在Java 8中,添加了函数式接口(functional interface),Lambda表达式和方法引用(method reference),使得创建函数对象(function object)变得更加容易。还有 Stream API为处理数据元素序列提供类库级别的支持。
第42条:Lambda匿名类
以前,用带有单个抽象方法的接口作为函数类型(function type),它们的实例称为函数对象(function object),表示函数或者要采取的动作。JDK1.1开始,创建函数对象的主要方式是通过匿名类(anonymous class)(第24条)。如下用一个匿名类创建了排序的比较函数:
// Anonymous class instance as a function object - obsolete! Collections.sort(words, new Comparator<String>() { public int compare(String s1, String s2) { return Integer.compare(s1.length(), s2.length()); } });
匿名类适用于需要函数对象的经典面向对象设计模式,特别是策略模式。比较器接口表示排序的抽象策略;上面的匿名类是排序字符串的具体策略。
在Java 8中,语言形式化了这样的概念,即使用单个抽象方法的接口是特别的,应该得到特别的对待。 这些接口现在称为函数式接口,并且该语言允许你使用lambda表达式或简称lambda来创建这些接口的实例。 Lambdas在功能上与匿名类相似,但更为简洁。 下面的代码使用lambdas替换上面的匿名类。 样板不见了,行为也十分明确:
// Lambda expression as function object (replaces anonymous class) Collections.sort(words, (s1, s2) -> Integer.compare(s1.length(), s2.length()));
Lambda的类型(Comparator<String>),其参数类型(s1和s2,两个都是String)及其返回值的类型(int),都没有出现在代码中。编译器使用称为类型推导(type inference)的过程从上下文中推导出这些类型。
关于类型推导应该增加一条警告。第26条告诉你不要使用原生态类型,第29条说过要支持泛型类型,第30条说过要支持泛型方法。因为编译器获得了大部分允许它从泛型进行类型推断的类型信息。
如果使用比较器构造方法代替lambda,则代码中的比较器可以变得更加简洁(第14,43条):
Collections.sort(words, comparingInt(String::length));
实际上,通过利用添加到Java 8中的List接口的sort方法,可以使片段变得更简短:
words.sort(comparingInt(String::length));
第34条目说,枚举实例属性比常量特定的类主体更可取。 Lambdas可以很容易地使用前者而不是后者来实现常量特定的行为。 仅仅将实现每个枚举常量行为的lambda传递给它的构造方法。 构造方法将lambda存储在实例属性中,apply方法将调用转发给lambda。 由此产生的代码比原始版本更简单,更清晰:
public enum Operation { PLUS ("+", (x, y) -> x + y), MINUS ("-", (x, y) -> x - y), TIMES ("*", (x, y) -> x * y), DIVIDE("/", (x, y) -> x / y); private final String symbol; private final DoubleBinaryOperator op; Operation(String symbol, DoubleBinaryOperator op) { this.symbol = symbol; this.op = op; } @Override public String toString() { return symbol; } public double apply(double x, double y) { return op.applyAsDouble(x, y); } }
lambda没有名称和文档; 如果计算不是自解释的,或者超过几行,则不要将其放入lambda表达式中。 一行代码对于lambda说是理想的,三行代码是合理的最大值。 如果违反这一规定,可能会严重损害程序的可读性。
Lambda仅限于函数式接口。 如果你想创建一个抽象类的实例,你可以使用匿名类来实现,但不能使用lambda。 同样,你可以使用匿名类来创建具有多个抽象方法的接口实例。
最后,lambda不能获得对自身的引用。 在lambda中,this关键字引用封闭实例,这通常是你想要的。 在匿名类中,this关键字引用匿名类实例。 如果你需要从其内部访问函数对象,则必须使用匿名类。
Lambda与匿名类共享你无法可靠地通过实现来序列化和反序列化的属性。因此,尽可能不要(除非迫不得已)序列化一个Lambda。
总之,Java8开始,Lambda成了表示小函数对象的最佳方式。千万不要给函数对象使用匿名类,除非必须创建非函数接口的类型的实例。
第43条:方法引用优先于Lambda
lambda优于匿名类的主要优点是它更简洁。Java提供了一种生成函数对象的方法,比lambda还要简洁,那就是:方法引用( method references)。
