在prometheus监控系统,prometheus的职责是采集,查询和存储和推送报警到alertmanager。本文主要介绍下prometheus的配置文件。
全局配置文件简介
默认配置文件
[root@node00 prometheus]# cat prometheus.yml.default # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
- global: 此片段指定的是prometheus的全局配置, 比如采集间隔,抓取超时时间等。
- rule_files: 此片段指定报警规则文件, prometheus根据这些规则信息,会推送报警信息到alertmanager中。
- scrape_configs: 此片段指定抓取配置,prometheus的数据采集通过此片段配置。
- alerting: 此片段指定报警配置, 这里主要是指定prometheus将报警规则推送到指定的alertmanager实例地址。
- remote_write: 指定后端的存储的写入api地址。
- remote_read: 指定后端的存储的读取api地址。
global片段主要参数
# How frequently to scrape targets by default. [ scrape_interval: <duration> | default = 1m ] # 抓取间隔 # How long until a scrape request times out. [ scrape_timeout: <duration> | default = 10s ] # 抓取超时时间 # How frequently to evaluate rules. [ evaluation_interval: <duration> | default = 1m ] # 评估规则间隔 # The labels to add to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: # 外部一些标签设置 [ <labelname>: <labelvalue> ... ]
scrapy_config片段主要参数
一个scrape_config 片段指定一组目标和参数, 目标就是实例,指定采集的端点, 参数描述如何采集这些实例, 主要参数如下
