1.准确度的陷阱和混淆矩阵
我们之前对于分类问题,一直使用分类的准确度评价分类的结果,但是实际上分类问题的评价比回归问题的评价要复杂很多,相应的指标也多很多。可是之前使用准确度来进行评价不是挺好吗?但其实准确度是有一个很大的问题的,举个例子
我有一个癌症检测系统,通过对人进行体检,那么可以判断这个人是否患有癌症,而这个系统预测的准确度是99%,那么这个系统是好,还是坏呢?按照我们之前的逻辑,准确度都达到99%了,那么肯定是一个好系统了,其实不然。如果这个癌症的发病率只有百分之1呢,换句话说,1000个人里面只有10个癌症患者,健康的人远远高于患有癌症的人。那么不管什么人,系统只要都预测成健康,或者没有患有癌症,那么这个系统的准确度依然能达到99%,也就是说这个系统甚至都不需要机器学习,不管来什么人,只要都预测成健康就可以了,因为健康的人相对于患有癌症的人,比例显然是远远高于的。因此只要都预测成健康,那么准确度依旧会很高,但是这样的系统有用吗?我们的目的是,希望能够检测出来患有癌症的人,尽管这个系统的准确度达到了99%,但是癌症患者是不是一个都没有检测出来啊,所以这便是分类准确度的一个陷阱,或者说一个弊端,那么我们便有了其他的评价指标。所以我们说分类问题的评价指标相较于回归问题,要更复杂一些,毕竟回归问题只要判断误差的大小、或者r2的大小即可
或者我们的例子再举的极端一点,这个癌症的发病率只有百分之0.1,其实癌症的发病率在百分之0.1算是正常的了,百分之1个人觉得有点高了,但是不管了。如果癌症的发病率只有百分之0.1,那么只要系统都预测成健康,那么准确就达到了99.9%,但是这样的系统基本上没有什么价值,因为我们关注的是比较少的那一部分样本,但是这一部分样本,并没有预测出来。
我们之前对于分类问题,一直使用分类的准确度评价分类的结果,但是实际上分类问题的评价比回归问题的评价要复杂很多,相应的指标也多很多。可是之前使用准确度来进行评价不是挺好吗?但其实准确度是有一个很大的问题的,举个例子
这便是数据的极度偏斜(skewed data),对于极度偏斜的数据,只使用分类的准确度是远远不够的。因此我们要引入其他的指标,来判断分类的好坏。
在这里我们先引入一下混淆矩阵。
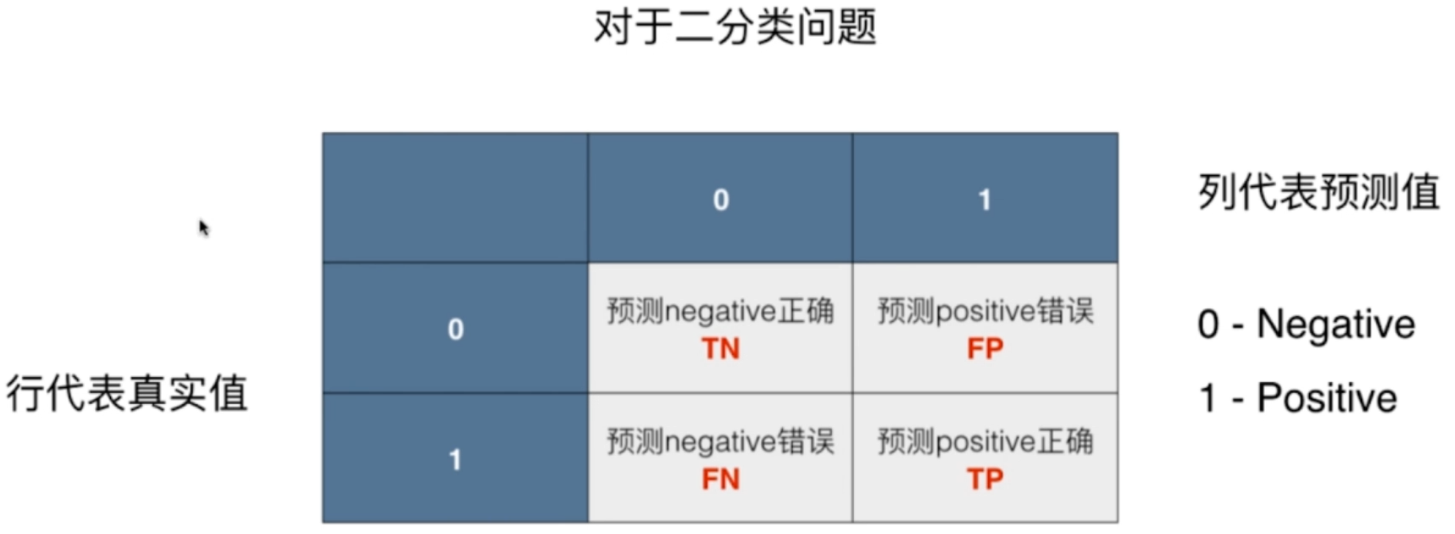