下面是一段程序代码片段,它维护一个从任意键到整数值的映射。如果将该值解释为键的实例个数,则该程序是一个多重集合的实现。该代码的功能是,根据键找到整数值,然后在此基础上加1:
map.merge(key, 1, (count, incr) -> count + incr);
此代码使用merge方法,该方法已添加到Java 8中的Map接口中。如果没有给定键的映射,则该方法只是插入给定值; 如果映射已经存在,则合并给定函数应用于当前值和给定值,并用结果覆盖当前值。
从Java 8开始,Integer类(和所有其他包装数字基本类型)提供了一个静态方法总和,和它完全相同。 我们可以简单地传递一个对这个方法的引用,并以较少的视觉混乱得到相同的结果:
map.merge(key, 1, Integer::sum);
方法的参数越多,你可以通过方法引用消除更多的样板。
下表总结了所有五种方法引用:

总之,方法引用常常比Lambda表达式更加简洁。只要方法引用更加简洁,清晰,就用方法引用。如果方法引用并不简洁,就坚持使用Lambda。
第44条:坚持使用标准的函数接口
java.util.Function包提供了大量标准的函数接口。只要标准的函数接口能够满足需求,应该优先考虑,而不是专门再构建一个新的函数接口。
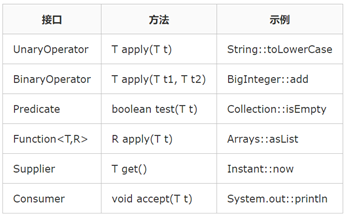
java.util.Function提供了43个接口,不用全记住,如果能记住其中6个基础接口,必要时可以推断出其余接口。基础接口作用于对象引用类型。
Operator接口代表其结果与参数类型一致的函数。
Predicate接口代表有一个参数并返回一个boolean的函数。
Function接口代表其参数与返回的类型不一致的函数。
Supplier接口代表没有参数并且返回(或“提供”)一个值的函数。
Consumer接口代表是带有一个函数但不返回任何值的函数,相当于消费掉了其参数。
这6个基础接口还有各种有3种变体,分别作用于基本类型int、long和double。它们的命名方式是在其基础接口名称前面加上基本类型。例如,带有int的predicate接口,其变体名称为IntPredicate。
Function接口有9种变体,用于结果类型为基本类型的情况。
源和结果类型总是不同,因为从类型到它自身的函数是UnaryOperator。 如果源类型和结果类型都是基本类型,则使用带有SrcToResult的前缀Function,例如LongToIntFunction(六个变体)。如果源是一个基本类型,返回结果是一个对象引用,那么带有<Src>ToObj的前缀Function,例如DoubleToObjFunction (三种变体)。
有三个包含两个参数版本的基本功能接口,使它们有意义:BiPredicate <T,U>,BiFunction <T,U,R>和BiConsumer <T,U>。 也有返回三种相关基本类型的BiFunction变体:ToIntBiFunction <T,U>,ToLongBiFunction <T,U>和ToDoubleBiFunction <T,U>。Consumer有两个变量,它们带有一个对象引用和一个基本类型:ObjDoubleConsumer <T>,ObjIntConsumer <T>和ObjLongConsumer <T>。 总共有九个两个参数版本的基本接口。
最后,还有一个BooleanSupplier接口,它是Supplier的一个变体,它返回布尔值。 这是任何标准函数式接口名称中唯一明确提及的布尔类型,但布尔返回值通过Predicate及其四种变体形式支持。 前面段落中介绍的BooleanSupplier接口和42个接口占所有四十三个标准功能接口。
大多数标准函数式接口仅用于提供对基本类型的支持。 不要试图使用基本的函数式接口来装箱基本类型的包装类而不是基本类型的函数式接口。
现在你知道你应该通常使用标准的函数式接口来优先编写自己的接口。 但是,你应该什么时候写自己的接口? 当然,如果没有一个标准模块能够满足您的需求,例如,如果需要一个带有三个参数的Predicate,或者一个抛出检查异常的Predicate,那么需要编写自己的代码。 但有时候你应该编写自己的函数式接口,即使与其中一个标准的函数式接口的结构相同。
@FunctionalInterface注解,在类型类似于@Override。 这是一个程序员意图的陈述,它有三个目的:它告诉读者该类和它的文档,该接口是为了实现lambda表达式而设计的;它使你保持可靠,因为除非只有一个抽象方法,否则接口不会编译; 它可以防止维护人员在接口发生变化时不小心地将抽象方法添加到接口中。
始终使用@FunctionalInterface注解标注你的函数式接口。
总之,现在Java已经有了lambda表达式,因此必须考虑lambda表达式来设计你的API。 在输入上接受函数式接口类型并在输出中返回它们。 一般来说,最好使用java.util.function.Function中提供的标准接口,但请注意,在相对罕见的情况下,最好编写自己的函数式接口。
第45条:谨慎使用Stream
Java8增加了Stream API,简化了串行或并行的大批量操作。这个API提供2个关键抽象:Stream(流)代表数据元素有限或者无限的顺序,Stream pipeline(流管道)代表这些元素的一个多级计算。
流中的数据元素可以是对象引用或基本类型。 支持三种基本类型:int,long和double。
流管道由源流(source stream)的零或多个中间操作和一个终结操作组成。每个中间操作都以某种方式转换流,例如将每个元素映射到该元素的函数或过滤掉所有不满足某些条件的元素。中间操作都将一个流转换为另一个流,其元素类型可能与输入流相同或不同。终结操作对流执行最后一次中间操作产生的最终计算,例如将其元素存储到集合中、返回某个元素或打印其所有元素。
