SDS
前提:在redis中,C字符串只会作为字符串字面量用在一些无须对字符串进行修改的地方,比如打印日志:
redisLog(REDIS_WARNING, “Redis is ready to exit”)
因此,redis构建了一种简单动态字符串(simple dynamic string, SDS)的抽象类型,并将SDS用作redis的默认字符串表示。
比如:
redis> SET msg “Hello World”
OK
其中键值对的键是一个字符串对象,对象底层是一个保存着字符串 ”msg” 的SDS。
键值对的值也是一个字符串对象,对象底层是一个保存着字符串 “Hello World” 的SDS。
SDS的用途总结:
- 保存数据库中的字符串值
- 用作缓冲区(buffer)
- AOF模块中的AOF缓冲区
- 客户端状态中的输入缓冲区
下面给出SDS的结构:
struct SDS {
int len; // buf数组中已使用字节数,并未算上’\0’字符
int free; // buf数组中未使用字节数
char buf[]; // 用于保存字符串
};
SDS与C字符串的区别
1. O(1)复杂度获取字符串的长度。这个就不需要解释了。
2. 杜绝缓冲区溢出。比如在使用strcat函数时,在这有个扩充知识要讲,即变量在内存中是如何存储的。
C++将进程内存分为(地址由高到低):栈、堆、BSS(Block Start of Symbol)段,数据段,代码段。其中栈是用来存储局部变量、函数参数和返回地址的,在VS中,栈是由高到低分配内存的(很重要!因为它最特殊0.0);堆是存储动态分配内存的变量的地方,如new和malloc函数就是在这分配内存的;BSS段是用来分配未初始化或初始化为0的全局变量和静态变量;数据段是用来存储初始化值不为0的全局变量和静态变量。代码段则是用来存储代码、静态只读数据的地方。
Ok,有了上面的基础后,让我们来做个实验巩固一下上面的内容。
char s1[] = "Hello";
printf("%p %p\n", s1, &s1[1]);
char *s2 = new char[6];
s2 = "World";
printf("%p %p\n", s2, &s2[1]);

可以明显地看到,局部变量s1和s2的地址区别,由于s2的内存是动态分配的,故其地址值小于s1。此外,我们可以看到,s1字符串在栈中是怎么放置的,起始地址为低地址,说明(低地址->高地址)H->e->l->l->o。
ok,这很明显了,如果我们将s2拼接到s1后面,会发生什么?
由于s1的最后一个字符是在栈顶,那么在拼接后,会返回栈越界错误!这也是strcat函数不安全的地方!而SDS在拼接字符串时,会考虑有没有足够的空间(free字段的用处出现了),具体细节后面再讲,先填坑先orz…
// 这里是全局变量
int a;
int aa = 0;
int b = 1;
const int con = 0; // 常量
// 到这为止
printf("%p %p\n", &a, &aa);
printf("%p\n", &b);
printf("%p\n", &con);
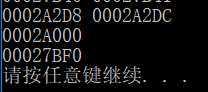
可以看出,全局变量a,aa,b之间的区别,是不是和我们上面说的一毛一样!当然,常量也是!
到这就可以C++的内存就介绍完了。让我们继续介绍SDS和C字符串的区别吧(汗)
3. 减少修改字符串时带来的内存重新分配次数。SDS通过未使用空间解除了字符串长度和底层数组长度的关联。(因为SDS的buf数组长度是len+free+1(别忘了’\0’哦)。比如说在剪切字符串时,SDS并不会释放剪切的内存空间,而是增大free。