我们这里的0表示阴性,1表示阳性。在医院里面检测,如果是阴性说明是正常的,但如果是阳性,说明得病了。我们的行代表的是真实值,列代表的是预测值。
按照行列的顺序
如果是[0,0],说明预测negative正确,简称为TN,T表示True,我们预测正确了,预测的结果是negative,说明真实值是negative;如果是[0,1],那么是FP,F表示False,表示我们预测错了,预测的结果是positive,说明真实值是negative;如果是[1,0],那么是FN,表示我们预测错了,预测结果是negative,说明真实值是positive;[1,1]的话,那么是TP,表示我们预测对了,预测成了positive,说明真实值也是positive
假设有10000个人,我们的预测结果是这样的。0是阴性,表示健康;1是阳性,表示患病。那我们来描述一下TN,FP,FN,TP。
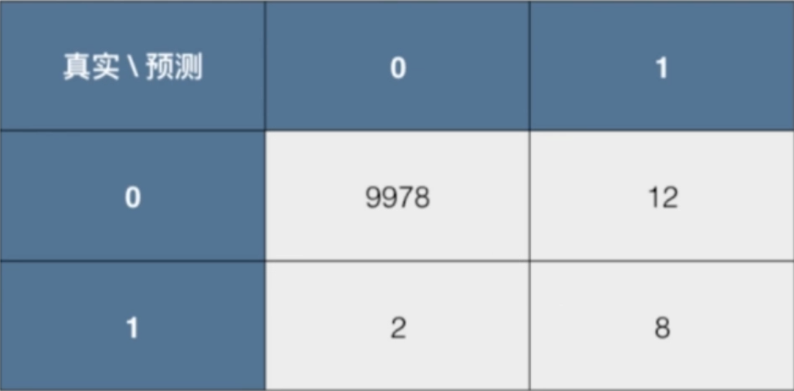
9978表示我们表示TN,表示有9978个人,我们预测对了,预测成了健康,说明原本就是健康的;12表示FP,表示我们预测错了,预测成了患病,意味着原本是没病的;2表示FN,表示我们预测错了,预测成了健康,意味着这两个人本来是患病的;8表示TP,表示我们预测对了,预测成了患病,说明原本就是患病的。
这便是混淆矩阵
2.精准率和召回率
我们介绍了混淆矩阵,混淆矩阵在分类任务中是一个非常重要的工具。我们通过混淆矩阵,可以得到更加好的来衡量分类算法的指标。我们下面介绍两个通过混淆矩阵得到的两个指标。
精准率:TP / (TP + FP)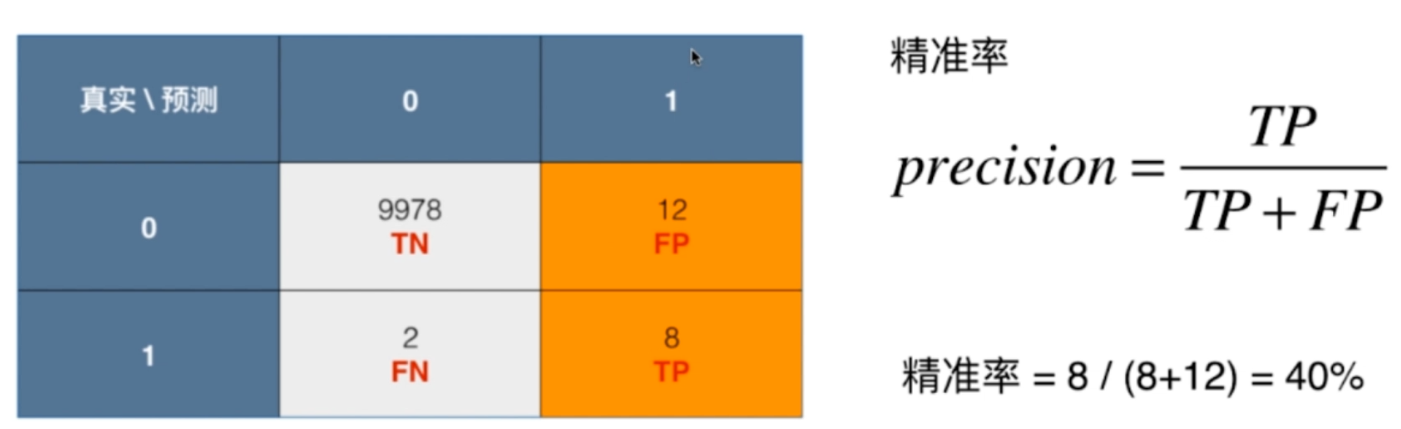
为什么把这个叫做精准率呢?因为在这种有极度偏斜的样本中,我们关注的是那些比较少的样本?比如癌症患者,那么1代表的就是患有癌症的人;再比如说银行发放信用卡给客户是否有风险,1代表的就是有风险。我们关注是那些样本比较少的,通常把这些样本分类为1。还拿这里的癌症患者举例,精准率就是我们预测为1、并且预测对了的个数除以我们预测为1的个数的值,比如这里的8,表示我们预测对了8个,我们预测为1,并且真实值也为1,这里的12,是我们预测为1但是真实值却不是1。所以8 / (12 + 8),预测为1并且预测对了的个数(8个),除以预测为1的个数(8 + 12个),等于40%,所以精准率就是百分之40.