- scrape_interval: 抓取间隔,默认继承global值。
- scrape_timeout: 抓取超时时间,默认继承global值。
- metric_path: 抓取路径, 默认是/metrics
- scheme: 指定采集使用的协议,http或者https。
- params: 指定url参数。
- basic_auth: 指定认证信息。
- *_sd_configs: 指定服务发现配置
- static_configs: 静态指定服务job。
- relabel_config: relabel设置。
static_configs样例
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" static_configs: - targets: - "192.168.100.10:20001"
- "192.168.100.11:20001
- "192.168.100.12:20001"
file_sd_configs样例
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml" # 独立文件配置如下 cat conf/node-dis.conf - targets: - "192.168.100.10:20001" - "192.168.100.11:20001" - "192.168.100.12:20001" 或者可以这样配置 [root@node00 conf]# cat node-dis.yml - targets: - "192.168.100.10:20001" labels: hostname: node00 - targets: - "192.168.100.11:20001" labels: hostname: node01 - targets: - "192.168.100.12:20001" labels: hostname: node02
通过file_fd_files 配置后我们可以在不重启prometheus的前提下, 修改对应的采集文件(node_dis.yml), 在特定的时间内(refresh_interval),prometheus会完成配置信息的载入工作。
consul_sd_file样例
由于consul的配置需要有consul的服务提供, 这里简单部署下consul的服务。
