版权声明:转载请注明出处,谢谢。 https://blog.csdn.net/butterfly5211314/article/details/82085299
golang最简单的爬虫示例,爬取笔者的博客列表第一页面的数据。
仅为入门练习示例。
代码如下:
package main
import (
"encoding/json"
"io/ioutil"
"log"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
// golang抓取个人博客信息
// 作为示例,只抓取第一页的数据
const (
blogUrl = "https://blog.csdn.net/butterfly5211314/article/list/1"
resultFilename = "csdnCrawler/result.json"
)
var (
forgeHeaders = map[string]string{
`User-Agent`: `Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36`,
}
// regexp of link & title & type
//<a href="https://blog.csdn.net/butterfly5211314/article/details/79877300" target="_blank">
//<span class="article-type type-1">
//原 </span>
//git常用操作(不定期更新) </a>
lttRe = regexp.MustCompile(`<a href="(https://blog.csdn.net/butterfly5211314/article/details/[\d]+)"[^>]*>\s*<span[^>]*>([^<]*)</span>([^<]+)</a>`)
postTimeRe = regexp.MustCompile(`<span class="date">([^<]+)</span>`)
readCountRe = regexp.MustCompile(`span class="read-num">阅读数:([^<]+)</span>`)
commentCountRe = regexp.MustCompile(`<span class="read-num">评论数:([^<]+)</span>`)
)
type BlogItem struct {
Link string // 文章详情链接
Type string // 文章类型: 原创, 翻译等
Title string // 文章标题
PostTime string // 发表时间
ReadCount int // 阅读数
CommentCount int // 评论数
}
// get all contents as []byte
func fetch(url string) ([]byte, error) {
client := http.Client{}
req, err := http.NewRequest("GET", blogUrl, nil)
if err != nil {
return nil, err
}
// add header
for k, v := range forgeHeaders {
req.Header.Add(k, v)
}
// send request
resp, err := client.Do(req)
if err != nil {
return nil, err
}
// defer close
defer resp.Body.Close()
return ioutil.ReadAll(resp.Body)
}
// parse content to slice of BlogItem
func parse(html string) []BlogItem {
ltts := lttRe.FindAllStringSubmatch(html, -1)
postTime := postTimeRe.FindAllStringSubmatch(html, -1)
readCount := readCountRe.FindAllStringSubmatch(html, -1)
commentCount := commentCountRe.FindAllStringSubmatch(html, -1)
var blogs []BlogItem
for i, ltt := range ltts {
blogs = append(blogs, BlogItem{
Link: ltt[1],
Type: strings.TrimSpace(ltt[2]),
Title: strings.TrimSpace(ltt[3]),
PostTime: postTime[i][1],
ReadCount: field2int(readCount[i][1]),
CommentCount: field2int(commentCount[i][1]),
})
}
return blogs
}
// string to int
func field2int(s string) int {
ret, err := strconv.Atoi(s)
if err != nil {
ret = 0
}
return ret
}
func write2file(filename string, contents []byte) error {
_, err := os.Stat(filename)
if err == nil {
log.Printf("file %s is existed, it will be truncated", filename)
}
return ioutil.WriteFile(filename, contents, 666)
}
func start() {
contents, err := fetch(blogUrl)
if err != nil {
panic(err)
}
items := parse(string(contents))
bytes, err := json.MarshalIndent(items, "", " ")
if err != nil {
log.Printf("json error: %v", err)
return
}
err = write2file(resultFilename, bytes)
if err != nil {
log.Printf("write2file error: %v", err)
return
}
log.Printf("done!")
}
func main() {
start()
}
抓取结果:
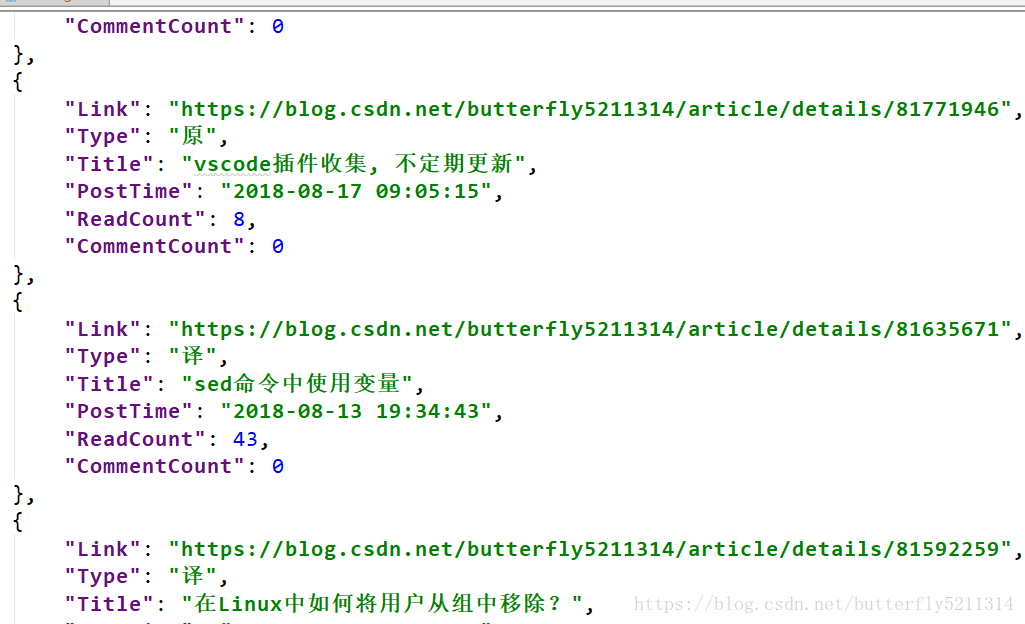
欢迎补充指正!