7.2.1 创建正则表达式对象
Python所有正则表达式函数都在re模块中, import re 即可。
Regex对象 = re.compile('正则表达式')
>>> import re >>> phoneRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') # 电话号码格式 415-555-4343 >>> type(phoneRegex) <class '_sre.SRE_Pattern'>
7.2.2 匹配Regex对象
Regex对象的search()方法查找传入的字符串,寻找该正则表达式的所有匹配。
如果字符串中没有找到该正则表达式模式,search()方法返回None
如果search()方法找到了匹配模式,返回Match对象。Match对象有个group()方法,该方法返回对应的匹配对象。
注:
推荐向re.compile()中传递原始字符串,否则为了在正则中得到\d,我们需要输入\\d
1 >>> import re 2 >>> phoneRegex = re.compile('\d\d\d-\d\d\d-\d\d\d\d') #没有使用原始字符串,也没有转义,但是效果和使用原始字符串相同 3 >>> mo = phoneRegex.search('my phone number is 333-444-5555') 4 >>> mo.group() 5 '333-444-5555'
6 >>> phoneRegex = re.compile('\\d\\d\\d-\\d\\d\\d-\\d\\d\\d\\d')#没有使用原始字符串,但是转义了
7 >>> mo = phoneRegex.search('my phone number is 333-444-5555')
8 >>> mo.group()
9 '333-444-5555'
10 >>> phoneRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')#使用原始字符串,推荐
11 >>> mo = phoneRegex.search('my phone number is 333-444-5555')
12 >>> mo.group()
13 '333-444-5555'
14 >>> phoneRegex = re.compile(r'\\d\\d\\d-\\d\\d\\d-\\d\\d\\d\\d') #使用过原始字符串,同时也是用了转义,无法匹配到333-444-5555
15 >>> mo = phoneRegex.search('my phone number is 333-444-5555')
16 >>> mo.group() 17 Traceback (most recent call last):
18 File "<pyshell#179>", line 1, in <module> 19 mo.group()
20 AttributeError: 'NoneType' object has no attribute 'group'
21 >>> mo = phoneRegex.search('my phone number is \\d\\d\\d-\\d\\d\\d-\\d\\d\\d\\d') #只能匹配到 \\d\\d\\d-\\d\\d\\d-\\d\\d\\d\\d
22 >>> mo.group()
7.2.3 正则表达式匹配复习
1 用import re导入正则表达式模块 2 用re.compile()函数创建一个Regex对象(记得使用原始字符串) 3 想Regex对象的search()方法传入想要查找的字符串,它返回一个Match对象或None 4 调用Match对象的group()方法,返回实际匹配到的文本字符串
7.3 用正则表达式匹配更多的模式
7.3.1 利用括号分组
在正则表达式中添加括号即可在正则表达式中创建分组。
正则表达式字符串的第一对括号就是第1组,第二队括号就是第2组。向group()匹配对象方法传入参数 1 或 2, 就可以取得匹配文本的不同部分。
向group()方法中传入0或不传参数,将返回整个匹配的文本。
如果想一次返回所有的分组,使用groups() 方法,该方法返回的是多个分组组成的元组。可以使用多重赋值: areaCode, mainNum = mo.groups()