# 进入下载目录
[root@node00 prometheus]# cd /usr/src/
# 下载 [root@node00 src]# wget https://releases.hashicorp.com/consul/1.6.1/consul_1.6.1_linux_amd64.zip
# 解压 [root@node00 src]# unzip consul_1.6.1_linux_amd64.zip Archive: consul_1.6.1_linux_amd64.zip inflating: consul
# 查看 [root@node00 src]# ls consul consul_1.6.1_linux_amd64.zip debug kernels node_exporter-0.18.1.linux-amd64.tar.gz prometheus-2.12.0.linux-amd64.tar.gz
# 查看文件类型 [root@node00 src]# file consul consul: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
# 防止到系统bin目录 [root@node00 src]# mv consul /usr/local/bin/
# 确保环境变量包含 [root@node00 src]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# 运行测试 [root@node00 consul.d]# consul agent -dev
# 测试获取成员
[root@node00 ~]# consul members # 创建配置目录 [root@node00 ~]#mkdir /etc/consul.d [root@node00 consul.d]# cat prometheus-node.json {
"addresses": {
"http": "0.0.0.0",
"https": "0.0.0.0"
},
"services": [{
"name": "prometheus-node",
"tags": ["prometheus","node"],
"port": 20001
}]
}
# 指定配置文件运行
consul agent -dev -config-dir=/etc/consul.d
打开web管理界面 192.169.100.10:8500,查看相应的服务信息。