召回率:TP / (TP + FN)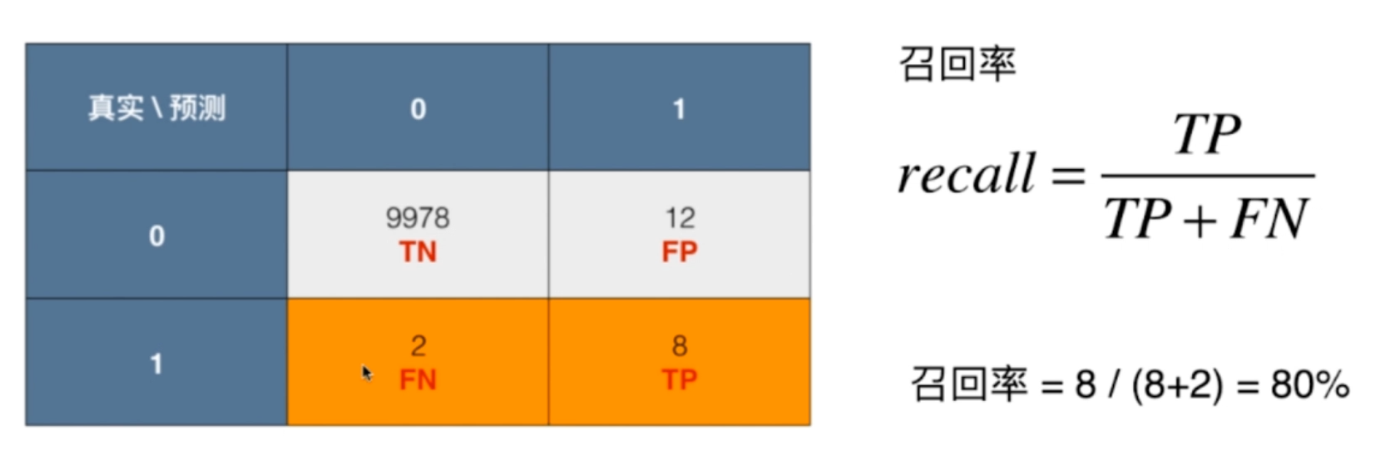
有了精准率,那么召回率也很好理解。毕竟两者只有分母不一样,精准率是TP / (TP + FP),而召回率是TP / (TP + FN)。TP为8,表示有8个真实值是1,我们也预测为1,FN为2,表示有两个明明也是1,但是我们却预测成了0。
所以:
精准率:真实值为异常、预测值也为异常 / (真实值为异常、预测值也为异常 + 真实值为正常、预测值却为异常。)
召回率:真实值为异常、预测值也为异常 / (真实值为异常、预测值也为异常 + 真实值为异常、预测值却为正常。)
所以想象成抓犯人
如果精准率小于1,说明我们错抓了,明明有不是犯人的,我们却当成了犯人
如果召回率小于1,说明我们漏网了,明明有是犯人的,我们却没有当成犯人再拿我们之前的癌症患者预测这个例子,假设有10000个人,10个癌症患者,但是我们预测的结果都是健康,那么首先准确度肯定是99.9%,但是它的精准率和召回率又是多少呢?
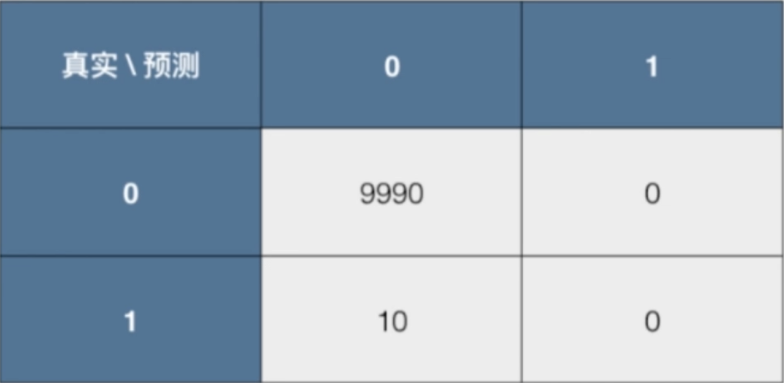
9990表示都是健康的,而我们也预测成了健康。但是10表示明明是癌症,我们还是预测成了健康。那么显然召回率是 0 / (10 + 0)=0,而精准率是0 / (0 + 0),尽管结果是0除以0,无意义,但是在统计这一层面上,这里显然还是0。所以尽管分类准确度达到了99.9%,但是它的精准率和召回率都是0。所以这样的系统尽管准确度达到了99.9%,但其实是没有意义的,对我们没有任何的帮助。在这种样本极度偏斜的情况下,我们不看分类准确度,而是看精准率和召回率,能更好的评价我们这个分类系统的好坏。
3.实现混淆矩阵、精准率和召回率
import numpy as np
from sklearn.datasets import load_digits
digits = load_digits()
X = digits.data
y = digits.target.copy()
# 我们需要那种极度偏斜的样本
# 于是我们将手写数字样本的10个特征,变成两个特征。
# 将特征为9的全部变成1,不为9的全部变成0
# 那么我们的关注点就是,对于原来特征为9的样本,能预测出来多少个
y[digits.target == 9] = 1
y[digits.target != 9] = 0
# 先使用逻辑回归进行训练
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
logistic = LogisticRegression()
logistic.fit(X_train, y_train)
logistic.score(X_test, y_test) # 0.9755555555555555可以看到我们使用逻辑回归预测的准确率达到了0.97555,但由于我们的数据是极度偏斜的,因此如果我把所有的样本都预测为0,我们的准确率也能达到百分之90左右,因此我们需要再考察一下其他的性能指标
y_predict = logistic.predict(X_test)
# 计算精准率和召回率
def confusion_matrix(y_true, y_predict):
# TN:正确预测为正值,说明y_predict和y_test都为0
TN = np.sum((y_predict == 0) & (y_test == 0))
# FP:错误预测为负值,说明y_predict为1,y_test为0
FP = np.sum((y_predict == 1) & (y_test == 0))
# FN:错误预测为正值,说明y_predict为0,y_test为1
FN = np.sum((y_predict == 0) & (y_test == 1))
# TP:正确预测为负值,说明y_predict为1,y_test为1
TP = np.sum((y_predict == 1) & (y_test == 1))
return np.array([
[TN, FP],
[FN, TP]
])
print(confusion_matrix(y_test, y_predict))