管道延迟(lazily)计算求值:计算直到终结操作被调用后才开始,而为了完成终结操作而不需要的数据元素永远不会被计算出来。 这种延迟计算求值的方式使得可以使用无限流。
Stream API流式的(fluent)::它设计允许所有组成管道的调用被链接到一个表达式中。事实上,多个管道可以链接在一起形成一个表达式。
过度使用流使程序难于阅读和维护。
"Hello world!".chars().forEach(System.out::print);
你可能希望它打印Hello world!,但如果运行它,发现它打印721011081081113211911111410810033。这是因为“Hello world!”.chars()返回的流的元素不是char值,而是int值,因此调用了print的int重载。
"Hello world!".chars().forEach(x -> System.out.print((char) x));
理想情况下,应该避免使用流来处理char值。
流可以很容易地做一些事情:
•统一转换元素序列
•过滤元素序列
•使用单个操作组合元素序列(例如添加、连接或计算最小值)
•将元素序列累积到一个集合中,可能通过一些公共属性将它们分组
•在元素序列中搜索满足某些条件的元素
对于流来说,很难做到的一件事是同时访问管道的多个阶段中的相应元素:一旦将值映射到其他值,原始值就会丢失。
总之,有些任务最好使用流来完成,有些任务最好使用迭代来完成。将这两种方法结合起来,可以最好地完成许多任务。对于选择使用哪种方法进行任务,没有硬性规定,但是有一些有用的启发式方法。在许多情况下,使用哪种方法将是清楚的;在某些情况下,则不会很清楚。如果不确定一个任务是通过流还是迭代更好地完成,那么尝试这两种方法,看看哪一种效果更好。
第46 条:优先选择Stream中无副作用的函数
Stream不只是一个API,它是一种基于函数编程的模型。为了获得Stream带来的描述性和速度,有时还有并行性,必须采用泛型以及API。
Stream范型最重要的部分是把计算构成一系列变型,每一级结构都尽可能靠近上一级结果的纯函数(pure function)。纯函数是指其结果只取决于输入的函数:它不依赖任何可变的状态,也不更新任何状态。
// Uses the streams API but not the paradigm--Don't do this! Map<String, Long> freq = new HashMap<>(); try (Stream<String> words = new Scanner(file).tokens()) { words.forEach(word -> {freq.merge(word.toLowerCase(), 1L, Long::sum);}); }
这段代码根本不是流代码; 它是伪装成流代码的迭代代码。 它没有从流API中获益,并且它比相应的迭代代码更长,更难读,并且更难于维护。
这个代码在一个终结操作forEach中完成所有工作,使用一个改变外部状态(频率表)的lambda。
这段代码修改后:
// Proper use of streams to initialize a frequency table Map<String, Long> freq; try (Stream<String> words = new Scanner(file).tokens()) { freq = words.collect(groupingBy(String::toLowerCase, counting())); }
ForEach操作是终止操作中最没有威力的,也是对Stream最不友好的。它是显示迭代,并不适合并行。
forEach操作应该只用于报告Stream计算的结果,而不是执行计算。
有时候也可以将forEach用于其他目的,比如将Stream计算的结果添加到之前已经存在的集合中去。
改进后的代码使用了收集器(collector),这是使用流必须学习的新概念。Collectors的API令人生畏:它有39个方法,其中一些方法有多达5个类型参数。好消息是,你可以从这个API中获得大部分好处,而不必深入研究它的全部复杂性。对于初学者来说,可以忽略收集器接口,将收集器看作是封装缩减策略( reduction strategy)的不透明对象。在此上下文中,reduction意味着将流的元素组合为单个对象。 收集器生成的对象通常是一个集合(它代表名称收集器)。
将流的元素收集到真正的集合中的收集器非常简单。有三个这样的收集器:toList()、toSet()和toCollection(collectionFactory)。它们分别返回集合、列表和程序员指定的集合类型。有了这些知识,我们就可以编写一个流管道从我们的频率表中提取出现频率前10个单词的列表。
// Pipeline to get a top-ten list of words from a frequency table List<String> topTen = freq.keySet().stream().sorted(comparing(freq::get).reversed()).limit(10).collect(toList());
注意,这里没有给toList方法配上它的Collectors类。静态导入Collectors的所有成员是惯例也是明智的,因为这样可以提升Stream pipeline的可读性。
这段代码中有一个技巧的部分是传给sorted的比较器comapring(freq::get).reversed().
