聊这个问题的原因是,本周在测试环境遇到了一例从Spark往S3写数据失败的情况,花了些时间来搞清楚个中缘由,这里整理出来与大家分享,期望能对同道中人有所帮助。
背景
在笔者的数据系统中,每天会定时启动一个Spark批处理程序,对前一天的流处理结果进行合并、整理,然后写入AWS S3,从而提供尽可能快的冷数据查询(基于Presto SQL)。写数据的方式很简单,通过调用Spark DataFrame的write接口来完成的。
df.write.parquet("s3://qa-s3-data-merge-uw2/type=security/ts_interval=1550448000")
本周在测试环境做压力测试时,发现了一例程序处理失败的情况,所报的错误如下(已简化)。结合这个错误信息和Spark批处理程序运行的其他日志来看,当时写数据的Task已经成功将数据写入到了相关的temporary目录下,但是在Driver中执行commitJob将文件从temporary目录Rename到正式目录时失败了。
java.io.IOException: Failed to rename FileStatus{path=s3://qa-s3-data-merge-uw2/type=security/ts_interval=1550448000/_temporary/0/task_20190219103051_0010_m_000008/s3_partition_id=51/part-00008-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet; isDirectory=false; length=95831; replication=1; blocksize=67108864; modification_time=1550572263000; access_time=0; owner=hadoop; group=hadoop; permission=rw-rw-rw-; isSymlink=false} to s3://qa-s3-data-merge-uw2/type=security/ts_interval=1550448000/s3_partition_id=51/part-00008-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet
at org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter.mergePaths(FileOutputCommitter.java:415)
at org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter.mergePaths(FileOutputCommitter.java:428)
at org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter.mergePaths(FileOutputCommitter.java:428)
at org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter.commitJobInternal(FileOutputCommitter.java:362)
at org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter.commitJob(FileOutputCommitter.java:334)
at org.apache.parquet.hadoop.ParquetOutputCommitter.commitJob(ParquetOutputCommitter.java:47)
at org.apache.spark.internal.io.HadoopMapReduceCommitProtocol.commitJob(HadoopMapReduceCommitProtocol.scala:128)
......
针对这个错误,需要搞清楚以下三个问题:
- 我们只是想把数据写入到S3某个路径下,为什么会出现先写到temporary目录,再Rename到真实目录的情况?
- 为什么Rename会失败?
- 当前有哪些优化/解决方案?
Rename机制
首先来看看Spark写文件的执行方式和可能存在的问题。通常情况下,我们在单机上写文件时,都会生成一个指定文件名的文件,而调用Spark DataFrame的write接口来写文件时,所得到的结果却与此不同。如下图右侧所示,其写入了3个数据文件在指定的路径下。为什么会这样呢?这与Spark的执行方式有关。Spark是分布式计算系统,其RDD中的数据是分散在多个Partition中的,而每个Partiton对应一个Task来执行,这些Task会根据vcores个数来并行执行。在下图的示例中,笔者分配了3个Partition,所以生成了part-00000、part-00001、part-00002三个文件(文件名中间的一段UUID是在job中生成的)。按照这样的执行方式,假设我们直接把数据写入到指定的路径下,会出现哪些问题?
- 由于是多个Task并行写文件,如何保证所有Task写的所有文件要么同时对外可见,要么同时不可见?在下图示例中,三个Task的写入速度是不同的,那就会导致不同时刻看到的文件个数是不一样的。另外,如果有一个Task执行失败了,就会导致有2个文件残留在这个路径下。
- 同一个Task可能因为Speculation或者其他极端原因导致某一时刻有多个Task Attempt同时执行,即同一个Task有多个实例同时写相同的数据到相同的文件中,势必会造成冲突。如何保证最终只有一个是成功的并且数据是正确的?

