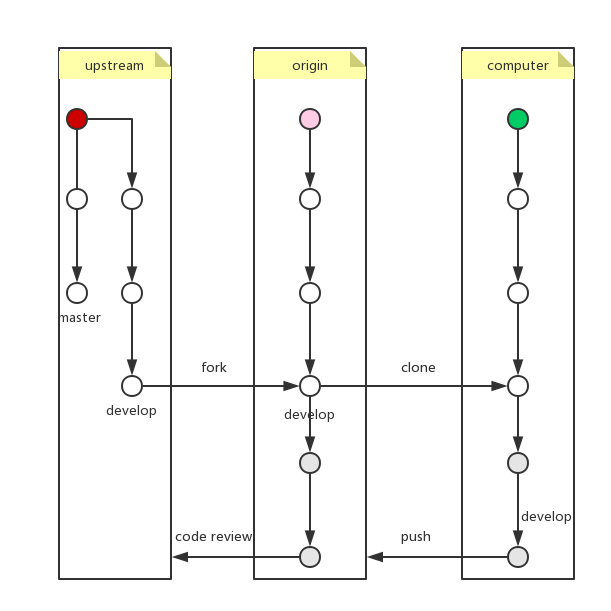
分支管理
直接上图:
测试分发与持续集成
使用bundle创建隔离环境,使用 cocoapods 管理依赖库,使用脚本自动构建测试包、正式包。