一、项目概要
这里分析的源码来自于GitHub,是一份关于使用卷积神经网络以及循环神经网络进行中文文本分类的开源项目代码。
在分析源码之前我们首先来看这份代码的目录结构(如下图所示)
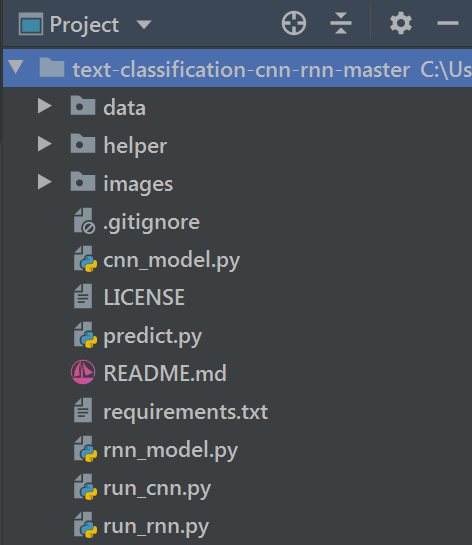
从上面可以看到,该项目由于结构简单,所以并没有以较多的文件夹将.py文件分开保存,而是集中到了一起,把所有的源代码都放在主目录下。
但是每个.py文件的命名又是简单明了,让人看到命名后就知道每个.py文件所要实现的功能(或所写的内容是什么)。
整个项目的大致流程是这样:将预先设定好的中文文本数据集载入,随后建立相关的cnn与rnn训练模型,最后通过一定时间有限次迭代,最后输入分类的准确率变化图片并打印保存。
二、代码分析
在了解了整个项目的流程后我们再对具体的代码细节进行分析。
1、项目文件及功能
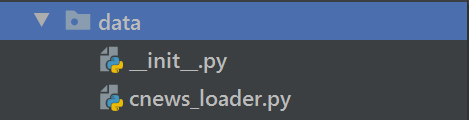
文件data中所包含的内容即是加载相应数据集的方法以及存放相应的数据集:
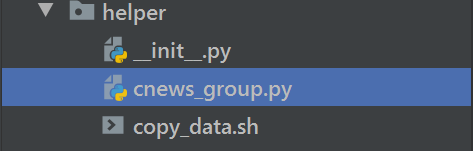