1 >>> import re 2 >>> phoneRegex = re.compile(r'(\d\d\d)-(\d\d\d-\d\d\d\d)') 3 >>> mo = phoneRegex.search('my phone number is 444-555-6666') 4 >>> mo.group(1) 5 '444' 6 >>> mo.group(2) 7 '555-6666' 8 >>> mo.group() 9 '444-555-6666' 10 >>> mo.group(0) 11 '444-555-6666' 12 >>> areaCode = mo.group(1) # 分组赋值 13 >>> mainNumber = mo.group(2)# 分组赋值
14 >>> areaCode, mainNum
('444', '555-6666')
15 >>> mo.groups()
('444', '555-6666')
因为括号在正则表达式中有特殊含义,如果需要匹配文本中的括号,需要使用转义字符。
1 >>> import re 2 >>> phoneRegex = re.compile(r'(\(\d\d\d)\) (\d\d\d-\d\d\d\d)') #正则表达式中的括号需要转义 3 >>> mo = phoneRegex.search('my phone number is (444) 555-6666') 4 >>> mo.group() 5 '(444) 555-6666'
7.3.2 用管道符匹配多个分组
希望匹配多个正则表达式中的一个时,可以使用此方法。
1 >>> import re 2 >>> heroRegex = re.compile(r'Batman|Tina Fey') 3 >>> mo = heroRegex.search('they are Batman and Tina Fey') 4 >>> mo.group()#返回第一次出现的匹配文本
7.3.3 用问号实现可选匹配(0 或 1次)
1 batRegex = re.compile(r'Bat(wo)?man') 2 模式wo是可选分组,在该正则表达式匹配的文本中,wo可出现0或1次 3 该正则即可匹配Batman,也可匹配Batwoman
7.3.4 用星号匹配0或多次
星号之前的分组,可在文本中出现任意次数。
7.3.5 用加号匹配1次或多次
加号之前的分组内容,至少出现1次
7.3.6 用花括号匹配特定次数
{ha}{3}:ha反复出现3次 可被匹配
{ha}{3,5}:ha反复出现3或4或5次 可被匹配
{ha}{,3}:ha出现0或1或2或3次 可被匹配
{ha}{3,}:ha出现3次以上 可被匹配
7.4 贪心和非贪心匹配
Python的正则表达式默认是 贪心 匹配,即 会尽可能匹配最长的字符串
1 >>> import re 2 >>> greedyRegex = re.compile(r'(ha){3,5}') 3 >>> mo = greedyRegex.search('hahahahahaha') 4 >>> mo.group() 5 'hahahahaha' # 贪心匹配的结果
1 >>> import re 2 >>> nongreedyRegex = re.compile(r'(ha){3,5}?')#非贪心匹配,需要在分组后面加上 ? 3 >>> mo = nongreedyRegex.search('my name is hahahahaha') 4 >>> mo.group()
'hahaha'
注:问号在正则表达式中有两种角色:
- 声明非贪婪匹配
- 表示可选分组
7.5 findall()方法
findall()方法在Regex对象上调用
返回的不是Match对象,而是字符串列表或者字符串元组列表
1 >>> import re 2 3 >>> phoneRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') #无分组的正则表达式 4 >>> matchStrList = phoneRegex.findall('my celephone number is 333-444-5555, and my work number is 666-777-8888') 5 >>> matchStrList 6 ['333-444-5555', '666-777-8888']#findall返回的是字符串列表 7 8 >>> phoneRegexGroup = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)')#有分组的正则表达式 9 >>> phoneRegexGroup.findall('my celephone number is 333-444-5555, and my work number is 666-777-8888') 10 [('333', '444', '5555'), ('666', '777', '8888')]#findall返回的是 字符串元组的列表
