1 最大似然估计
设总体分布为f(x,θ),X1,X2,..Xn为该总体采样得到的样本,X1,X2,X3,…,则其联合密度函数为:
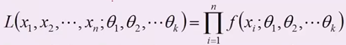
这里的θ被看作固定但未知的参数,而X1,X2,…Xn是固定的,L(X,θ)是关于θ的函数,叫做似然函数,求参数θ的值,是似然函数取最大值,这种方法叫做最大似然估计。
2 最大似然估计求解
通常将似然函数取对数,得到对数似然函数,若对数似然函数可导,可通过求导的方式,解方程组,得到驻点。
3 公平赔率
n个事件发生的概率分别为n1,n2,n3,…,nn,若以1/n1,2/n2,3/n3,…,1/nn的赔率分别处理,则庄家收益趋近于0,对应的赔率称为公平赔率。实际生活中,庄家一般会在公平赔率乘以一个小于0的系数α,保证自己的收益。
5 特征选择
降维:PCA主成分分析
升维:添加变量的高次项
6 过拟合
将训练数据分为训练集和测试集,如果模型效果在训练集效果很好,但是在测试集上效果较差,则发生了过拟合,与之相对的是欠拟合。
7 one-hot编码
实际数据处理过程中,会面临将非数值型数据转换成数值型数据以进行分析的情况,而有些变量主要体现存在性价值,并没有有数值上的意义,比如某个特征分为3个类型,这个时候采用简单的数值替换不合适,可以采用one-hot编码进行处理。
通常来说,老式的回归分析、svm需要做one-hot编码转换,而决策树和随机森林不用。
8 回归
连续型因变量:回归
离散型因变量:分类
9 假设
内涵性:从常理来解释是正确的
简化性:假设只是接近真实,往往需要做若干简化
发散性:在某个简化假设下推到得出的结论,不一定只有在假设成立时结论才成立
10 正则项
作用:防止过拟合
正则项方式:
L1正则:加入绝对值项
L2正则:加入平方项
两者结合:L1正则有特征选择能力,L2正则往往性能更好
11 数据使用
训练数据:训练系数
验证数据:调参
测试数据:测试效果
12 梯度下降法
BGD:批量梯度下降法
SGD:随机梯度下降法
mini-batch-SGD:小批量随机梯度下降法,实际中用的多些