comparing方法是一个比较器构造方法(第14条),它带有一个键提取函数,读取一个单词,提取实际是表查询,有限制的方法引用freq::get在频率表中查找单词,并返回该单词在文件中出现的次数。最后,在比较器上调用reversed,按照频率高低对单词进行排序。
toMap更复杂的形式,以及groupingBy方法,提供了处理此类冲突(collisions)的各种方法。一种方法是向toMap方法提供除键和值映射器(mappers)之外的merge方法。merge方法是一个BinaryOperator,其中V是map的值类型。与键关联的任何附加值都使用merge方法与现有值相结合。
// Using a toMap collector to make a map from string to enum private static final Map<String, Operation> stringToEnum = Stream.of(values()).collect(toMap(Object::toString, e -> e));
有带3个参数的toMap形式。假设有一个Stream,代表不同歌唱家的唱片,我们想得到一个从歌唱家到最畅销唱片之间的映射。
// Collector to generate a map from key to chosen element for key Map<Artist, Album> topHits = albums.collect(toMap(Album::artist, a->a, maxBy(comparing(Album::sales))));
比较器使用静态工厂方法maxBy,它是从BinaryOperator静态导入的。 此方法将Comparator <T>转换为BinaryOperator <T>,用于计算指定比较器隐含的最大值。 在这种情况下,比较器由比较器构造方法comparing返回,它采用key提取器函数Album :: sales。它说,“将专辑(albums)流转换为地map,将每位艺术家(artist)映射到销售量最佳的专辑。”
带有三个参数的toMap形式还有另一个用途,即生成一个收集器,当有冲突时强制“保留最后更新”(last-write-wins)。
// Collector to impose last-write-wins policy toMap(keyMapper, valueMapper, (oldVal, newVal) ->newVal)
除了toMap方法之外,Collectors API还提供了groupingBy方法:它返回收集器以生成映射,根据分类函数将元素分门别类。
这是我们在第45条中的Anagram程序中使用的收集器,用于生成从按字母顺序排列的单词到单词列表的map:
words.collect(groupingBy(word->alphabetize(word)))
最后一个Collectors方法是joining,它只是CharSequence实例的Stream中操作,例如字符串。它以参数的形式返回一个简单地合并元素的收集器。
总之,编写Stream pipeline的本质是无副作用的函数对象。这适用于传入Stream以及相关对象的所有函数对象。终止操作中的forEach应该只用来报告由Stream执行的计算结果,而不是让它执行计算。为了正确地使用Stream,必须了解收集器。最重要的收集器工厂是toList, toSet, toMap, groupingBy和joining。
第47条:Stream要优先用Collection作为返回类型
许多方法返回元素序列(sequence)。在Java 8之前,通常方法的返回类型是Collection,Set和List这些接口;还包括Iterable和数组类型。如果返回的元素是基本类型或有严格的性能要求,则使用数组。在Java 8中,将流(Stream)添加到平台中,这使得为序列返回方法选择适当的返回类型的任务变得非常复杂。
或许你曾听说过,现在Stream是返回元素序列最明智的选择了,但如第45条所述,Stream并没有淘汰迭代:要编写出优秀的代码必须巧妙地将Stream与迭代结合起来使用。如果一个API只返回一个流,并且一些用户想用for-each循环遍历返回的序列,那么这些用户肯定会感到不安。
因为Stream接口在Iterable接口中包含唯一的抽象方法,Stream的方法规范与Iterable兼容。阻止程序员使用for-each循环在流上迭代的唯一原因是Stream无法继承Iterable。
注意,条目 34中的Anagrams程序的流版本使用Files.lines方法读取字典,而迭代版本使用了scanner。Files.lines方法优于scanner,scanner在读取文件时无声地吞噬所有异常。理想情况下,我们也会在迭代版本中使用Files.lines。如果API只提供对序列的流访问,而程序员希望使用for-each语句遍历序列,那么他们就要做出这种妥协。
相反,如果一个程序员想要使用流管道来处理一个序列,那么一个只提供Iterable的API会让他感到不安。JDK同样没有提供适配器,但是编写这个适配器非常简单:
// Adapter from Iterable<E> to Stream<E> public static <E> Stream<E> streamOf(Iterable<E> iterable) { return StreamSupport.stream(iterable.spliterator(), false); }