上述的问题都与数据一致性有关,为了应对这些问题,尽可能保证数据一致性,Hadoop FileOutputCommitter设计了Rename机制(Spark写文件还是调用Hadoop的相关库来完成的)。Rename机制先后有两个版本:v1和v2,二者在性能和保证数据一致性的粒度上有所区别。
下图所示为v1的思想,其需要经历两次Rename。每个Task首先将数据写入如下临时路径:
${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt}/${fileName}
示例:
hdfs:///data/_temporary/0/_temporary/attempt_20190219101232_0003_m_000005_0/part-00000-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet
Task写入完成后,执行commitTask做第一次Rename,将文件从Task Attempt的临时目录中移动到Task的临时目录中。
${output.dir.root}/_temporary/${appAttempt}/${task}/${fileName}
示例:
hdfs:///data/_temporary/0/task_20190219101232_0003_m_000005/part-00000-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet
最后,当所有Task都完成上述操作后,由Driver负责执行commitJob做第二次Rename,依次将文件从每个Task的临时目录中移动到真实目录中,并写入_SUCCESS标识。
${output.dir.root}/${fileName}
示例:
hdfs:///data/part-00000-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet
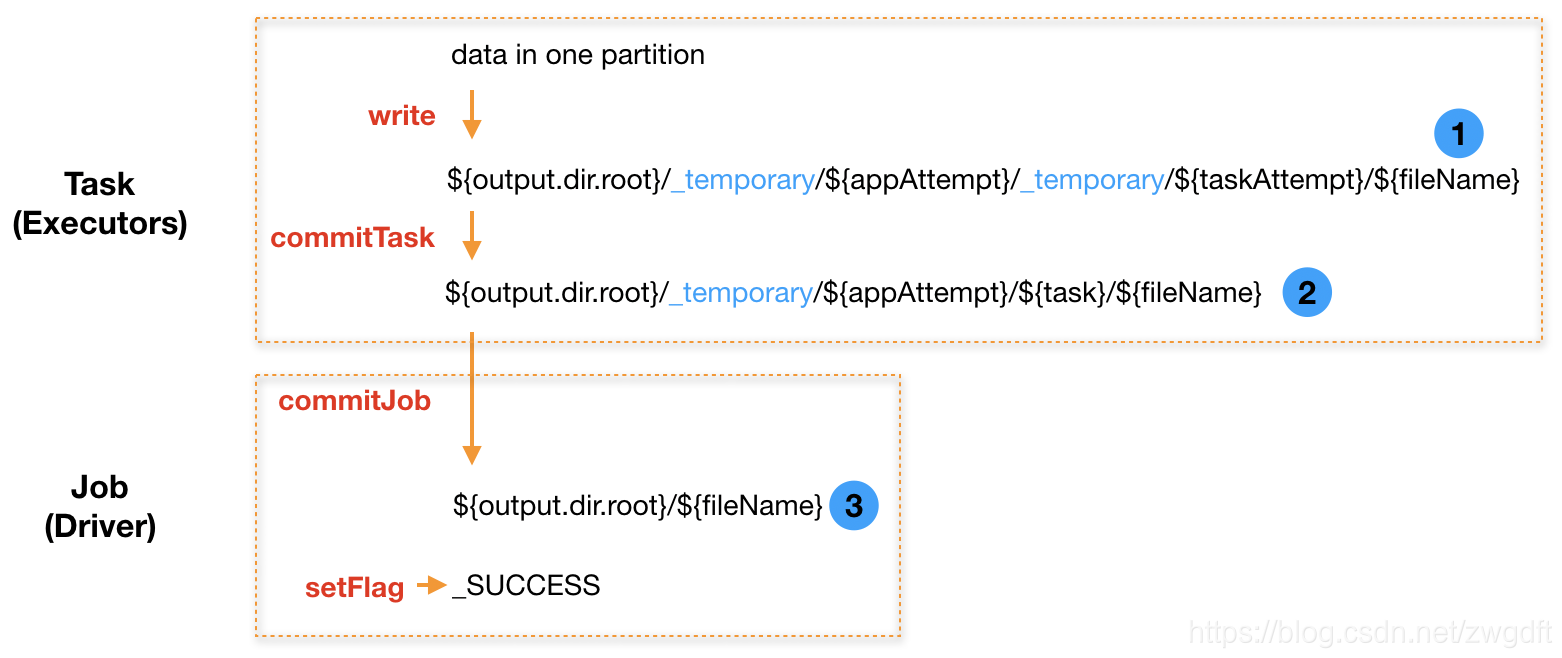
v1的思想较好的解决了前面提到的问题,基于此,只有在Rename的过程中出问题才可能导致数据一致性问题,然而这种概率相比之前提到的情况要低很多。但是,两次Rename也带来了性能问题,主要表现在:当有大量Task写入时,即使所有Task都完成了,还需要等待很长一段时间Job才能结束,这个时间主要花在Driver端做第二次Rename。例如,在笔者的系统中,每次需要写入1200个文件到S3,平均每个需要花费0.5~1.5秒的时间来做第二次Rename,整体需要花费10-30分钟。
于是,就有了下图所示的v2思想。相比v1而已,主要去除了在commitJob中做第二次Rename来提高性能,但是牺牲了一部分一致性。在v2中,如果部分Task已执行成功,而此时Job失败了,就会导致有一部分数据对外可见了,需要数据的消费者自己根据是否有_SUCCESS标记来判断其完整性。