"""
[[403 2]
[ 9 36]]
"""
# 计算精准率和召回率
conf_mat = confusion_matrix(y_test, y_predict)
precision_score = conf_mat[1, 1] / np.sum(conf_mat[:, 1]) # TP / (TP + FP)
recall_score = conf_mat[1, 1] / np.sum(conf_mat[1, :]) # TP / (TP + FN)
print(precision_score) # 0.9473684210526315
print(recall_score) # 0.8因此我们便实现了混淆矩阵,以及计算除了精准率和召回率。那么接下来还是老规矩,我们看看sklearn中是如何实现混淆矩阵、精准率以及召回率的。
from sklearn.metrics import confusion_matrix, precision_score, recall_score
print(confusion_matrix(y_test, y_predict))
"""
[[403 2]
[ 9 36]]
"""
print(precision_score(y_test, y_predict)) # 0.9473684210526315
print(recall_score(y_test, y_predict)) # 0.8
# 和我们自己手动实现混淆矩阵、精准率、召回率所得到的结果是一样的。4.F1 Score
经过之前的学习,我们知道了对于样本极度偏斜的情况,使用精准率和召回率比使用准确度要好一些。
但是这样也有一个问题,那就是这是两个指标。既然是两个指标,就意味着肯定会有冲突,精准率高但召回率低、召回率高但精准率低,这样的话,我们该如何权衡呢?显然还是要业务场景有关。
比如我们进行股票预测,预测是升还是将。这显然是一个二分类问题,如果我们只关心股票升值的话,那么把股票升值预测为1、贬值预测为0,我们预测的就是精准率。因为我们关心的是预测为1的时候,有多少次是预测对的。如果是1,我们就投钱,是0,就不投钱。因此在这种情况下,如果精准率较低,就意味着FP较大,明明是贬值我们预测成了升值,就错误的把钱投进去了。但是召回率的话,对于我们不是很重要,因为召回率偏低意味着FN较大,说明股票明明是升值我们却预测成了贬值,但是对于我们来说,我们并没有投钱,即使召回率偏低的话,我们也不会亏损,尽管少了赚钱的机会。
如果业务场景是患病检测的话,那么我们就关心召回率了。如果召回率偏低的话,说明一些人是患病的,我们却预测成了没病,这是很严重的,会让病人的病情继续恶化下去。但是精准率偏低,意味着一些人没有病,我们却预测成了患病。但是呢?即便如此,再更进一步的检查,也可以检查出来是否真的患病,因此精准率偏低,只是意味着让一些人做了更进一步的检查罢了,这是没什么影响的。我们关注的是,要检测出患病的人,不能有漏网之鱼,这就意味着关注的召回率、而不是精准率。
因此要是场景而定,有些场景,精准率比召回率重要,有些场景,召回率比精准率重要。
然而有些场景,我们是要兼顾两者的,那么这时,就出现了新的指标,F1 Score
F1 Score的目的就是兼顾精准率和召回率
在这里提一个问题,如果让你设计F1 Score你会怎么做呢?一般情况下,会取精准率和召回率两者的平均值。没错,F1 Score也是类似的做法,只不过取的是两者的调和平均值

因此可以发现,当精准率或者召回率有一个为0的话,那么对应的F1 Score也为0。而且F1 Score的范围是0到1的,因为精准率和召回率都是一个小于1的数,那求倒数再相加然后除以二肯定大于1,说明1 / F1是大于1的,那么F1自然小于1。
可为什么要使用调和平均值呢?为什么不直接使用算数平均值呢?我们实际演示一下,就明白了。
def f1_score(precision, recall):
return 2 * precision * recall / (precision + recall)
print(f1_score(0.5, 0.5)) # 0.5