文件helper中所包含的内容则是为了达到训练目的要对原数据集进行一定的格式处理,从而适用于设定的模型。
images文件则是保存了在进行了相应训练后所得的的分类准确率的曲线
2,代码命名规范
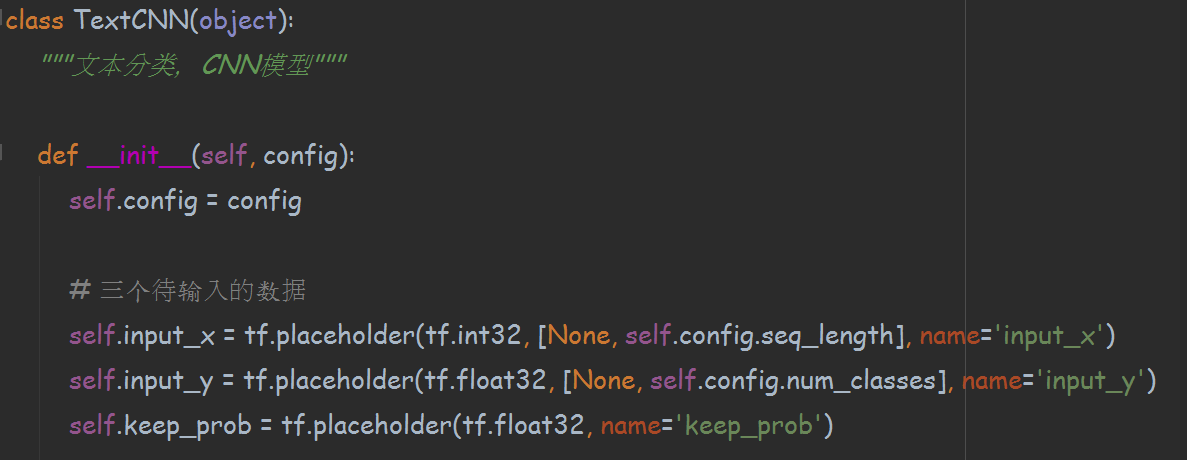
本套源码中的函数命名均采用小写英文单词加下划线的组合,而类名,变量名的命名规则也基本一致,唯一不同在于类名的首字母一般大写,方便区分类与方法。这样的命名方式的好处在于意义明确,使得阅读者很方便地了解到编写者的意图。
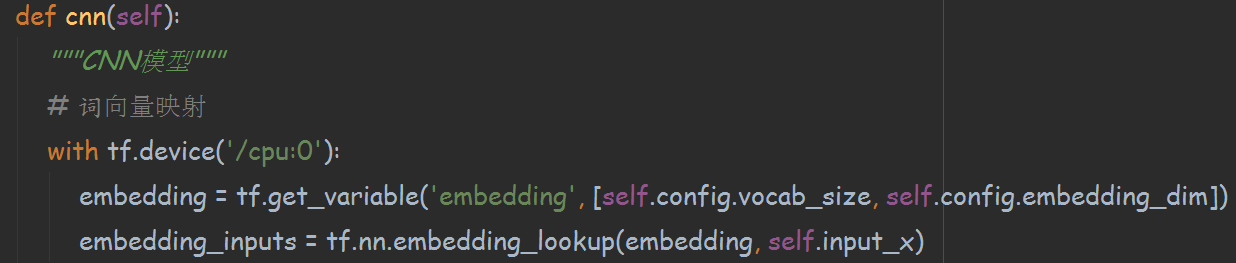

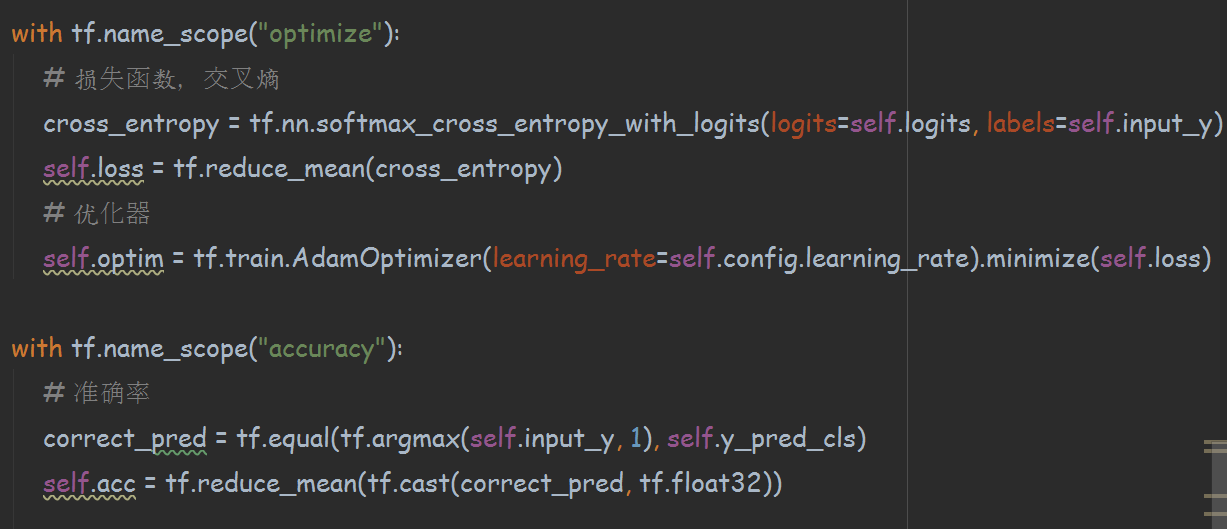
同时,由于本套源码采用的是tensorflow框架,在每个with 语句进行之前也都有相应的注释来解释当前要进行的操作的含义,方便理解。
三、总结及改进意见
总体而言,由于python代码缩进要求严格且编码较为简单,同时该代码也采用了通用框架,因此代码比较规范,我认为需要改进的地方就是可以把模型的建立与运行等几个关键的.py文件放入一个文件夹,这样整个项目的结构就会十分清晰,同时也便于专业人员阅读。