aapt资源编译
- 编译assets目录和res/raw目录下的资源
- 编译res目录下的资源文件
- 给res目录下的每个资源赋予一个资源ID,生成resource.arsc资源索引文件
- 解析并编译AndroidMainifest.xml
- 资源打包成*.ap_,资源ID常量定义自R.java
资源索引
aapt给每一个非assets目录的资源定义一个资源ID,它是一个4字节(byte = 8bit)的数字,格式是PPTTNNNN,PP代表资源所属的包(package),TT代表资源的类型(Type),NNNN代表这个类型下面的资源名称(Entry ID)。
- Package ID相当于是一个命名空间,标定资源的来源。系统资源的命名空间,它的package ID等于0x01;自己的APP资源名称空间,Package ID一般定义为0x7f。
- Type ID是指资源的类型ID。资源的类型都有animator、anim、color、drawable、layout、menu、raw、string和xml等等若干种,每一种都会被赋予一个ID。
- Entry ID是指每一个资源在其所属的资源类型中所出现的次序。
代码编译和打包
- AIDL -> 生成对应的java接口
- Javac -> 生成.class文件
- dex-> 生成dex文件
- APkBuilder:aapt打包好的资源、dex打包好的代码文件、第三方库资源和jar文件、native -> apk
签名
v1签名
对签名后的apk进行解压缩,在META-INF目录下一般会有三个文件:MANIFEST.MF、CERT.SF和CERT.RSA三个文件,这里用不同的证书和签名方式得到的名字可能不同。
- .MF文件:apk当中的原始文件信息用摘要算入如SHA1(或者SHA256)计算得到的摘要信息并用base64编码保存,以及对应采用的摘要算法如SHA1(这个算法的特征是不管多大的文件内容都能够得到长度相同的摘要信息,但是不同的文件内容信息得到的摘要信息肯定不相同)
- .SF文件:.MF文件的只要信息以及.MF文件中每个条目在用摘要算法计算得到的摘要信息,对这些内容使用base64编码后保存
- .RAS文件:存放证书信息、公钥信息以及用私钥对.SF文件的加密数据即签名信息,这段数据是无法伪造的,除非你有私钥,病外.RSA文件还记录了所有的签名算法等信息.
APK包在安装的时候,是按照RSA->SF->MF的顺序依次校验的:**先用公钥信息还原签名信息,然后和.SF文件中的信息进行比对,然后用同样的摘要算法对.MF文件里的每一个条目计算对应的摘要信息,然后比对.MF是否一致。
缺点
- 在校验的过程中需要解压,因为.MF文件的摘要信息是基于原始未压缩的文件内容,因此在校验的时候需要解压出原始数据,而这个解压操作无疑是耗时的。
- apk包的完整性校验不够强。这里可以看到如果我们在apk签名后,如果对apk包中没有涉及到原始文件内容的数据块做修改那么这层校验机制就会失效。
V2签名
简单来说,v2签名模式在原先apk块中添加了一个新的块(签名块),新的块存储了签名、摘要、签名算法、证书链和一些额外的属性等。这个块有特定的格式。

apk的格式签名后变成了下面4个部分
Local file header 1 //第一部分开始
compressed data
data descriptor(可选)
.....
Local file header n
compressed data
data descriptor(可选) //第一部分结束
APK Signning Block //签名块
Central directory header1 //第二部分开始
....
Central directory headern //第二部分结束
End Of Central Directory //第三部分
其中第三部分有一个偏移值直接指向了第二部分的开始位置,而每个第二部分如Central directory header1 … Central directory headern的有一个便宜字段指向了其中对应的第一部分。
Central directory header1--->Local file header1
...