7.6 字符串分类
缩写分类 表示 备注
\d 0-9任何数字 相当于(0|1|2|3|$|5|6|7|8|9)
\D 除0到9数字之外的任何字符
\w 任何 字母、数字、下划线 可以认为是在匹配单词
\W 除 字母、数字、下划线之外的任何字符
\s 匹配空格、制表符、换行符 可以认为是匹配 空白
\S 除空格、制表符、换行符以外的任何字符
7.7 建立自己的字符分类
有时相匹配一组字符串,但是缩写的字符分类(\d \w \s)太宽泛,此时,你可以通过[]方括号建立自己的正则分类。
比如,字符分类[aeiouAEIOU]匹配所有的元音字母,不论大小写。
也可使用短横线-表示字母或数字范围。如,[a-zA-Z0-9]表示匹配所有大小写字母和数字
注:在方括号内,普通的正则表达式符号不会被解释,即 不需要在前面加上\ . * ? () 等 正则表达式符号。
如果想匹配0到5和一个句点和一个*, 如下所示:(方括号内的任意字符均可能被匹配)
匹配 . 和 * 也不需要在方括号内部加上 \ 来转义。
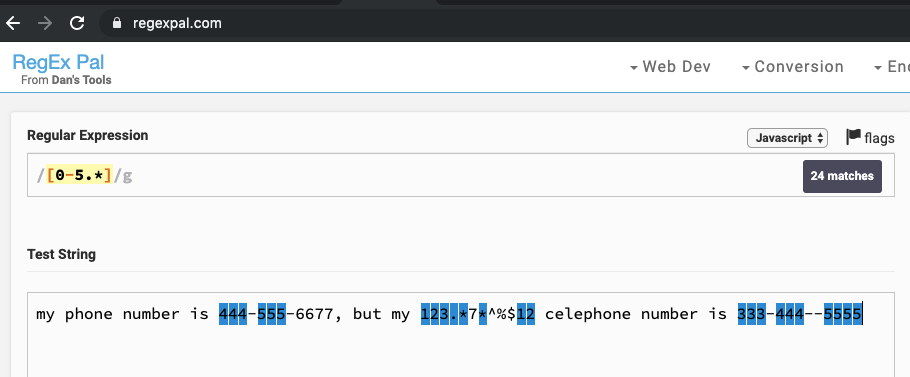
通过在自定义字符分类的左方括号后加上一个插入字符(^),表示 非字符类,即 匹配该自定义分类之外的其他字符。如:
[^aeiouAEIOU]表示匹配所有非元音字符。
7.8 插入字符(^)和美元字符($)
正则表达式开始处的插入字符(^),表示待匹配字符串必须以该正则表达式模式开始
正则表达式结束处的美元字符($),表示待匹配字符串必须以该正在表达式模式结束
r'^\d$':该正则匹配以数字开头和结束的字符串。
7.9 通配符
句点(.) 表示 通配符,可以匹配除 换行符 之外的所有其他字符。
7.9.1 用点-星匹配所有字符
点-星(.*):默认使用 贪心匹配模式,(.*?) 非贪心匹配模式
7.9.2 使用句点匹配换行符
1 >>> newLineRegex = re.compile(r'.*',re.DOTALL) #可以匹配到所有的文本,包括换行符 2 >>> newLineRegex.search('serve the pulic trust.\nprotect the innocnet') 3 >>> mo = newLineRegex.search('serve the pulic trust.\nprotect the innocnet') 4 >>> mo.group() 5 'serve the pulic trust.\nprotect the innocnet' 6 7 >>> noNewLineRegex = re.compile('.*') #可以匹配到换行符之前的文本 8 >>> mo = noNewLineRegex.search('serve the pulic trust.\nprotect the innocnet') 9 >>> mo.group() 10 'serve the pulic trust.'
7.10 正则表达式复习

7.11 不区分大小写的匹配
regex = re.compile(r'正则表达式', re.I), re.I 也可以写成 re.IGNORECASE
7.12 用sub()方法替换字符串
通过sub()方法可以用新的字符串替换匹配到的模式
1 >>> import re 2 >>> namesRegex= re.compile(r'Agent \w+') 3 >>> line = 'Agent Alice gave the secret documents to Agent Bob' 4 >>> lineSub = namesRegex.sub('CENSORED', line) 5 >>> lineSub #lineSub变为新的内容,但是line是没有改变的,line是字符串,无法改变 6 'CENSORED gave the secret documents to CENSORED'
7.13 管理复杂的正则表达式
复杂的正则表达式不好阅读和管理,为了解决这个问题,可以使用 三重引号 + re.VERBOSE解决, 如下的E-Mail地址正则表达式:
emailRegex = re.compile(r"""(
[a-zA-Z0-9._%+-]+ # 匹配用户名,可以为大小写字母、数字、.、_、%、+、- 等, 至少一次
@ # @ 符号
[a-zA-Z0-9.-]+ # 域名,可以为大小写字母、数字、.、-,至少一次
(\.[a-zA-Z]{2,4}) # 不一定是.com, 可以是.anything
)""", re.VERBOSE)