随笔记录方便自己和同路人查阅。
#------------------------------------------------我是可耻的分割线-------------------------------------------
学习selenium自动化之前,最好先学习HTML、CSS、JavaScript等知识,有助于理解定位及操作元素的原理。关于python和selenium安装请自行搜索别的资料,
这里就不多做介绍了,所有例子均使用python3.6+selenium执行的。
#------------------------------------------------我是可耻的分割线-------------------------------------------
XPath定位
以前介绍的几种定位方法相对来说比较简单,理想状态下,在一个页面当中每一个元素都有一个唯一id和name属性值,我们可以通过它们的属性值来找到它们。但是实际项目中并非想象的这般美好,有时候一个元素并没有id、name属性,或者页面上多个元素的id和name属性值相同,又或者每一次刷新和页面,id值都会随机变化,这些情况下,我们如何来定位元素呢?
下面介绍Xpath与CSS定位,与前面介绍的几种定位方式相比,他们提供了灵活的定位策略,可以通过不同的方式定位想到的元素。
Xpath是一种在XML文档中定位元素的语言。因为HTML可以看作XML的一种实现,所以selenium用户可以使用这种强大的语言在web应用中定位元素。
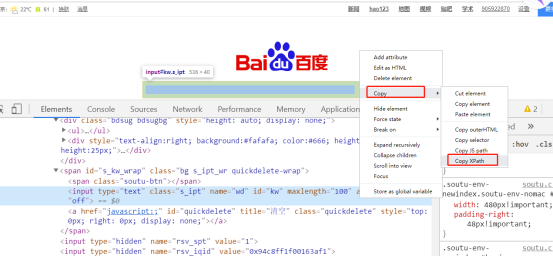
所有代码示例都以百度首页为例,且都是使用Chrome浏览器打开网页,在百度首页时候用Chrome自带控制台查看百度输入框的HTML代码,可以使用F12或右键检查打开控制台,找到百度输入框的THML代码,并使用鼠标右键选择Copy Xpath路径,如下图:
#导入webdriver模块它是用来控制浏览器的 from selenium import webdriver driver = webdriver.Chrome()#实例化,且指定以Chrome浏览器打开 first_url = 'http://www.baidu.com'#定义要访问的URL driver.get(first_url)#使用get方法访问网页 Element = driver.find_element_by_xpath('//*[@id="kw"]')#通过xpath进行元素定位 Element.send_keys('selenium') print(Element)
结果展示:


根据上图结果可以看出我们在输入框输入了selenium但是没有任何查询信息,这是因为我们没有做回车操作
绝对路径定位
Xpath有很多种定位策略,最简单直观的就是写出元素的绝对路径。如果扔把一个元素看作一个人的话,假设这个人没有任何属性特征(手机号、姓名、身份证),但这个人一定存在于某个地理位置,如XX省XX市XX区XX路XX号。对于页面上的元素而言也会有这样一个绝对地址。
参考baidu.html前端工具所展示的代码,我们可以通过的方式找到百度输入框和搜索按钮
find_element_by_xpath(“/html/body/div/div[2]/div/div/div/from/span/input”)
find_element_by_xpath(“/html/body/div/div[2]/div/div/div/from/span[2]/input”)
find_element_by_xpath()方法使用XPath语言来定位元素。XPath主要用标签的层级关系来定位元素的绝对路径,最外层为html语言。在boby文本,一级一级查找,如果一个层级下有多个相同的标签名,那么就按上下顺序确定是第几个,例如div[2]表示当前层级下的第二个的第二个div标签。
利用元素属性定位
除了使用绝对路径外,XPath也可以使用元素的属性值来定位。同样的百度输入框和搜索按钮为例:
find_element_by_xpath(“//inout[@id=’kw’]”)
find_element_by_xpath(“//inout[@id=’su’]”)
//表示当前页面某个目录下,input表示定位元素的标签名,[@id=’kw’]表示这个元素的id属性值等于kw。下面通过name和class属性值来定位。
find_element_by_xpath(“//inout[@name=wd]”)
find_element_by_xpath(“//inout[@class=’s_ipt’]”)
find_element_by_xpath(“//inout*[@class=’bg s_btn’]”)
如果不想指定标签名,则也可以用星号(*)代替。当然,使用XPath不局限于id、name和class这三个属性值,元素的任意属性值都可以使用,只要它能唯一的标识一个元素。
find_element_by_xpath(“//inout[@maxlength=’100’]”)
find_element_by_xpath(“//inout[@autocomplete=’off’]”)
find_element_by_xpath(“//inout[@type=’submit’]”)
层级与属性结合
如果一个元素本身没有可以唯一标识这个元素的属性值,那么我们可以找其上一级元素,如果它的上一级元素有可以唯一标识属性的值,也可以拿来使用。还是以百度输入框为例,加入百度输入框本身没有可利用的属性值,那么我们可以找它的上一级属性。例如“小明”刚出生的时候没有名字,没有上户口,那么亲朋好友来找“小明”时可以先找到小明的爸爸,因为他爸爸是有很多属性特征的,找到了小明的爸爸后,就可以找到小明了。通过XPath描述如下:
find_element_by_xpath("//span[@class=’bg s_ipt_wr’]/input")
span[@class=’bg s_ipt_wr’]通过class属性定位到父级元素,后面/input就表示父级元素下面的子元素。如果父级元素没有可利用的属性值,那么可以继续向上查找“爷爷”元素。
find_element_by_xpath("//form[@id='form’]/span/input")
find_element_by_xpath("//form[@id='form’]/span[2]/input")
我们可以通过这种方法一级一级地向上查找,知道找到最外层的<html>标签,这就是一个绝对路径了。
使用逻辑运算符
如果一个属性不能唯一地区分一个元素,我们还可以使用逻辑运算符连接多个属性来查找元素。
<input id=’kw’ class=’su’ name=’ie’>
<input id=’kw’ class=’aa’ name=’ie’>
<input id=’bb’ class=’su’ name=’ie’>
如上面的三行元素,假如我们现在要定位第一行元素,如果使用id将会与第二行元素重名,如果使用class将会与第三行元素重名。如果同时使用id和class就会唯一地标识这个元素,这个时候就可以通过逻辑运算符“and”来连接两个条件。
find_element_by_xpath(“//input[@id=’kw’ and @class=’su’/span/input]”)
当然,我们也可以用“and”连接更多的属性来唯一地标识一个元素。