print(f1_score(0.1, 0.9)) # 0.18000000000000002可以看到如果使用算数平均值,那么这两者的结果应该是一样的。但是使用调和平均值的一大好处就是,只要有一个低,那么整体的结果依旧会很低。
我们使用上一节的例子来计算一下F1 Score
import numpy as np
from sklearn.datasets import load_digits
digits = load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, precision_score, recall_score
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
logistic = LogisticRegression()
logistic.fit(X_train, y_train)
y_predict = logistic.predict(X_test)
print("准确率:", precision_score(y_test, y_predict))
print("召回率:", recall_score(y_test, y_predict))
# f1 score和精准率以及召回率一样,只需要传入y_test和y_predict即可
print("F1 Score:", f1_score(y_test, y_predict))
"""
准确率: 0.9473684210526315
召回率: 0.8
F1 Score: 0.8674698795180723
"""5.精准率和召回率的平衡
我们之前说过,精准率和召回率。我们都希望这两个指标越高越好,但其实这两个指标有时是相互矛盾的,精准率提高那么召回率就会不可避免的降低,所以我们有了F1 Score,我们要找到的就是精准率和召回率之间的平衡。
还记得逻辑回归中的决策边界吗?我们可以类比一下
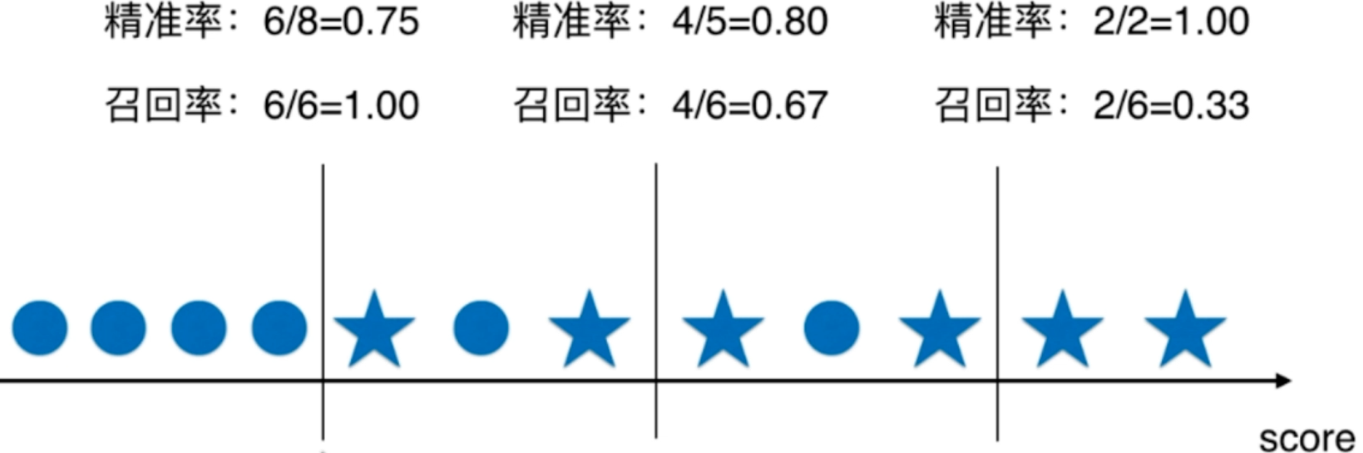
如果我们以中间的竖线作为决策边界,在右边的我们预测为1,左边的预测为0,我们关注的是五角星。那么我们预测为1的样本有五个,但是对的有4个,所以精准率就是4 / 5 = 0.8,而五角星总共有6个,所以召回率是4 / 6 = 0.67。如果我们以右边的竖线作为决策边界的话,那么显然精准率是百分之百,而召回率是 2 / 6 = 0.33。同理以左边的竖线作为决策边界的话,精准率就是6 / 8 = 0.75,因为我们预测8个为1,而真正为1的有6个;召回率则是6 / 6 = 1,因为尽管有两个错的,但是五角星我们都正确的识别出来了。
因此从这里我们可以看出,如果想要精准率提高的话,我们可以把阈值设置的高一些,对那些特别有把握的我们才分类为1,这也就导致了有些样本明明也为1,但是由于没有把握,我们分类为0,从而导致召回率降低。同理如果我们期望召回率高的话,我们可以把阈值设置的低一些,比如癌症患者,哪怕患病的概率只有百分之10,我们也归类为1,这样就很难有漏网之鱼了。然而这样做的代价就是有些不是癌症患者的,我们也分类为癌症患者,从而导致精准率降低。
精准率:正确识别为1的样本数 / 总共识别的样本数召回率:正确识别为1的样本数 / 所有特征为1的样本数
程序演示一下
# 我们如何改变一下决策边界呢?
# predict默认是以0作为决策边界的
# 但是对于逻辑回归来说,有这么一个函数,从名字也能看出来,是决策函数
decision_score = logistic.decision_function(X_test)
print(np.max(decision_score), np.min(decision_score)) # 19.88956556899649 -85.68605733401593
# 我们不按照predict默认的以0作为决策边界,而是自定义把大于等于n的分类为1,小于n的分类为0
def func(n):
y_predict2 = np.array(decision_score >= n, dtype=np.int)
from sklearn.metrics import recall_score, precision_score, f1_score