S3的特殊性
Rename机制,对于像HDFS这样的分布式文件系统而言,无论是性能还是一致性的保证上都表现的很好,因为这样的操作出现错误的可能非常小。而对于AWS S3这样的对象存储则不同,原因主要如下:
- S3并没有所谓的Rename操作,需要使用List + Copy + Delete三个动作来实现;
- S3是最终一致性的。数据写入后,其内部会进行自动复制传递来实现冗余存储,在这段时间内进行List可能会拿到缺失的结果,进而导致Rename的操作是不完整的。数据被删除后,其内部也需要一段时间来同步,在这段时间内进行List可能会拿到已删除文件的信息,进而导致Rename操作失败。
优化的S3 Committer
针对像S3这样的对象存储的特殊性,目前有两种优化方案:一种是在Rename机制的基础上,增加Consistent View来保证对S3操作的一致性,实现方案有S3Guard;一种是采用S3 Multipart Upload机制来写文件,不再使用Rename机制,实现方案有S3A Committer。
Consistent View的思想是,利用一张表记录写入S3的文件信息,来补偿S3最终一致性的特性。文件写入成功后,会插入一条信息到表中,具体内容如下图所示(已简化)。当用List操作去列举S3上面的文件时,会将结果与该表中的记录进行对比,如果发现列举结果不完整,就会等待一段时间再去列举,直到二者信息一致才会继续其他操作。因为S3是AWS的对象存储服务,所以这个表也会放在AWS上,采用DynamoDB来实现。

S3 Multipart Upload机制,原本是S3用于支持大文件上传的方法。其将一次文件上传分解为三个动作:
- 第一步,初始化,向S3申请用于本次上传的Upload ID;
- 第二步,将大文件分解为多个Part进行上传,此过程中文件对外是不可见的;
- 第三步,全部Part上传完成后,向S3发送完成信号,S3内部会将多个Part的文件进行合并,之后文件对外可见;又或者发送取消信号,S3会将已上传的文件删除。

基于S3 Multipart Upload机制的Committer便是充分利用这个特性来保证数据的一致性。每个Task都利用Multipart Upload来上传文件,但是有两点不同:第一,只做前两步,即初始化和多Part上传;第二,通常只有1个Part文件。所有Task都成功后,由Driver在Job中统一做第三步,即发送完成信号,之后所有文件对外可见。

结束语
以上便是笔者当前认识到的Spark写文件的机制,更多细节可以参考阅读源码。至于文章开头提到的失败情况,因为笔者公司的Spark相关业务都部署在AWS EMR上,目前通过升级AWS EMR版本来解决。EMR在其5.20.0之后的版本中,默认采用EMRFS S3-optimized Committer,其采用了上述的S3 Multipart Upload机制,当然目前仅支持从DataFrame、SQL中写Parquet文件,不过已经能满足需求了。
参考文献
[1] Hadoop FileOutputCommitter Source Code
[2] Committing work to S3 with the “S3A Committers”
[3] Introducing the S3A Committers
[4] Introduction to S3Guard
[5] Spark 2.0.0 Cluster Takes a Longer Time to Append Data
(全文完,本文地址:https://bruce.blog.csdn.net/article/details/87955023 )
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2019/03/03 下午