查询所有列
SELECT * FROM 表名;
结果集
数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。
结果集
1.通过查询语句查询出来的数据以表的形式展示我们称这个表为虚拟结果集,存放在内存中。
2.查询返回的结果集是一张虚拟表。
查询指定列的数据
SELECT 列名1,列名2... FROM 表名;
条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用一些运算符及关键字:
一.条件查询运行符及关键字
=(等于)、!=(不等于)、<>(不等于)、<(小于)、<=(小于等于)、>(大于)、>=(大于等于);
BETWEEN…AND; 值在什么范围
IN(set); 固定的范围值
IS NULL; 为空
IS NOT NULL; 不为空
AND; 与
OR; 或
NOT; 非
二、使用
查询性别为男,并且年龄为20的学生记录
SELECT * FROM students WHERE gender='男' AND age=20;
查询学号为1001 或者 名为zs的记录
SELECT * FROM students WHERE id ='1001' OR name='zs';
查询学号为1001,1002,1003的记录
SELECT * FROM students WHERE id='1001' OR id='1002' OR 1001='1003';
SELECT * FROM students WHERE id IN('1001','1002','1003');
SELECT * FROM students WHERE id NOT IN ('1001','1002','1003');
查询年龄为null的记录
SELECT * FROM students WHERE age IS NULL;
查询年龄在18到20之间的学生记录
SELECT * FROM students WHERE age>=18 AND age<=20;
SELECT * FROM students WHERE age BETWEEN 18 AND 20;
查询性别非男的学生记录
SELECT * FROM students WHERE gender !='男';
查询姓名不为null的学生记录
SELECT * FROM students WHERE name IS NOT NULL;
模糊查询
根据指定的关键进行查询
使用LIKE关键字后跟通配符
通配符
_ :任意一个字符
%:任意0~n个字符
使用
1.查询姓名由5个字符构成的学生记录
SELECT * FROM students WHERE name LIKE '_____';
模糊查询必须使用LIKE关键字。其中 “_”匹配任意一个字符,5个“_”表示5个任意字符。
2.查询姓名由5个字符构成,并且第5个字符为“s”的学生记录
SELECT * FROM students WHERE name LIKE '____s';
3.查询姓名以“m”开头的学生记录
SELECT * FROM students WHERE name LIKE 'm%';
其中“%”匹配0~n个任何字符。
4.查询姓名中第2个字符为“u”的学生记录
SELECT * FROM students WHERE name LIKE '_u%';
5.查询姓名中包含“s”字符的学生记录
SELECT * FROM stu WHERE name LIKE '%s%';
字段控制查询
1.去除重复记录
SELECT DISTINCT name FROM students;
2.把查询字段的结果进行运算,必须都要是数据型
SELECT *,字段1+字段2 FROM 表名;
列有很多记录的值为NULL,因为任何东西与NULL相加结果还是NULL,所以结算结果可能会出现NULL。下面使用了把NULL转换成数值0的函数IFNULL:
SELECT *,age+IFNULL(score,0) FROM students;
3.对查询结果起别名
在上面查询中出现列名为sx+IFNULL(yw,0),这很不美观,现在我们给这一列给出一个别名,为total:
SELECT *, yw+IFNULL(sx,0) AS total FROM score;
省略 AS SELECT *, yw+IFNULL(sx,0) total FROM score; (建议不要省略)
排序
对查询的结果进行排序,使用关键字ORDER BY
一、排序类型
1.升序ASC,从小到大 默认
2.降序DESC,从大到小
二、使用
对所有员工的薪水进行升序排序
SELECT *FROM employee ORDER BY selary ASC;
查询所有员工,按薪水降序排序
SELECT * FROM employee ORDER BY salary DESC;
查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
SELECT * FROM employee ORDER BY salary DESC, id ASC;
聚合函数
对查询的结果进行统计计算
一、常用聚合函数
COUNT(): 统计指定列不为NULL的记录行数;
MAX(): 计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN(): 计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM(): 计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG(): 计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
二、使用
1.COUNT
查询employee表中记录数:
SELECT COUNT(*) AS total_record FROM employee;
查询员工表中有绩效的人数
