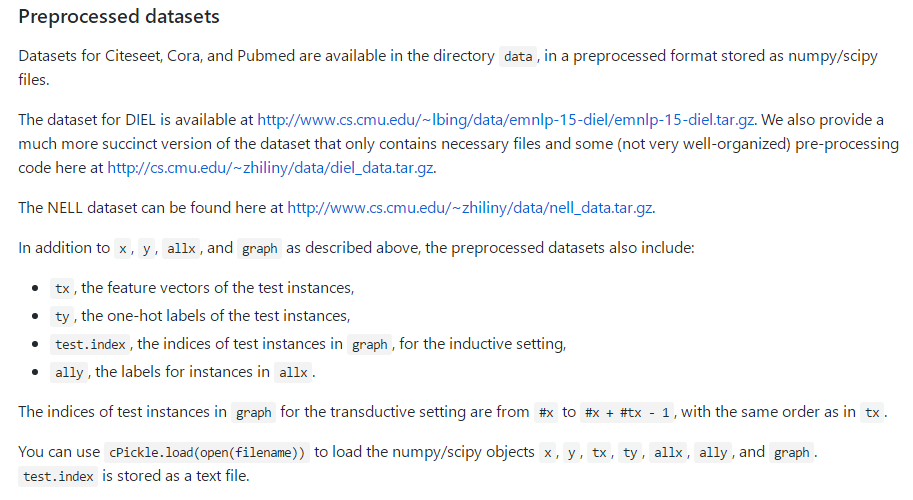
1.代码结构
├── data // 图数据
├── inits // 初始化的一些公用函数
├── layers // GCN层的定义
├── metrics // 评测指标的计算
├── models // 模型结构定义
├── train // 训练
└── utils // 工具函数的定义
2.数据
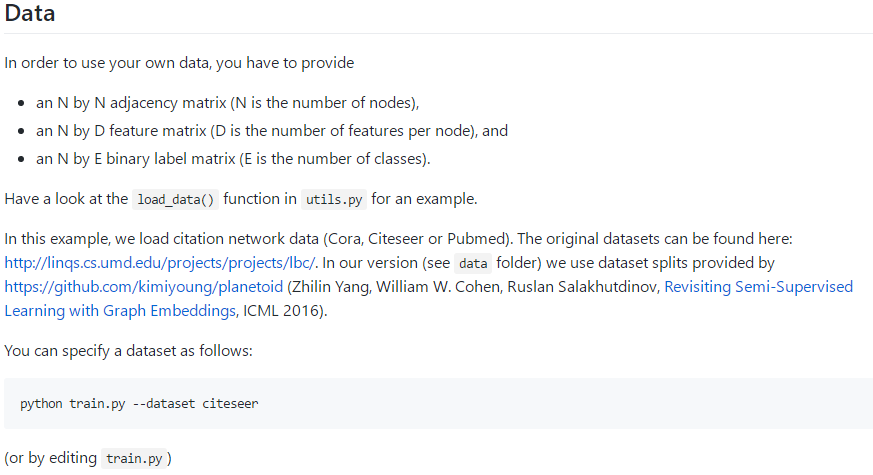
Data: cora,Citeseer, or Pubmed,在data文件夹下:
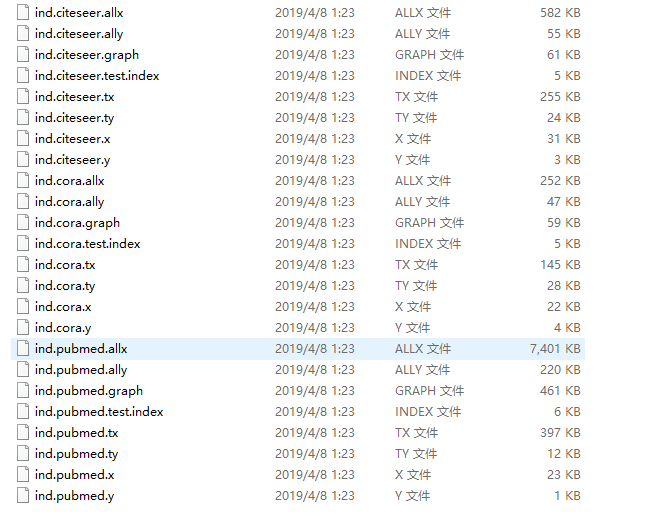
Original data:
Cora的数据集
包括2708份科学出版物,分为7类。引文网络由5429个链接组成。数据集中的每个发布都由一个0/1值的单词向量来描述,该向量表示字典中相应单词的存在或不存在。这部词典由1433个独特的单词组成。数据集中的自述文件提供了更多的细节。

CiteSeer文献分类
CiteSeer数据集包括3312种科学出版物,分为6类。引文网络由4732条链接组成。数据集中的每个发布都由一个0/1值的单词向量来描述,该向量表示字典中相应单词的存在或不存在。该词典由3703个独特的单词组成。
数据集中的自述文件提供了更多的细节。

CiteSeer for Entity Resolution
为了实体解析,CiteSeer数据集包含1504个机器学习文档,其中2892个作者引用了165个作者实体。对于这个数据集,惟一可用的属性信息是作者名。完整的姓总是给出的,在某些情况下,作者的全名和中间名是给出的,其他时候只给出首字母。
PubMed糖尿病数据库
由来自PubMed数据库的19717篇与糖尿病相关的科学出版物组成,分为三类。引文网络由44338个链接组成。数据集中的每个出版物都由一个TF/IDF加权词向量来描述,这个词向量来自一个包含500个唯一单词的字典。数据集中的自述文件提供了更多的细节。

以下以cora数据集为例:



数据集预处理: