基于golang的爬虫实战
前言
爬虫本来是python的强项,前期研究过scrapy,也写过一些简单的爬虫小程序,但是后来突然对golang产生兴趣,决定写写爬虫练练手。由于本人golang萌新,有错误之处,欢迎指正。
大致思路
- 由于现在动态页面比较多,因此考虑通过WebDriver驱动Chrome等页面渲染完成再抓取数据。(刚开始是用Phantomjs,后来这货不维护了,而且效率不算高)
- 一般爬虫程序运行在linux系统中,所以考虑Chrome的headless模式。
- 数据抓取到之后保存到CSV文件中,然后通过邮件发送出去。
不足之处
- 因为需要渲染,所以速度会降低不少,即便是不渲染图片,速度也不是很理想。
- 因为刚开始学习,所以多线程什么的也没加进去,怕内存会崩盘。
- 没有将数据写入到数据库,放到文件里毕竟不是最终方案。
需要的库
- github.com/tebeka/selenium
- golang版的selenium,能实现大部分功能。
- gopkg.in/gomail.v2
- 发送邮件用到的库,很久不更新了,但够用。
下载依赖包
- 本打算用dep管理依赖,结果这货坑还挺多,未研究明白不敢误人,暂时放弃。
- 通过go get 下载依赖包
go get github.com/tebeka/selenium
go get gopkg.in/gomail.v2
代码实现
- 启动chromedriver,用来驱动Chrome浏览器。
// StartChrome 启动谷歌浏览器headless模式
func StartChrome() {
opts := []selenium.ServiceOption{}
caps := selenium.Capabilities{
"browserName": "chrome",
}
// 禁止加载图片,加快渲染速度
imagCaps := map[string]interface{}{
"profile.managed_default_content_settings.images": 2,
}
chromeCaps := chrome.Capabilities{
Prefs: imagCaps,
Path: "",
Args: []string{
"--headless", // 设置Chrome无头模式
"--no-sandbox",
"--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7", // 模拟user-agent,防反爬
},
}
caps.AddChrome(chromeCaps)
// 启动chromedriver,端口号可自定义
service, err = selenium.NewChromeDriverService("/opt/google/chrome/chromedriver", 9515, opts...)
if err != nil {
log.Printf("Error starting the ChromeDriver server: %v", err)
}
// 调起chrome浏览器
webDriver, err = selenium.NewRemote(caps, fmt.Sprintf("http://localhost:%d/wd/hub", 9515))
if err != nil {
panic(err)
}
// 这是目标网站留下的坑,不加这个在linux系统中会显示手机网页,每个网站的策略不一样,需要区别处理。
webDriver.AddCookie(&selenium.Cookie{
Name: "defaultJumpDomain",
Value: "www",
})
// 导航到目标网站
err = webDriver.Get(urlBeijing)
if err != nil {
panic(fmt.Sprintf("Failed to load page: %s\n", err))
}
log.Println(webDriver.Title())
}
通过上述代码即可实现通过代码启动Chrome并跳转到目标网站,方便下一步的数据获取。
- 初始化CSV,数据存放地
// SetupWriter 初始化CSV
func SetupWriter() {
dateTime = time.Now().Format("2006-01-02 15:04:05") // 格式字符串是固定的,据说是go语言诞生时间,谷歌的恶趣味...
