引言
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大、综合成本低、支持非结构化数据、查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式。
因此数据湖相关服务成为了云计算的发展重点之一。Azure平台早年就曾发布第一代Data Lake Storage,随后微软将它与Azure Storage进行了大力整合,于今年初正式对外发布了其第二代产品:Azure Data Lake Storage Gen2 (下称ADLS Gen2)。ADLS Gen2的口号是“不妥协的数据湖平台,它结合了丰富的高级数据湖解决方案功能集以及 Azure Blob 存储的经济性、全球规模和企业级安全性”。
全新一代的ADLS Gen2实际体验如何?在架构及特性上是否堪任大型数据湖应用的主存储呢?在上篇文章中,我们已对ADLS Gen2的基本操作和权限体系有了初步的了解。接下来让我们继续深入探究,尤其是关注ADLS Gen2作为存储层挂载到大数据集群后的表现。
ADLS Gen2体验:集群挂载
数据湖存储主要适用于大数据处理的场景,所以我们选择建立一个HDInsight大数据集群来进行实验,使用Spark来访问和操作数据湖中的数据。可以看到HDInsight已经支持ADLS Gen2了:
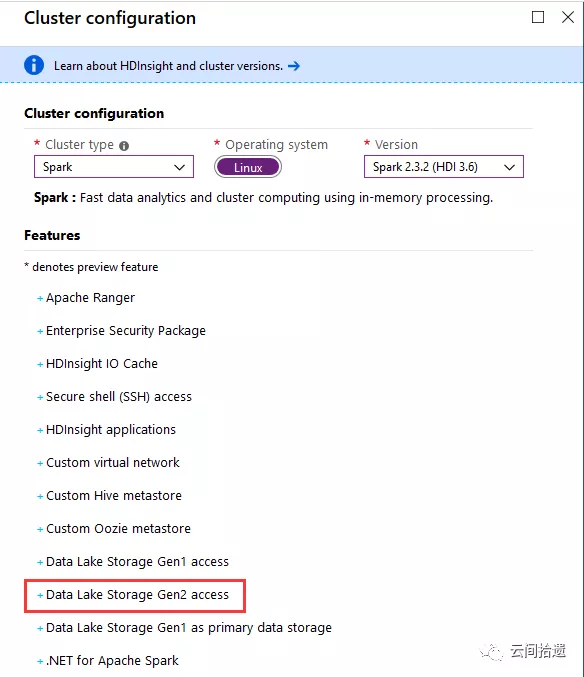
接下来是比较关键的存储配置环节,我们指定使用一个新建的ADLS Gen2实例hdiclusterroot来作为整个集群的存储,文件系统名为hdfs-root,如图所示:
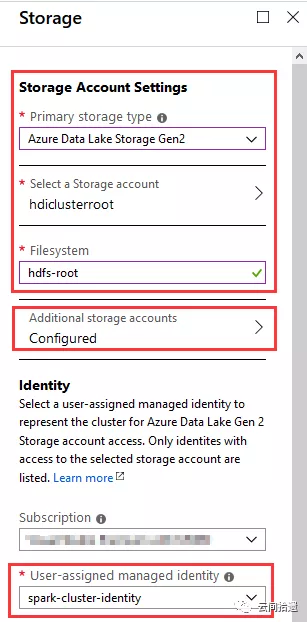
(图中我们还配置了Additional storage accounts,用于挂载传统Blob,之后作性能对比时会用到。此处暂不展开。)
很有意思的是上图的下半部分,它允许我们指定一个Identity,这个Identity可以代表Spark集群的身份和访问权限。这非常关键,意味着集群的身份能够完美地与ADLS Gen2的权限体系对应起来,在企业级的场景中能够很好地落地对于大数据资源访问的管控。
这里选择了专门建立的一个spark-cluster-identity作为集群的身份。我们事先为它赋予了hdiclusterroot这个存储账号的storage blob data owner权限,以便该identity能够对数据湖中的数据进行任意操作:
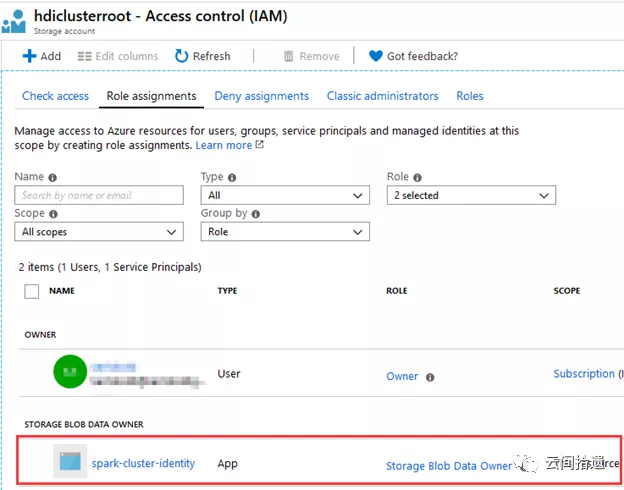
完成其他配置后按下创建按钮,Azure会一键生成Spark集群,大约十来分钟后整个集群就进入可用状态了:

我们迫不及待地SSH登录进集群,查看其默认挂载的文件系统。尝试使用hadoop fs -ls列出根目录下的文件信息:
sshuser@hn0-cloudp:~$ hadoop fs -ls / Found 18 items drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:10 /HdiNotebooks drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:29 /HdiSamples drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /ams drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /amshbase drwxrwx-wt - sshuser sshuser 0 2019-08-26 02:54 /app-logs drwxr-x--- - sshuser sshuser 0 2019-09-06 07:41 /apps drwxr-x--x - sshuser sshuser 0 2019-08-26 02:54 /atshistory drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:25 /custom-scriptaction-logs drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:19 /example drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /hbase drwxr-x--x - sshuser sshuser 0 2019-09-06 07:41 /hdp drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /hive drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /mapred drwxrwx-wt - sshuser sshuser 0 2019-08-26 03:19 /mapreducestaging drwxrwx-wt - sshuser sshuser 0 2019-08-26 02:54 /mr-history drwxrwx-wt - sshuser sshuser 0 2019-08-26 03:19 /tezstaging drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /tmp drwxrwx-wt - sshuser sshuser 0 2019-09-09 02:31 /user
将文件列表和ADLS Gen2比对,可以看到这里的“根目录”事实上就完全对应着hdiclusterroot这个数据湖实例下hdfs-root文件系统中的数据,这说明集群实现了该数据湖文件系统的挂载:
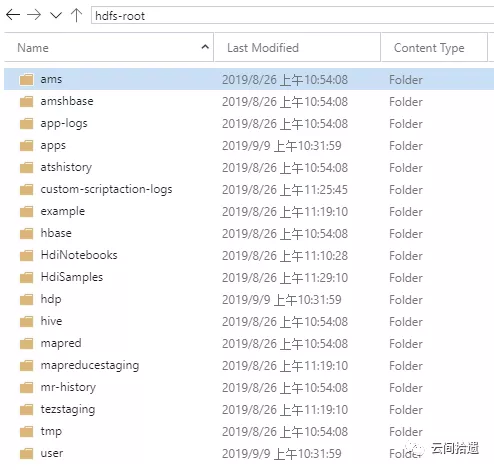
那么,这样的远程挂载是如何实现的呢?打开集群的core-site.xml 配置文件,答案在fs.defaultFS配置节中:
<property>
<name>fs.defaultFS</name>
<value>abfs://[email protected]</value>
<final>true</final>
</property>
原来,与通常使用hdfs不同,集群的fs.defaultFS在创建时就被设置为了以abfs为开头的特定url,该url正是指向我们的数据湖存储。这个ABFS驱动(Azure Blob File System)是微软专门为Data Lake Storage Gen2开发,全面实现了Hadoop的FileSystem接口,为Hadoop体系和ADLS Gen2架起了沟通桥梁。
为证明数据湖文件系统能够正常工作,我们来运行一个经典的WordCount程序。笔者使用AzCopy往数据湖中上传了一本小说《双城记》 (ATaleOfTwoCities.txt),然后到HDInsight集群自带的Jupyter Notebook里通过Scala脚本运用Spark来进行词频统计:

Great! 我们的Spark on ADLS Gen2实验完美运行,过程如丝般顺滑。
小结
Azure Data Lake Storage Gen2是微软Azure全新一代的大数据存储产品,专为企业级数据湖类应用所构建。它继承了Azure Blob Storage易于使用、成本低廉的特点,同时又加入了目录层次结构、细粒度权限控制等企业级特性。
作为ADLS Gen2系列的第二篇,本文主要实践了大数据集群挂载ADLS Gen2作为主存储的场景,在证明ADLS Gen2具备良好Hadoop生态兼容性的同时,也体验了与传统HDFS不同的存储计算分离架构。该种架构由于可独立扩展计算和存储部分,非常适合云端特点,正受到越来越多的欢迎。后续我们还将探索ADLS Gen2的更多特性,敬请关注。
关联阅读:
构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(上)
“云间拾遗”专注于从用户视角介绍云计算产品与技术,坚持以实操体验为核心输出内容,同时结合产品逻辑对应用场景进行深度解读。欢迎扫描下方二维码关注“云间拾遗”微信公众号,或订阅本博客。