print("精准率", precision_score(y_test, y_predict2))
print("召回率", recall_score(y_test, y_predict2))
print("f1_score", f1_score(y_test, y_predict2))
func(5)
"""
精准率 0.96
召回率 0.5333333333333333
f1_score 0.6857142857142858
"""
func(10)
"""
精准率 1.0
召回率 0.28888888888888886
f1_score 0.4482758620689655
"""
func(-50)
"""
精准率 0.1174934725848564
召回率 1.0
f1_score 0.2102803738317757
"""
# 可以看到阈值设置的高,精准率也高,召回率会低
# 阈值设置的低,精准率也低,但召回率会高6.精准率和召回率曲线
我们来绘制一下,随着阈值的变化,精准率和召回率的变化曲线
import numpy as np
from sklearn.metrics import precision_score, recall_score
import matplotlib.pyplot as plt
precision_score_list = []
recall_score_list = []
def func(n):
y_predict2 = np.array(decision_score >= n, dtype=np.int)
precision_score_list.append(precision_score(y_test, y_predict2))
recall_score_list.append(recall_score(y_test, y_predict2))
threshold = np.arange(np.min(decision_score), np.max(decision_score), 0.1)
for t in threshold:
func(t)
plt.figure(figsize=(10, 8))
plt.plot(threshold, precision_score_list, color="pink", label="precision_score")
plt.plot(threshold, recall_score_list, color="green", label="recall_score")
plt.legend()
plt.grid()
plt.show()
从这个曲线,我们很明显能够看出,一开始阈值比较低,从而导致召回率高、精准率低,这是因为阈值低导致我们把太多的样本都分类为1了,不管是1或者不是1,我们都分成1了,从而精准率低,召回率高。但是随着阈值的增大,精准率提高,因为阈值变高导致分类为1的样本数变少了。而召回率没有变化,因为在阈值变化的一定范围内,我们还是把所有标签为1的样本全找出来了。
然鹅当阈值继续增大,召回率开始下降,这是因为阈值高了,说明分类为1的样本,都是非常有把握的。而有些样本标签虽然也为1,但是因为阈值或者说门槛提高了,通俗的说,就是变严格了,宁可错过一千,也不看错一个。比如股票,必须要有百分之90以上的把握预测会增长,如果没有90%以上的把握,就不买。说明有一些为1的,因为把握不够,我们漏掉了,从而导致召回率变低。而精准率显然是不断升高的,因为阈值越高,我们分类的就越有把握,阈值过高,可能最终我们就只选了10个样本,而这两个样本使我们能百分之百确定为1的,所以精准率为1。阈值再高,精准率同样是没有变化的,10个样本都为1,那么阈值提高,也只是从这10个样本中再去掉把握相对比较低的。比如其中5个样本我们99%确信是1,但是剩余5个我们只有95%的可信度。显然阈值提高就把具有95%可信度的样本去掉了,但是精准率依旧是1,然而召回率就比较可怜了。
我们可以从图像上观察,找到一个相对满意的位置,而且sklearn也为我们提供了方法,我们来看看
from sklearn.metrics import precision_recall_curve