os.Mkdir("data", os.ModePerm)
csvFile, err := os.Create(fmt.Sprintf("data/%s.csv", dateTime))
if err != nil {
panic(err)
}
csvFile.WriteString("\xEF\xBB\xBF")
writer = csv.NewWriter(csvFile)
writer.Write([]string{"车型", "行驶里程", "首次上牌", "价格", "所在地", "门店"})
}
数据抓取
这一部分是核心业务,每个网站的抓取方式都不一样,但是思路都是一致的,通过xpath,css选择器,className, tagName等来获取元素的内容,selenium的api能实现大部分的操作功能,通过selenium源码可以看到,核心api包括WebDriver与WebElement,下面写下我抓取二手车之家北京二手车数据的过程,其他网站可参考改过程。
- 通过Safari浏览器打开二手车之家网站,得到北京二手车主页连接
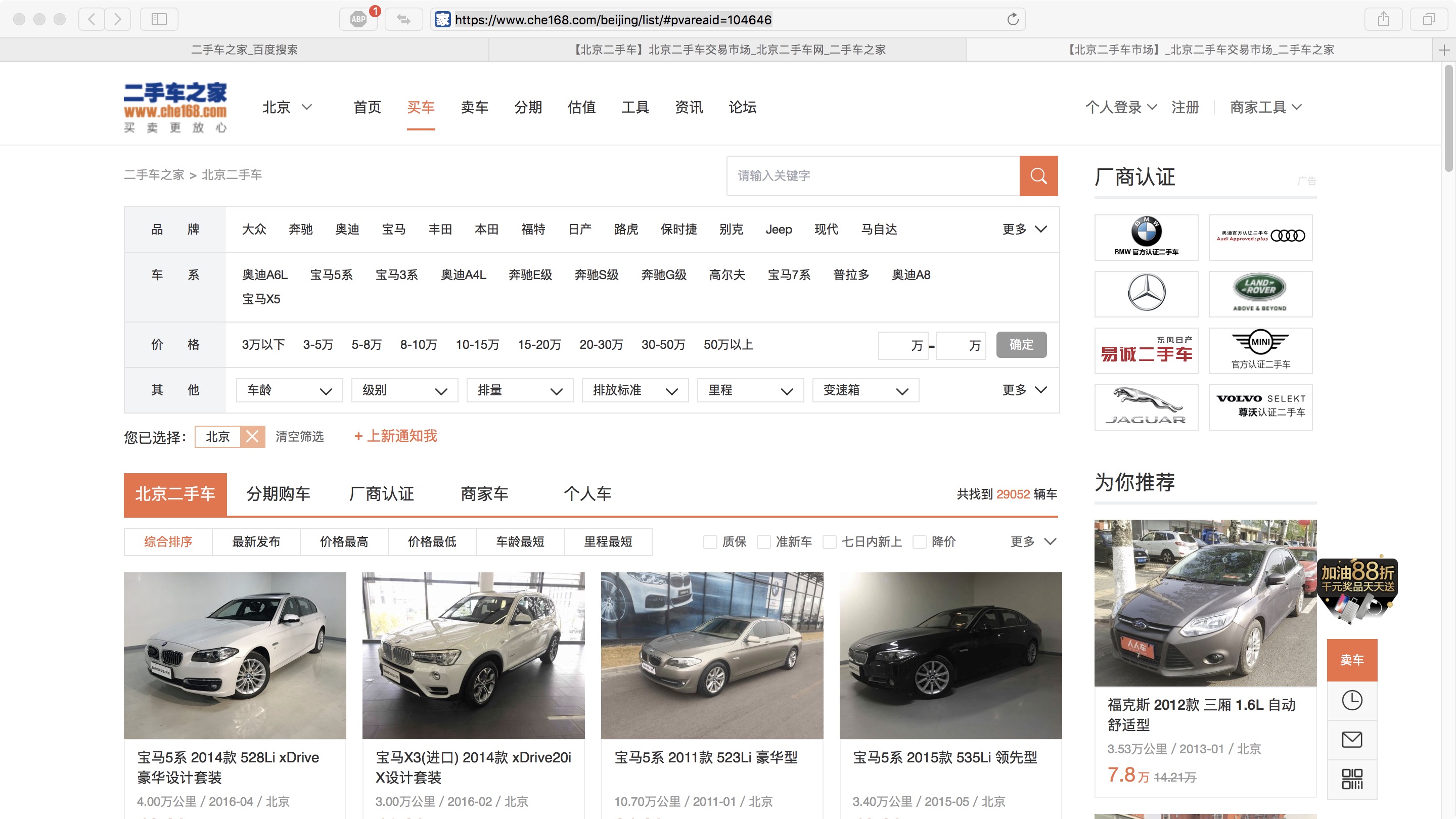
const urlBeijing = "https://www.che168.com/beijing/list/#pvareaid=104646"
- 在页面上右键点击“检查元素”进入开发者模式,可以看到所有的数据都在这里面
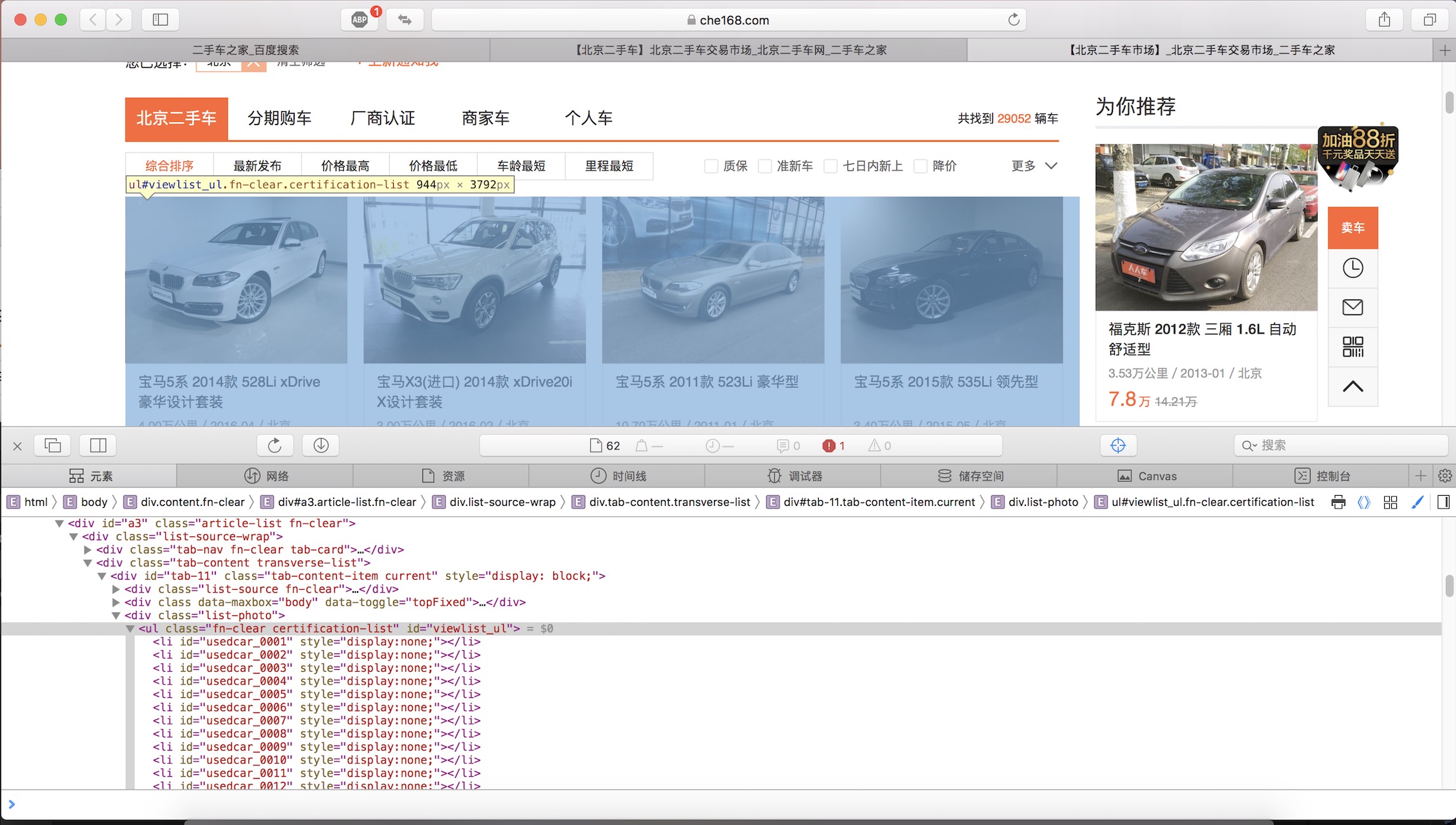
<ul class="fn-clear certification-list" id="viewlist_ul">
鼠标指向这一句右键,依次拷贝-XPath,即可得到改元素所在的xpath属性
//*[@id="viewlist_ul"]
然后通过代码
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
