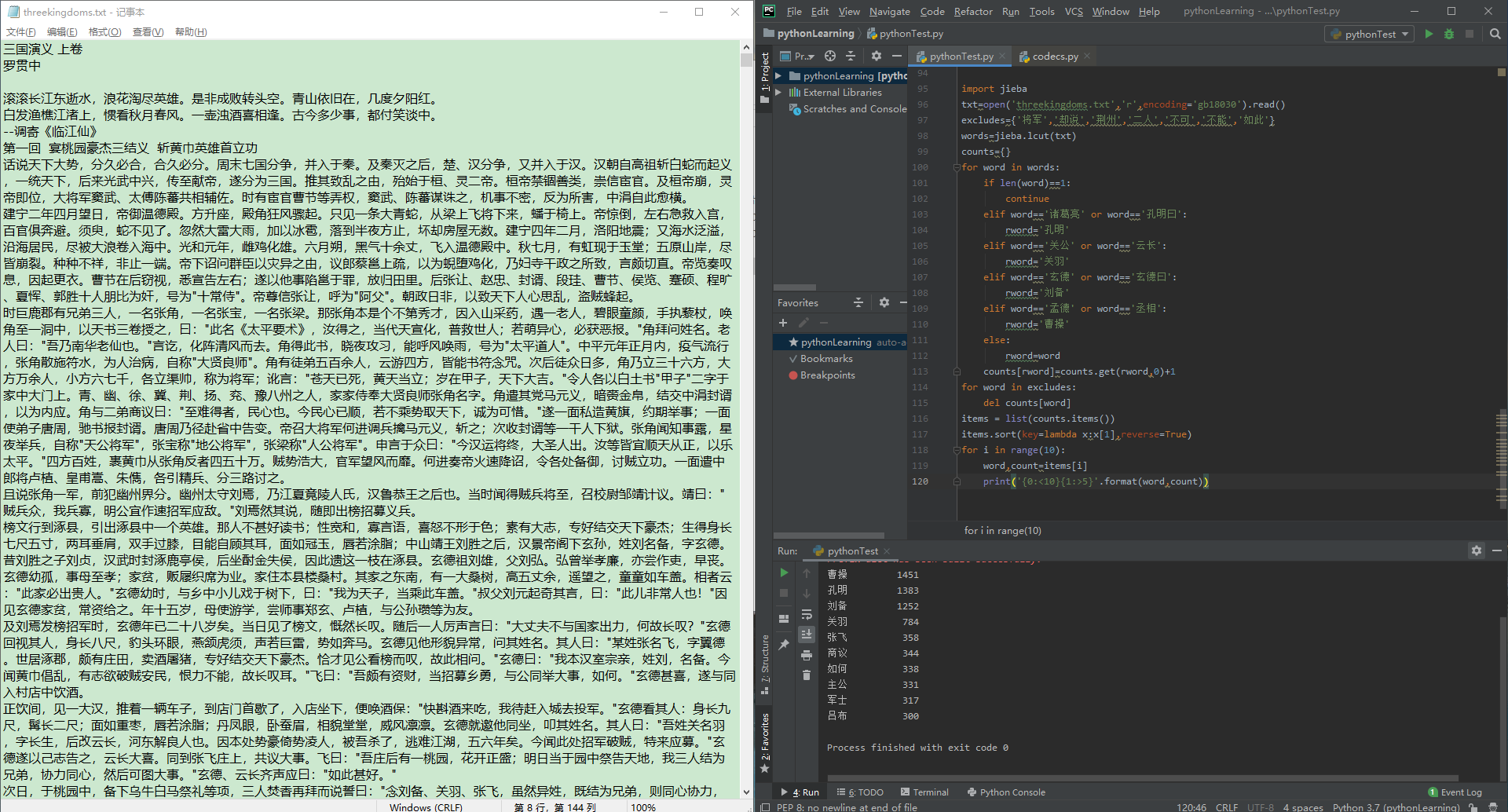
import jieba
txt=open('threekingdoms.txt','r',encoding='gb18030').read()
excludes={'将军','却说','荆州','二人','不可','不能','如此'}
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
elif word=='诸葛亮' or word=='孔明曰':
rword='孔明'
elif word=='关公' or word=='云长':
rword='关羽'
elif word=='玄德' or word=='玄德曰':
rword='刘备'
elif word=='孟德' or word=='丞相':
rword='曹操'
else:
rword=word
counts[rword]=counts.get(rword,0)+1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print('{0:<10}{1:>5}'.format(word,count))