文件
- 文件的操作
就是对磁盘数据的读写操作–推导出技术的IO操作
读写操作:read,write
问:什么是IO操作?
I – InputStream 字节输入流
O – OutputStream 字节输出流
- 打开文件
#创建一个demo.txt
file_name='demo.txt'
file_obj=open(file_name)
#r表示的是原始字符串,以下为绝对路径写法规范
file_name = r'C:\Users\lilichao\Desktop\hello.txt'
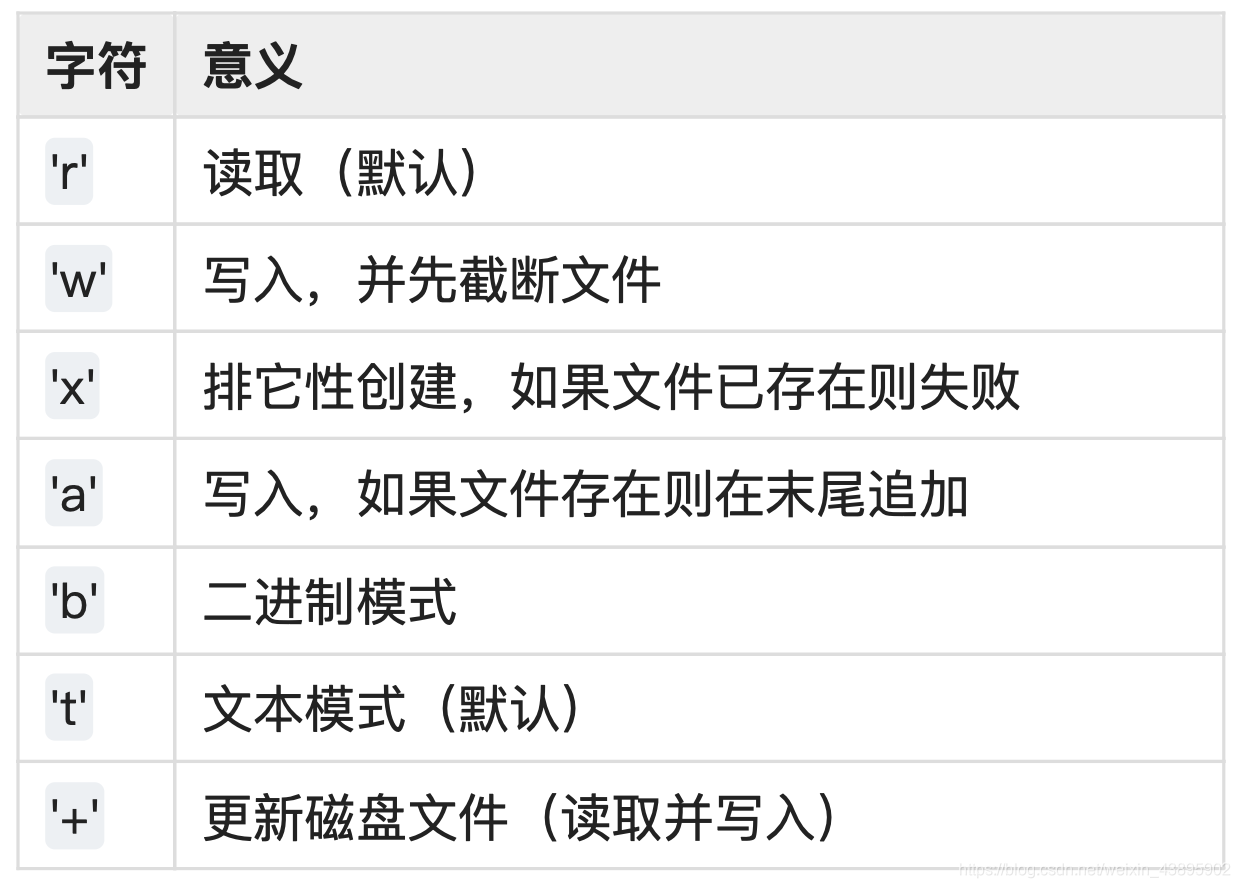
- open()函数
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
mode有以下取值:
- 读取文件内容
file_name='demo.txt'
#第一步:打开文件
file_obj=open(file_name)
#第二步,通过read,将磁盘数据写到服务器/控制台
content=file_obj.read()
print(content)
#第三步,close关闭文件
file_obj.close()
问: 如果在IO操作中,不关闭IO,会发生什么?
答: 如果不关闭IO,肯定会造成数据泄露,数据是不安全的
问: jdbc的讲解
答: 关闭四次:collection , statement , resultset , class.forname…打开四次:(所以Java写的很糟糕)如何解决?