# 只需要传入,至于要传入y_test, 和decision_function(X_test)即可
# 返回三个元素,看名字也知道分别是什么了
precision_score_list, recall_score_list, threshold = precision_recall_curve(y_test, decision_score)
# 但是注意的是,threshold的元素个数是比precision_score_list,recall_score_list要少1个的
# 这是因为,sklearn把threshold的最大值给去掉了,因为threshold最大值对应的精准率为1,召回率为0
plt.figure(figsize=(10, 8))
plt.plot(threshold, precision_score_list[: -1], color="pink", label="precision_score")
plt.plot(threshold, recall_score_list[: -1], color="green", label="recall_score")
plt.legend()
plt.grid()
plt.show()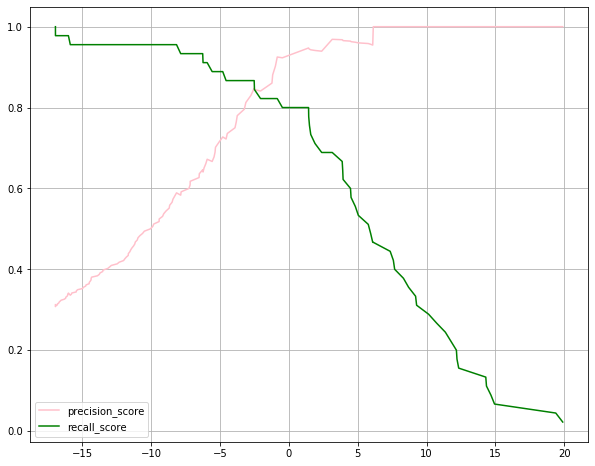
可以看到图像稍微有些变化,这是因为sklearn选择了它认为比较重要的部分。但是我们仍然可以看出来,这两者是相互制约的。
同理我们还可以将精准率作为x轴,召回率作为y轴,绘制图像。
plt.figure(figsize=(10, 8))
plt.plot(precision_score_list, recall_score_list, color="pink")
plt.grid()
plt.show()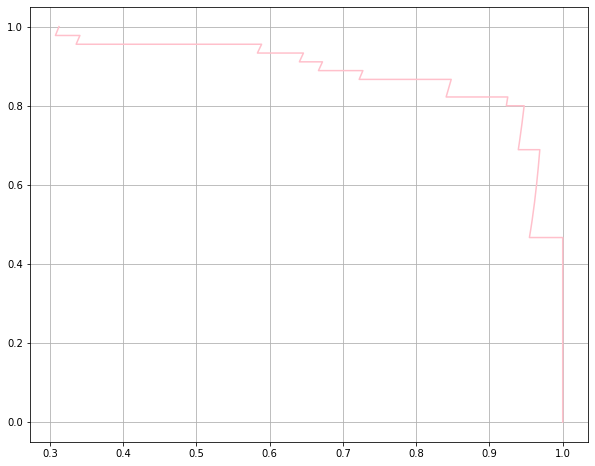
从图像上我们可以找出一个平衡的位置,通常这样的曲线都会有一个急剧下降的部分,显然就是精准率接近1的时候。
我们还可以使用精准率和召回率曲线(PR曲线)来衡量模型的好坏,因为PR曲线总体呈递减的趋势,我们不妨把图像画的平滑一些。
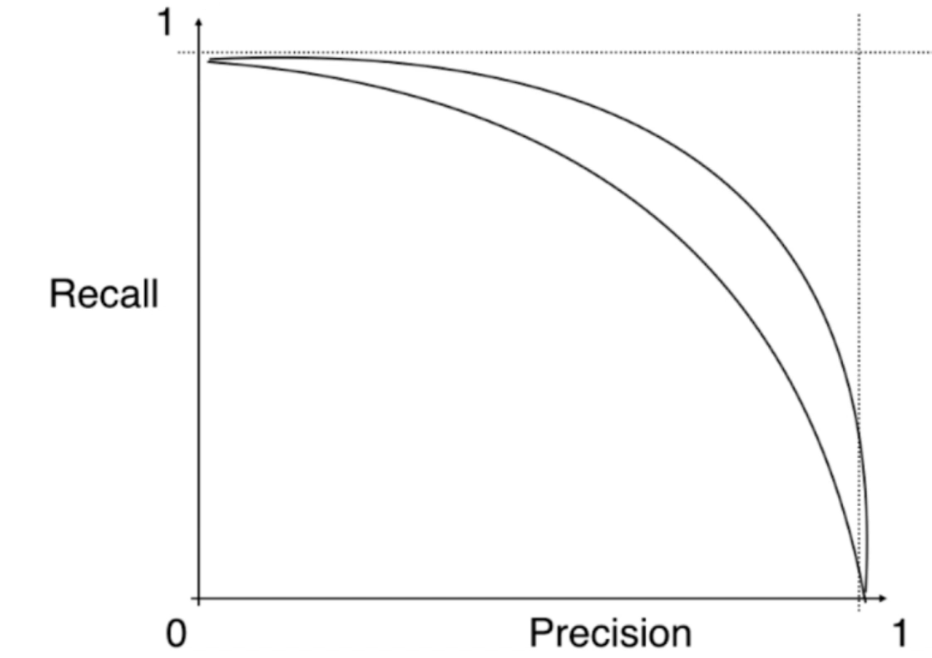
可以看到,图像越靠外,那么对应的模型就越好,因为这样对应的精准率和召回率就越高。或者我们说图像与两个轴围成的面积越大,那么模型效果越好。这样做是可以的,但虽然如此,可大多数情况下我们不用PR曲线的面积来衡量模型的优劣,而是使用另外一种曲线与XY轴围成的面积来衡量模型的优劣,也就是非常著名的ROC曲线。
7.ROC曲线
ROC:Receiver Operation Characteristic Curve,是一个统计学上经常使用的术语,它描述的是TPR和FPR之间的关系。
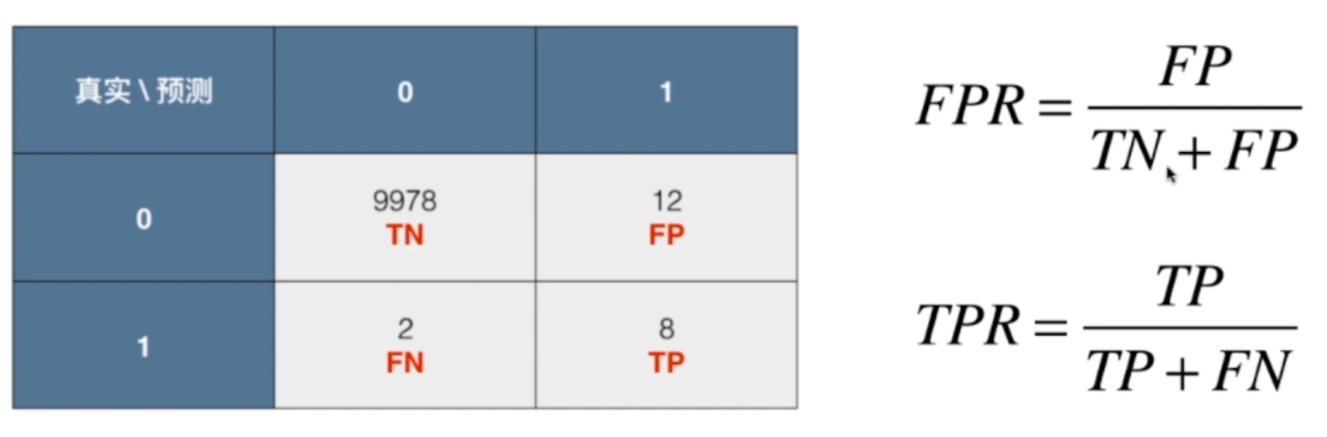
TPR:TP / (TP + FN),就是我们预测为1并且预测对了的数量,除以所有标签确实为1的样本数量,所以大家可能发现了,这个TPR其实就是recallFPR:FP / (TN + FP),就是我们预测为1但是预测错了的数量,除以所有标签为0的样本数量,这个FPR和TPR正好是相反的
正如精准率和召回率一样,TPR和FPR之间也有紧密的关系
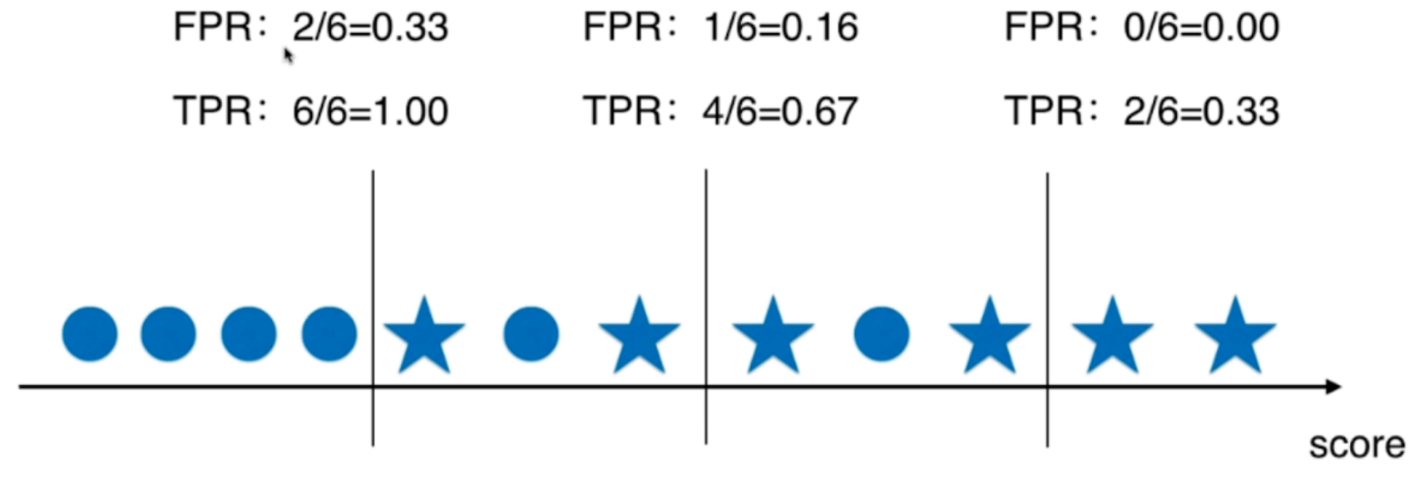
当直线在中间的时候,我们预测为1预测对了4个,预测为1预测错了1个,而标签为1的有6个,为0的也有6个,所以TPR = 4 / 6,FPR = 1 / 6;当直线在右边的时候,预测为1预测对了两个,预测为1预测错了0个,所以TPR = 2 / 6,FPR = 0 / 6;当直线在左边的时候,预测为1预测对了6个,预测为1预测错了2个,所以TPR = 6 / 6,FPR = 2 / 6
很明显样本总数是固定的,对于TPR和FPR影响的因素只有分母,当然threshold较小的时候,预测为1的个数就会变多,TPR比较大,但同时"误杀"的情况也会更严重,不是1的我们也分类为1了,threshold越小,错误分类为1的可能就越大,所以FPR也会比较大。但随着threshold增大的时候,门槛高了,有些是1的,我们分类为0了,所以TPR会减少,同时误杀的情况也变小了,毕竟特征是1的,都看走眼、分类为0了,更何况特征本来就是0的样本。所以threshold增大,TPR和FPR都会减小。