即可得到改段html的WebElement对象,不难看出这是所有数据的父容器,为了得到具体的数据需要定位到每一个元素子集,通过开发模式可以看到 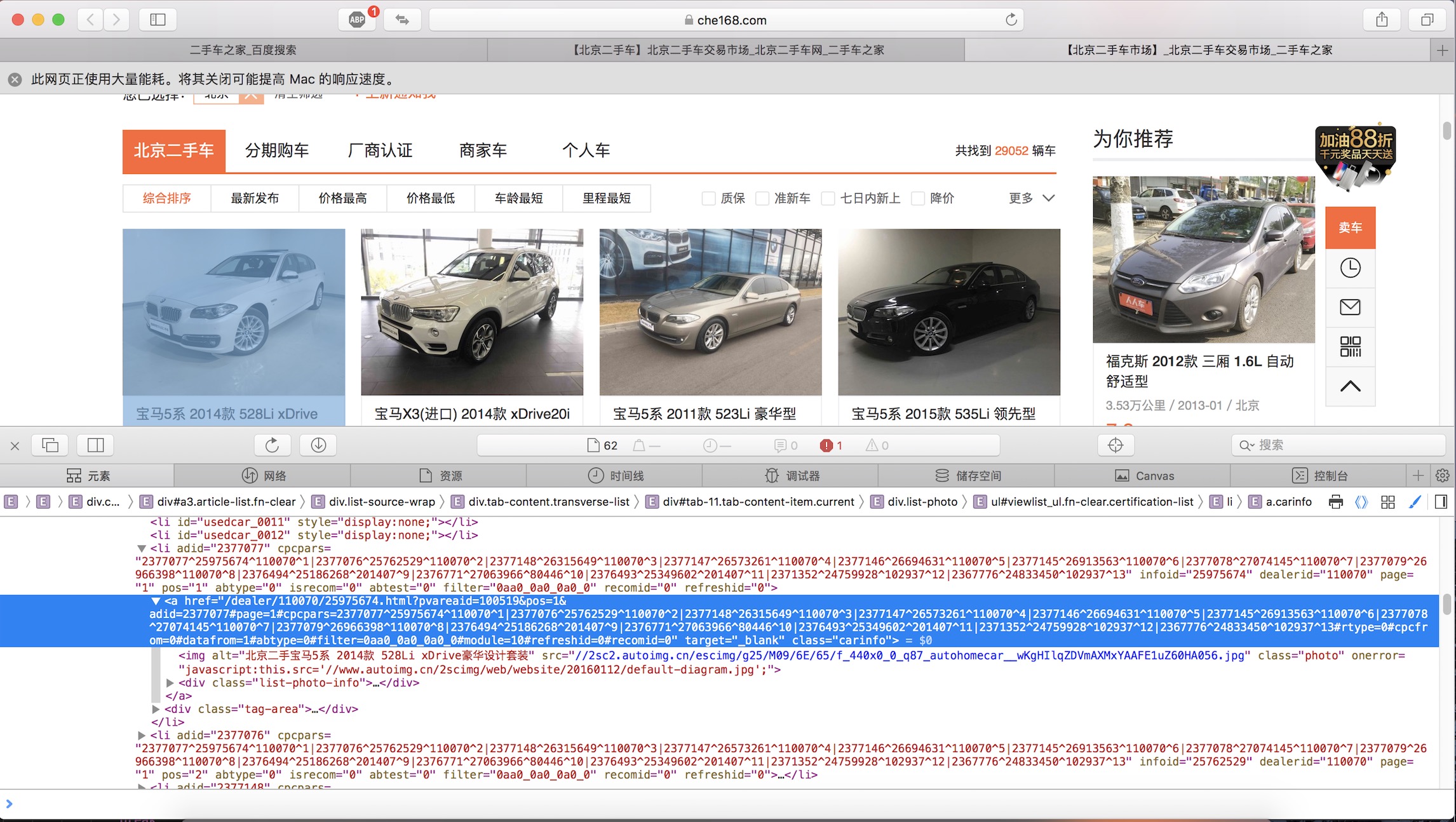
通过开发者工具可以得到class为carinfo,因为这个元素存在多个,所以通过
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
可以得到所有元素子集的集合,要得到每个子集里面的元素数据,需要对改集合进行遍历
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
// 因为有些数据在次级页面,需要跳转
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
// 获取车辆型号
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
...