上面我们可以看到有2个service , 其中prometheus-node是我们定义的service。
和prometheus集成样例:
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
consul_sd_configs:
- server: localhost:8500
services:
- prometheus-node
# tags:
# - prometheus
# - node
#- refresh_interval: 1m
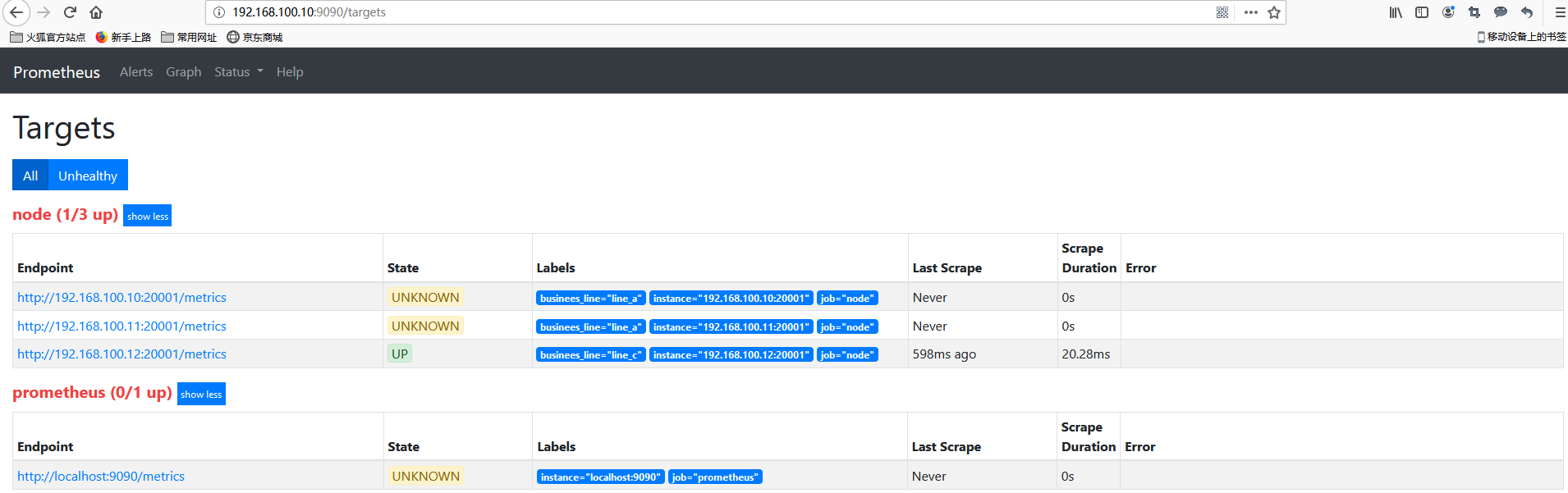
在prometheus的target界面上我们看到服务注册发现的结果。
我们通过api接口给该service添加一个节点, 看看是否可以同步过来。
[root@node00 ~]# curl -XPUT [email protected] 127.0.0.1:8500/v1/catalog/register
true
[root@node00 ~]# cat node01.json
{
"id":"0cc931ea-9a3a-a6ff-3ef5-e0c99371d77d",
"Node": "node01",
"Address": "192.168.100.11",
"Service":
{
"Port": 20001,
"ID": "prometheus-node",
"Service": "prometheus-node"
}
}
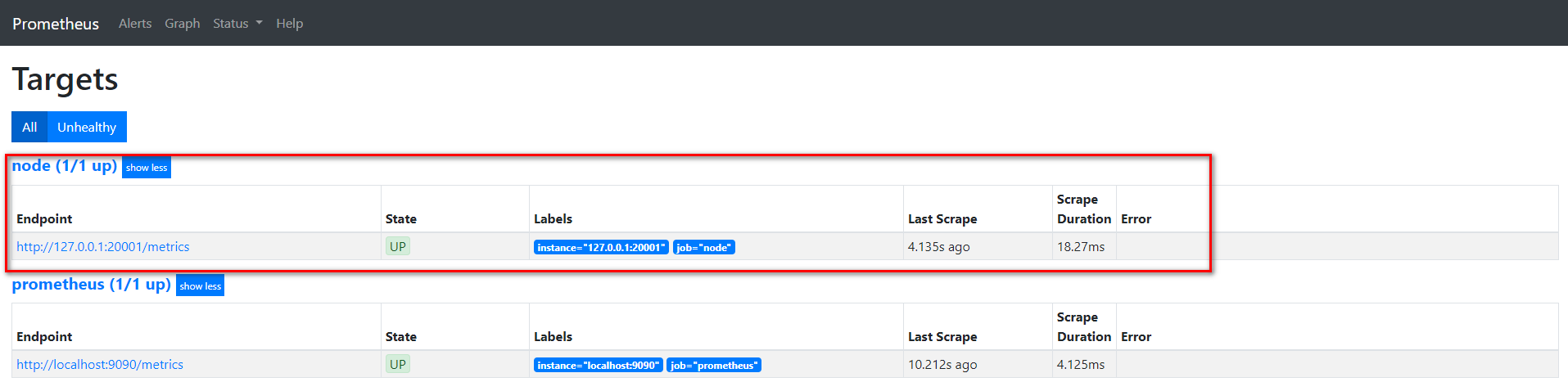
在consul和prometheus中查看


可以发现通过向consul中特定服务加入节点, 就可以在prometheus动态变动采集的实例地址。
relabel_config
重新标记是一个功能强大的工具,可以在目标的标签集被抓取之前重写它,每个采集配置可以配置多个重写标签设置,并按照配置的顺序来应用于每个目标的标签集。
目标重新标签之后,以__开头的标签将从标签集中删除的。
如果使用只需要临时的存储临时标签值的,可以使用_tmp作为前缀标识。
由于上面我们设置了consul,现在恢复到使用file方式,具体的配置文件如下。
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml"