SELECT COUNT(performance) FROM employee;
查询员工表中月薪大于2500的人数:
SELECT COUNT(*) FROM employee WHERE salary > 2500;
统计月薪与绩效之和大于5000元的人数:
SELECT COUNT(*) FROM employee WHERE salary+IFNULL(performance,0) > 5000;
查询有绩效的人数,和有管理费的人数:
SELECT COUNT(performance), COUNT(manage) FROM employee;
2.SUM和AVG
查询所有雇员月薪和:
SELECT SUM(salary) FROM employee;
查询所有雇员月薪和,以及所有雇员绩效和
SELECT SUM(salary), SUM(performance) FROM employee;
查询所有雇员月薪+绩效和:
SELECT SUM(salary+IFNULL(performance,0)) FROM employee;
统计所有员工平均工资:
SELECT AVG(salary) FROM employee;
3.MAX和MIN
查询最高工资和最低工资:
SELECT MAX(salary), MIN(salary) FROM employee;
分组查询
一.什么是分组查询
将查询结果按照1个或多个字段进行分组,字段值相同的为一组
二.分组使用
SELECT gender from employee GROUP BY gender;
根据gender字段来分组,gender字段的全部值只有两个('男'和'女'),所以分为了两组
当group by单独使用时,只显示出每组的第一条记录
所以group by单独使用时的实际意义不大
分组注意事项
在使用分组时,select后面直接跟的字段一般都出现在group by 后
group by + group_concat()
group_concat(字段名)可以作为一个输出字段来使用
表示分组之后,根据分组结果,使用group_concat()来放置每一组的某字段的值的集合
SELECT gender,GROUP_CONCAT(name) from employee GROUP BY gender;
group by + 聚合函数
通过group_concat()的启发,我们既然可以统计出每个分组的某字段的值的集合,那么我们也可以通过集合函数来对这个"值的集合"做一些操作
使用
查询每个部门的部门名称和每个部门的工资和
SELECT department,SUM(salary) FROM employee GROUP BY department;
查询每个部门的部门名称以及每个部门的人数
SELECT department,COUNT(*) FROM employee GROUP BY department;
查询每个部门的部门名称以及每个部门工资大于1500的人数
SELECT department,COUNT(salary) FROM employee WHERE salary > 1500 GROUP BY department;
group by + having
用来分组查询后指定一些条件来输出查询结果
having作用和where一样,但having只能用于group by
使用
查询工资总和大于9000的部门名称以及工资和
查询每个部分的工资总和
SELECT department,GROUP_CONCAT(salary) FROM employee GROUP BY department;
SELECT department,SUM(salary) FROM employee GROUP BY department;
总和大于9000
SELECT department,SUM(salary) FROM employee GROUP BY department HAVING SUM(salary)>9000;
having与where的区别
1.having是在分组后对数据进行过滤.
2.where是在分组前对数据进行过滤
3.having后面可以使用分组函数(统计函数)
4.where后面不可以使用分组函数
5.WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
查询工资大于2000的,工资总和大于6000的部门名称以及工资和
查询工资大于2000的
SELECT * FROM employee WHERE salary >2000;
各部门工资
SELECT department, GROUP_CONCAT(salary) FROM employee WHERE salary >2000 GROUP BY department;
各部门工资总和
SELECT department, SUM(salary) FROM employee WHERE salary >2000 GROUP BY department;
各部门工资总和大于6000
SELECT department, SUM(salary) FROM employee WHERE salary >2000
GROUP BY department HAVING SUM(salary)>6000;
各部门工资总和大于6000降序排列
SELECT department, SUM(salary) FROM employee
WHERE salary >2000
GROUP BY department
HAVING SUM(salary)>6000
ORDER BY SUM(salary) DESC;
书写顺序
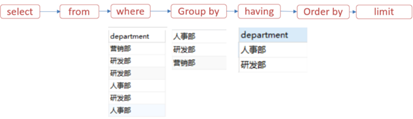
执行顺序

LIMIT
从哪一行开始查,总共要查几行
Limit 参数1,参数2
参数1:从哪一行开始查
参数2:一共要查几行
角标是从0开始
格式:select * from 表名 limit 0,3;
分页思路

老九学堂会员社群出品