大学:利用DBUtils封装
企业:C3po , JNDI , datasource–Mybatis
利用以上资源操作资源IO肯定不会泄露,服务器读取速度,性能较高,安全
解决在Python里面必须频繁close的方法
利用with…as…
with open(file_name) as file_obj:
print(file_obj.read)
此操作通过with…as…就可以在程序执行完成之后自动关闭IO操作.安全,高效.
程序读取不到文件的情况属于什么?
- 程序在读取过程中,肯定有找不到的情况 – FindNotFileexception
- 变量没有赋值–因为IO操作里面有很多不可控制的因素
try:
file_obj=open(file_name)
content=file_obj.read()
print(content)
except FindNotFoundError:
#肯定有文件读取不到的时候,需要抛异常,捕获异常,让程序变得更加安全
print('出错了')
- 文件读取中的处理
Python或者其他语言都是机器码,对中文不是很敏感,需要手动处理
调用open()来打开一个文件,可以将文件分成两种类型
一种,是纯文本文件(使用utf-8等编码编写的文本文件)
一种,是二进制文件(图片、mp3、ppt等这些文件)

出现乱码/中文不识别的原因:open()打开文件时,默认是以文本文件的形式打开的,但是open()默认的编码encoding为None,所以处理文本文件时,必须要指定文件的编码
#创建一个中文文档
file_name='demo2.txt'
try:
file_obj=open(file_name,encoding='utf-8')#转码
content=file_obj.read()
print(content)
except FindNotFoundError:
print('文件不存在')
-read函数可以将一个文件里面的全部文件全部读取,当有海量数据时,read函数不能使用,如果强制使用read读取海量数据,会发生一下结构:
1. 数据发生阻塞
2. 数据发生泄漏
3. 损失数据的完整,违背数据事物的原子性,离子性等
read()可以接收一个size作为参数,该参数用来指定要读取的字符的数量
默认值为-1,它会读取文件中的所有字符,
可以为size指定一个值,这样read()会读取指定数量的字符,每一次读取都是从上次读取到位置开始读取的
如果字符的数量小于size,则会读取剩余所有的,如果已经读取到了文件的最后了,则会返回’'空串
content = file_obj.read(-1)
- readline()
该方法用于一行一行的读取内容,它会一次性将读取到的内容封装到一个列表中返回
content=file_obj.readline()
file_name = 'demo.txt'
with open(file_name , encoding='utf-8') as file_obj:
print(file_obj,read())
r=file_obj.readline()
print(r)
#将数据通过readline()返回一个列表,也可以将数据保存到列表
#pprint.pprint(r[0])
#pprint.pprint(r[1])
for t in file_obj:#遍历数据快
print(t)
- 读取大文件
# 读取大文件的方式
file_name = 'demo.txt'
try:
with open(file_name,encoding='utf-8') as file_obj:
# 定义一个变量,来保存文件的内容
file_content = ''
# 定义一个变量,来指定每次读取的大小
chunk = 100
# 创建一个循环来读取文件内容
while True:
# 读取chunk大小的内容
content = file_obj.read(chunk)
# 检查是否读取到了内容
if not content:
# 内容读取完毕,退出循环
break
# 输出内容
# print(content,end='')
file_content += content
except FileNotFoundError :
print(f'{file_name} 这个文件不存在!')
print(file_content)
文件的写入
使用open()打开文件时必须要指定打开文件所要做的操作(读、写、追加)
如果不指定操作类型,则默认是 读取文件 , 而读取文件时是不能向文件中写入的
| 模式 | 含义 |
|---|---|
| r | 表示只读的 |
| w | 表示是可写的,使用w来写入文件时,如果文件不存在会创建文件,如果文件存在则会截断文件,截断文件指删除原来文件中的所有内容 |
| a | 表示追加内容,如果文件不存在会创建文件,如果文件存在则会向文件中追加内容 |
| x | 用来新建文件,如果文件不存在则创建,存在则报错 |
| + | 为操作符增加功能 |
| r+ | 即可读又可写,文件不存在会报错 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
with open(file_name , 'x' , encoding='utf-8') as file_obj:
# write()来向文件中写入内容,
# 如果操作的是一个文本文件的话,则write()需要传递一个字符串作为参数
# 该方法会可以分多次向文件中写入内容
# 写入完成以后,该方法会返回写入的字符的个数
file_obj.write('aaa\n')
file_obj.write('bbb\n')
file_obj.write('ccc\n')
r = file_obj.write(str(123)+'123123\n')
r = file_obj.write('今天天气真不错')
print(r)
NumPy
一种基于科学计算和多维数组等操作的一个文件/函数