[root@node00 prometheus]# cat conf/node-dis.yml
- targets:
- "192.168.100.10:20001"
labels:
__hostname__: node00
__businees_line__: "line_a"
__region_id__: "cn-beijing"
__availability_zone__: "a"
- targets:
- "192.168.100.11:20001"
labels:
__hostname__: node01
__businees_line__: "line_a"
__region_id__: "cn-beijing"
__availability_zone__: "a"
- targets:
- "192.168.100.12:20001"
labels:
__hostname__: node02
__businees_line__: "line_c"
__region_id__: "cn-beijing"
__availability_zone__: "b"
此时如果查看target信息,如下图
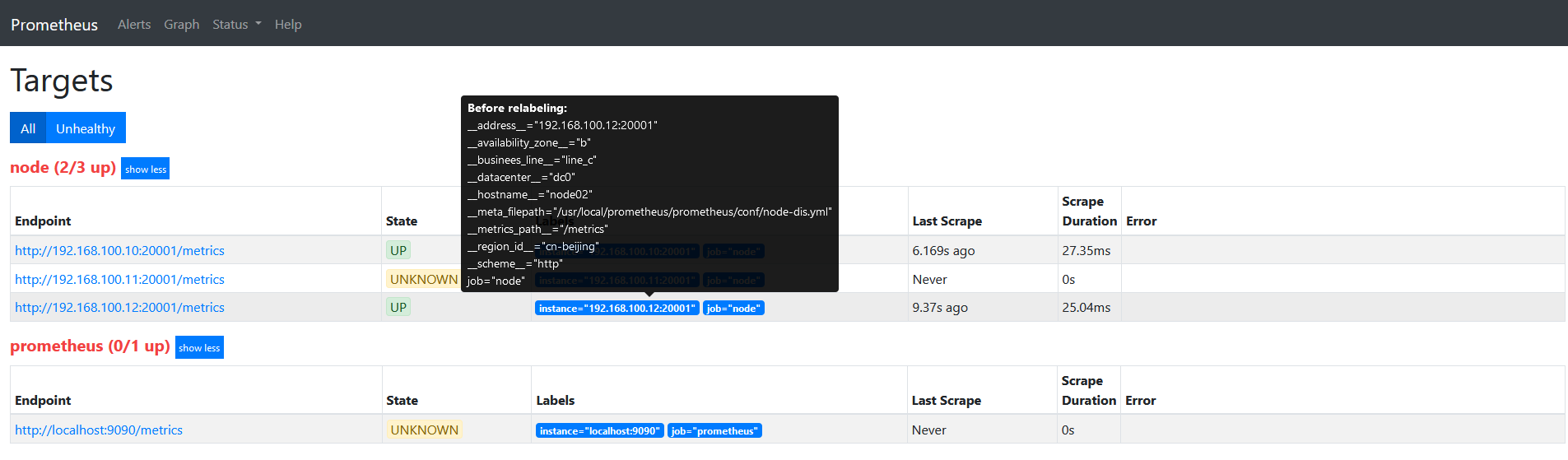
因为我们的label都是以__开头的,目标重新标签之后,以__开头的标签将从标签集中删除的。
一个简单的relabel设置
将labels中的__hostname__替换为node_name。
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml" relabel_configs: - source_labels: - "__hostname__" regex: "(.*)" target_label: "nodename" action: replace replacement: "$1"
重启服务查看target信息如下图:
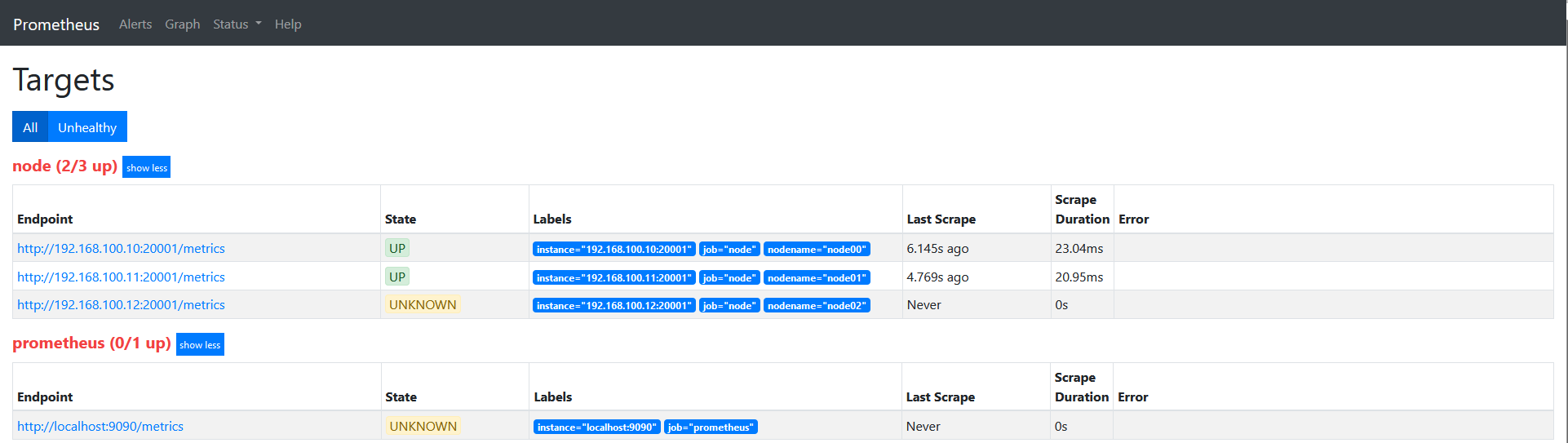
说下上面的配置: source_labels指定我们我们需要处理的源标签, target_labels指定了我们要replace后的标签名字, action指定relabel动作,这里使用replace替换动作。 regex去匹配源标签(__hostname__)的值,"(.*)"代表__hostname__这个标签是什么值都匹配的,然后replacement指定的替换后的标签(target_label)对应的数值。采用正则引用方式获取的。