Collection接口是Iterable的子类型,并且具有stream方法,因此它提供迭代和流访问。 因此,Collection或适当的子类型通常是公共序列返回方法的最佳返回类型。 数组还使用Arrays.asList和Stream.of方法提供简单的迭代和流访问。 如果返回的序列小到足以容易地放入内存中,那么最好返回一个标准集合实现,例如ArrayList或HashSet。 但是不要在内存中存储大的序列,只是为了将它作为集合返回。如果返回的序列很大但可以简洁地表示,请考虑实现一个专用集合。
总之,在编写返回元素序列的方法时,请记住,某些用户可能希望将它们作为流处理,而其他用户可能希望迭代方式来处理它们。 尽量适应两个群体。 如果返回集合是可行的,请执行此操作。 如果已经拥有集合中的元素,或者序列中的元素数量足够小,可以创建一个新的元素,那么返回一个标准集合,比如ArrayList。 否则,请考虑实现自定义集合,就像我们为幂集程序里所做的那样。
第48条:谨慎使用Stream并行
在主流语言中,Java一直处于提供简化并发编程任务的工具的最前沿。 当Java于1996年发布时,它内置了对线程的支持,包括同步和wait / notify机制。 Java 5引入了java.util.concurrent类库,带有并发集合和执行器框架。 Java 7引入了fork-join包,这是一个用于并行分解的高性能框架。 Java 8引入了流,可以通过对parallel方法的单个调用来并行化。第45条的程序:
// Stream-based program to generate the first 20 Mersenne primes public static void main(String[] args) { primes().map(p -> TWO.pow(p.intValueExact()).subtract(ONE)) .filter(mersenne -> mersenne.isProbablePrime(50)) .limit(20) .forEach(System.out::println); } static Stream<BigInteger> primes() { return Stream.iterate(TWO, BigInteger::nextProbablePrime); }
Stream类库不知道如何并行这个pipeline,以及如何探索失败,即便在最近环境下,如果源头是来自Stream.iterate,或者使用了中间操作的limit,那么并行pipeline也不可能提升性能。
千万不用任意地并行Stream pipeline。它造成的性能后果有可能是灾难性的。
在Steam上通过并行获得的性能,最好是通过ArrayList, HashMap, HashSet和ConcurrentHashMap实例,数组,int范围和long范围等。这些数据结构的共同之处在于,它们都可以精确而廉价地分割成任意大小的子程序,这使得在并行线程之间划分工作变得很容易。
并行Stream不仅可能降低性能,包括活性失败,还可能导致结果出错,以及难以预计的行为(如安全失败)。使用映射器(mappers),过滤器(filters)和其他程序员提供的不符合其规范的功能对象的管道并行化可能会导致安全故障。例如,传到Stream的reduce操作的收集器函数和组合函数,必须是有关联、互不干扰、并且是无状态的。
切记:并行Stream是一项严格的性能优化。对于任何优化都必须在改变前后对性能进行测试,以确保值得这么做。一般来说,程序中所有并行Stream pipeline都是在一个通用的fork-join池中运行的。只要有一个pipeline运行异常,都会损害到系统中其他不相关部分的性能。
在适当条件下,给Stream pipeline添加parallel调用,确实可以在多核处理器下实现近乎线性的倍增。某些领域例如机器学习和数据处理。
作为并行性有效的流管道的简单示例,请考虑此函数来计算π(n),素数小于或等于n:
// Prime-counting stream pipeline - benefits from parallelization static long pi(long n) { return LongStream.rangeClosed(2, n) .mapToObj(BigInteger::valueOf) .filter(i -> i.isProbablePrime(50)) .count(); }
使用此功能计算π(108)需要31秒。 只需添加parallel()方法调用即可将时间缩短为9.2秒。
// Prime-counting stream pipeline - parallel version static long pi(long n) { return LongStream.rangeClosed(2, n) .parallel() .mapToObj(BigInteger::valueOf) .filter(i -> i.isProbablePrime(50)) .count(); }
总之,尽量不用并行Stream pipeline,除非有足够的理由相信它能保证计算的正确性,并且能够加快程序的运行速度。