from sklearn.metrics import roc_curve
fprs, tprs, threshold = roc_curve(y_test, decision_score)
plt.plot(fprs, tprs)
plt.show()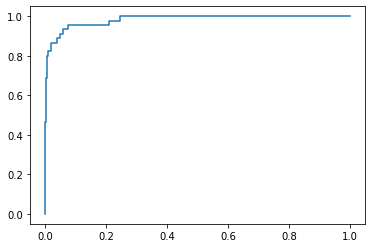
可以发现,面积的范围是不超过1的,这是因为TPR和FPR都不超过1。那么我们如何求面积呢?sklearn也为我们提供了相关的接口
from sklearn.metrics import roc_auc_score
# 参数和roc_curve是一致的
area = roc_auc_score(y_test, decision_score)
print(area) # 0.9830452674897119结果还是蛮大的,可以看出来,对于那些有偏斜的情况不是那么的敏感。我们以ROC围成的面积的大小作为模型好坏的评判标准。
8.多分类问题中的混淆矩阵
import numpy as np
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, confusion_matrix
digits = load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
logistic = LogisticRegression()
logistic.fit(X_train, y_train)
y_predict = logistic.predict(X_test)# 对于精准率、召回率、f1 score,sklearn默认只能解决2分类
# 如果是多分类,需要加上average="micro"参数
print(precision_score(y_test, y_predict, average="micro")) # 0.9555555555555556但是混淆矩阵,则是天然的支持多分类问题
print(confusion_matrix(y_test, y_predict))
"""
[[45 0 0 0 0 1 0 0 0 0]
[ 0 37 0 0 0 0 0 0 3 0]
[ 0 0 49 1 0 0 0 0 0 0]
[ 0 0 0 49 0 1 0 0 3 0]
[ 0 1 0 0 47 0 0 0 0 0]
[ 0 0 0 1 0 36 0 0 1 0]
[ 0 0 0 0 0 1 38 0 0 0]
[ 0 0 0 0 0 0 0 42 0 1]
[ 0 2 0 0 0 0 0 0 46 0]
[ 0 1 0 1 1 1 0 0 0 41]]
"""我们可以将矩阵转化为图像,在matplotlib中专门可以将矩阵转化为图像
cfm = confusion_matrix(y_test, y_predict)
# 调用matshow
plt.matshow(cfm, cmap=plt.cm.gray)
plt.show()
越亮的地方,说明值越大。但是对角线的地方是我们预测对了的情况,我们的关注点不在预测对了的上面。我们关注的是犯错误的地方。
cfm = confusion_matrix(y_test, y_predict)
# 对每一行求和,计算每一个格子所占的百分比
row_sums = np.sum(cfm, axis=1)
err_percent = cfm / row_sums
# 我们关注的不是预测对了的,而是错了的,所以可以把对角线的部分全部变为0
np.fill_diagonal(err_percent, 0)
# 调用matshow
plt.matshow(err_percent, cmap=plt.cm.gray)
plt.show()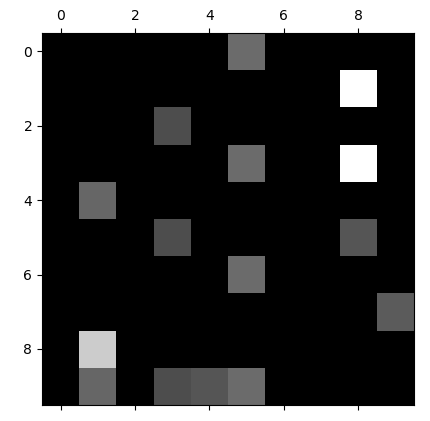
我们可以看到越亮的地方,说明我们犯的错误就越大。可以针对犯错误比较大的地方进行微调。