// 数据写入CSV
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back() // 回退到上级页面重复步骤抓取
}
所有源代码如下,初学者,轻喷~~
// StartCrawler 开始爬取数据
func StartCrawler() {
log.Println("Start Crawling at ", time.Now().Format("2006-01-02 15:04:05"))
pageIndex := 0
for {
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
if err != nil {
panic(err)
}
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
if err != nil {
panic(err)
}
log.Println("数据量:", len(lists))
pageIndex++
log.Printf("正在抓取第%d页数据...\n", pageIndex)
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
priceElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[2]/div/ins")
var price string
if err != nil {
log.Println(err)
price = "暂无"
} else {
price, _ = priceElem.Text()
price = fmt.Sprintf("%s万", price)
}
log.Printf("price=[%s]\n", price)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[1]/span")
var miles string
if err != nil {
log.Println(err)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[1]/span")
if err != nil {
log.Println(err)
miles = "暂无"
} else {
miles, _ = milesElem.Text()
}
} else {
miles, _ = milesElem.Text()
}
log.Printf("miles=[%s]\n", miles)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[2]/span")
var date string
if err != nil {
log.Println(err)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[2]/span")
if err != nil {
log.Println(err)
date = "暂无"
} else {
date, _ = timeElem.Text()
}
} else {
date, _ = timeElem.Text()
}
log.Printf("time=[%s]\n", date)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[4]/span")
var position string
if err != nil {
log.Println(err)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[4]/span")
if err != nil {
log.Println(err)
position = "暂无"
} else {
position, _ = positionElem.Text()
}
} else {
position, _ = positionElem.Text()
}
log.Printf("position=[%s]\n", position)
storeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/div/div/div")
var store string
if err != nil {
log.Println(err)
store = "暂无"
} else {
store, _ = storeElem.Text()
store = strings.Replace(store, "商家|", "", -1)
if strings.Contains(store, "金牌店铺") {
store = strings.Replace(store, "金牌店铺", "", -1)
}
}
log.Printf("store=[%s]\n", store)
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back()
}
log.Printf("第%d页数据已经抓取完毕,开始下一页...\n", pageIndex)
nextButton, err := webDriver.FindElement(selenium.ByClassName, "page-item-next")
if err != nil {
log.Println("所有数据抓取完毕!")
break
}
nextButton.Click()
}
log.Println("Crawling Finished at ", time.Now().Format("2006-01-02 15:04:05"))
sendResult(dateTime)
}
- 发送邮件
全部代码如下,比较简单,不做赘述
func sendResult(fileName string) {
email := gomail.NewMessage()
email.SetAddressHeader("From", "re**[email protected]", "张**")
email.SetHeader("To", email.FormatAddress("li**[email protected]", "李**"))
email.SetHeader("Cc", email.FormatAddress("zhang**[email protected]", "张**"))
email.SetHeader("Subject", "二手车之家-北京-二手车信息")
email.SetBody("text/plain;charset=UTF-8", "本周抓取到的二手车信息数据,请注意查收!\n")
email.Attach(fmt.Sprintf("data/%s.csv", fileName))
dialer := &gomail.Dialer{
Host: "smtp.163.com",
Port: 25,
Username: ${your_email}, // 替换自己的邮箱地址
Password: ${smtp_password}, // 自定义smtp服务器密码
SSL: false,
}
if err := dialer.DialAndSend(email); err != nil {
log.Println("邮件发送失败!err: ", err)
return
}
log.Println("邮件发送成功!")
}
- 最后记的回收资源
defer service.Stop() // 停止chromedriver
defer webDriver.Quit() // 关闭浏览器
defer csvFile.Close() // 关闭文件流
总结
- 初学golang,纯粹拿爬虫项目练手,代码比较粗糙没有任何工程性可言,希望不会误人子弟。
- 由于golang爬虫基本没有其他项目可借鉴,所以里面也有自己的一些研究所得吧,也希望能帮到别人吧。
- 最后,安利一个大神写的爬虫框架Pholcus,功能强大,是目前比较完善的一个框架。