这里修改下上面的正则表达式为 ‘’regex: "(node00)"'的时候可以看到如下图。
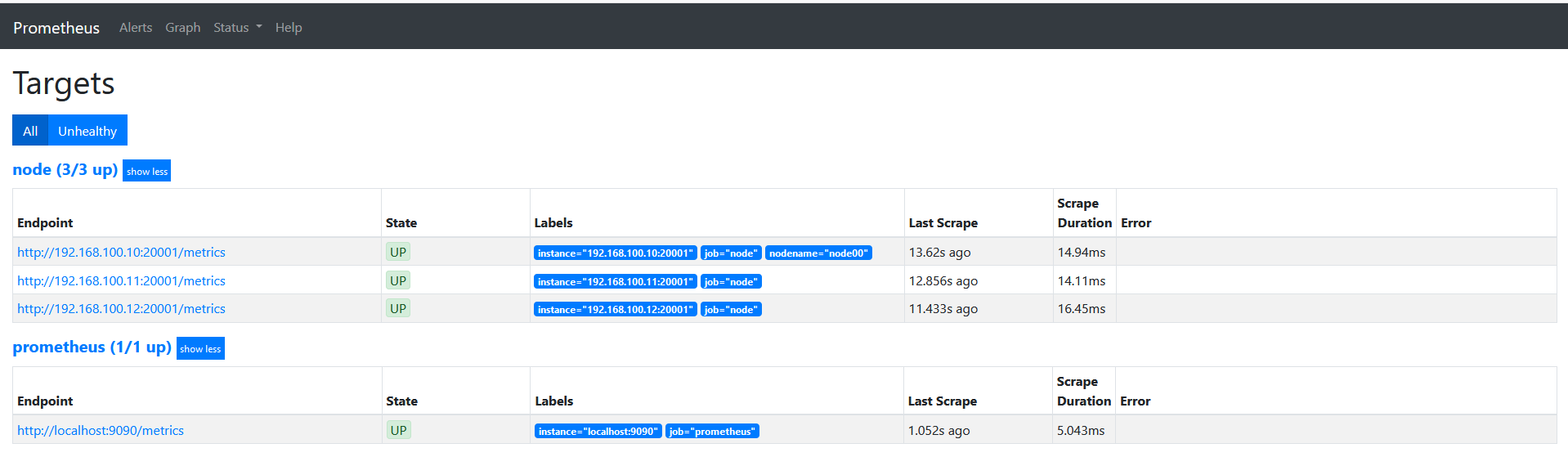
keep
修改配置文件
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml"
target如下图
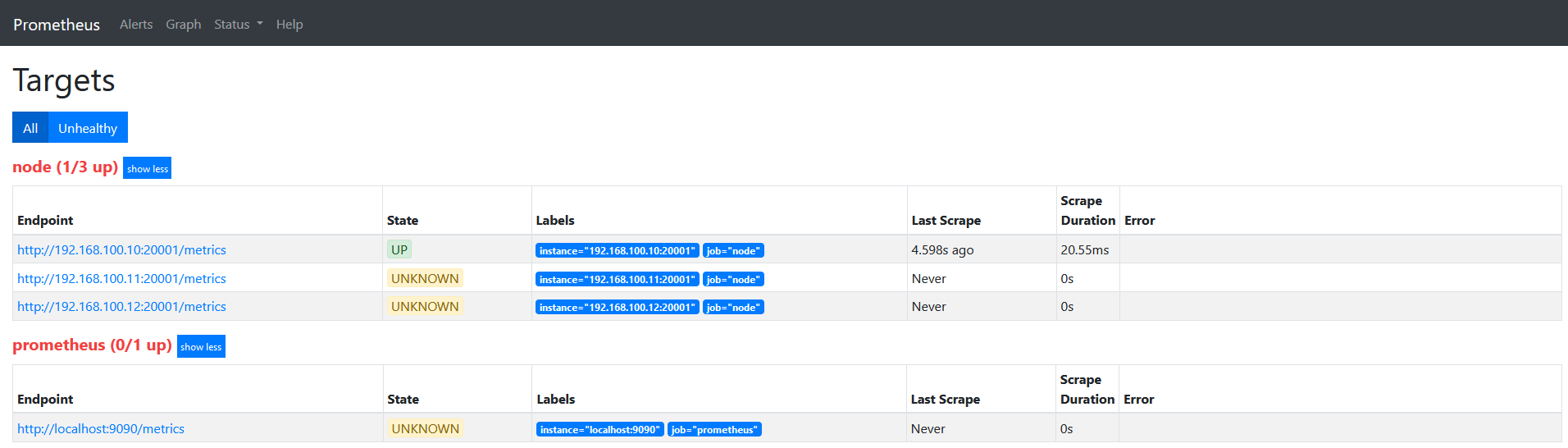
修改配置文件如下
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml" relabel_configs: - source_labels: - "__hostname__" regex: "node00" action: keep
target如下图
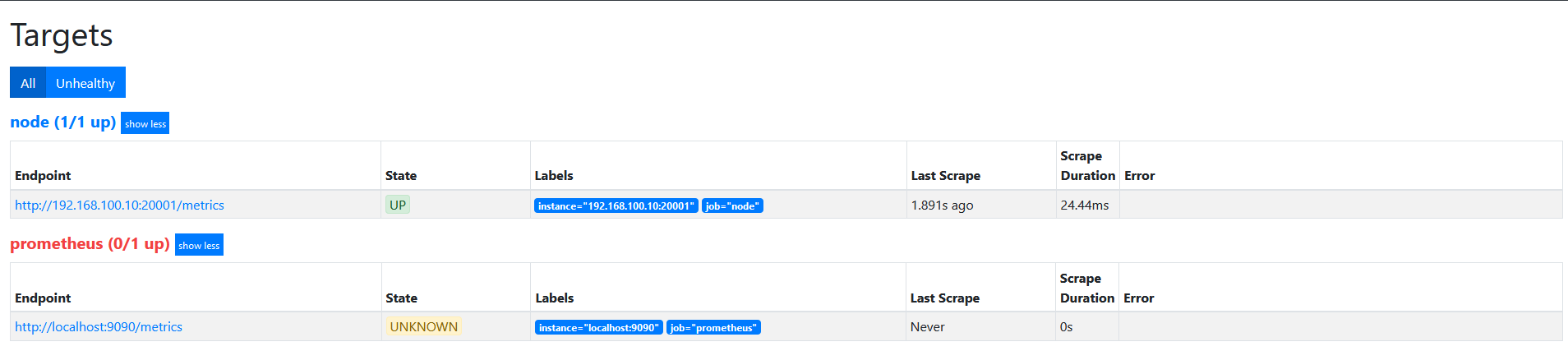
action为keep,只要source_labels的值匹配regex(node00)的实例才能会被采集。 其他的实例不会被采集。
drop
在上面的基础上,修改action为drop。
target如下图
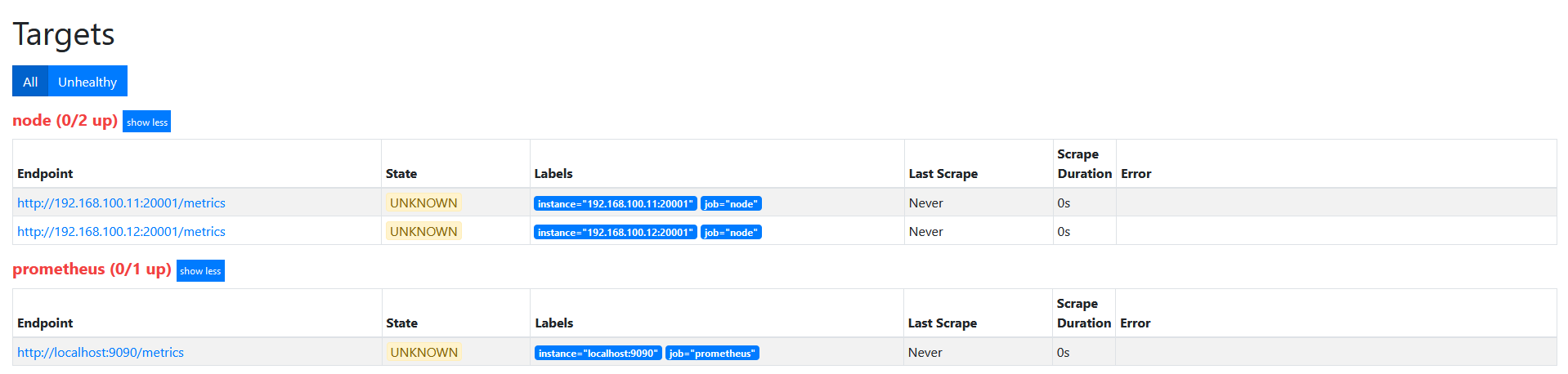
action为drop,其实和keep是相似的, 不过是相反的, 只要source_labels的值匹配regex(node00)的实例不会被采集。 其他的实例会被采集。
replace
我们的基础信息里面有__region_id__和__availability_zone__,但是我想融合2个字段在一起,可以通过replace来实现。
修改配置如下
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml" relabel_configs: - source_labels: - "__region_id__" - "__availability_zone__" separator: "-" regex: "(.*)" target_label: "region_zone" action: replace replacement: "$1"
target如下图:
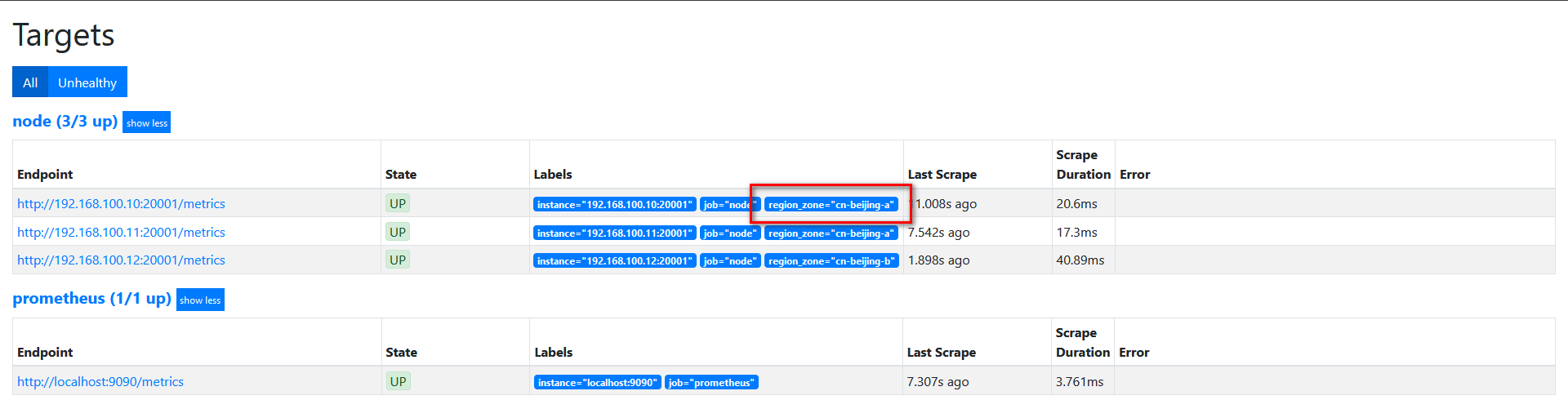
labelkeep
配置文件如下
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml" relabel_configs: - source_labels: - "__hostname__" regex: "(.*)" target_label: "nodename" action: replace replacement: "$1" - source_labels: - "__businees_line__" regex: "(.*)" target_label: "businees_line" action: replace replacement: "$1" - source_labels: - "__datacenter__" regex: "(.*)" target_label: "datacenter" action: replace replacement: "$1"
target如下图

修改配置文件如下
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: "node" file_sd_configs: - refresh_interval: 1m files: - "/usr/local/prometheus/prometheus/conf/node*.yml" relabel_configs: - source_labels: - "__hostname__" regex: "(.*)" target_label: "nodename" action: replace replacement: "$1" - source_labels: - "__businees_line__" regex: "(.*)" target_label: "businees_line" action: replace replacement: "$1" - source_labels: - "__datacenter__" regex: "(.*)" target_label: "datacenter" action: replace replacement: "$1" - regex: "(nodename|datacenter)" action: labeldrop
target如下图