Central directory headern--->Local file headern
签名块包括对apk第一部分、第二部分和第三部分的二进制内容做加密保护,摘要算法以及签名算法。签名块本身不做加密,这里需要特殊注意的是由于第三部分包含了对第二部分的引用偏移,因此如果签名块做了改变,比如在签名过程中增加了一种签名算法,或者增加签名者等信息就会导致这个偏移发生改变,因此在算摘要信息的时候需要剔除这个音粗要以第三部分对签名块的偏移来做计算。
v2签名块格式
接下来我们看看具体的apk签名块格式,改格式分为4个部分:
- 分块长度
- v2模式块
- 分块长度
- 固定magic值
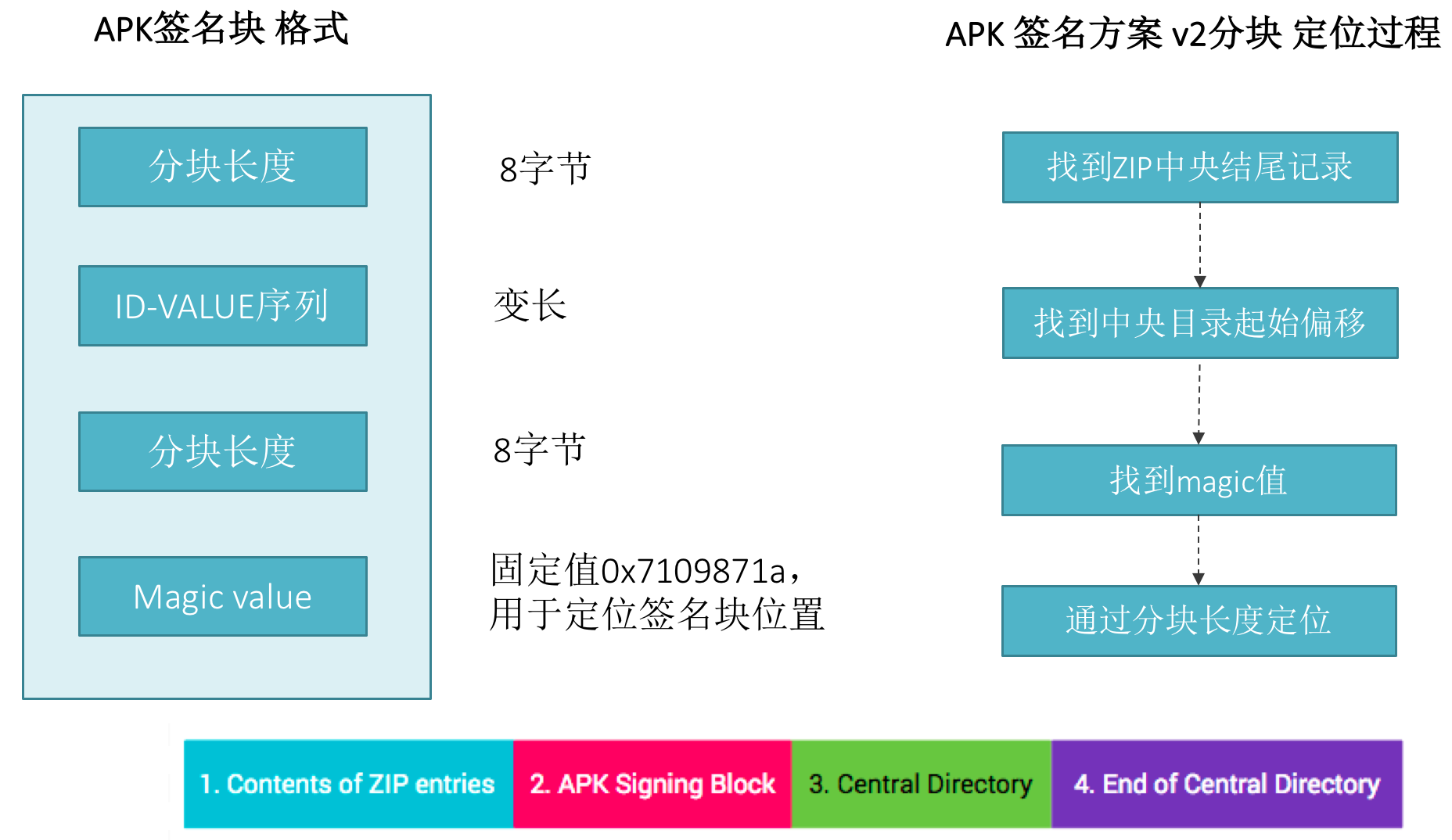
怎样找到v2分块的位置:ZIP中央结尾记录->中央目录其实偏移量->固定magic值,然后就可以定位v2分块的位置。

摘要计算过程
v2签名块负责保护第1、3、4部分的完整性,以及第二部分包含的APK签名方案 v2分块中的signed data分块的完整性。第1、3、4部分的完整性是通过内容摘要来保护的,这些摘要保存在signed data分块中,而signed data分块的完整性是通过签名保证的。下面开计算摘要的过程
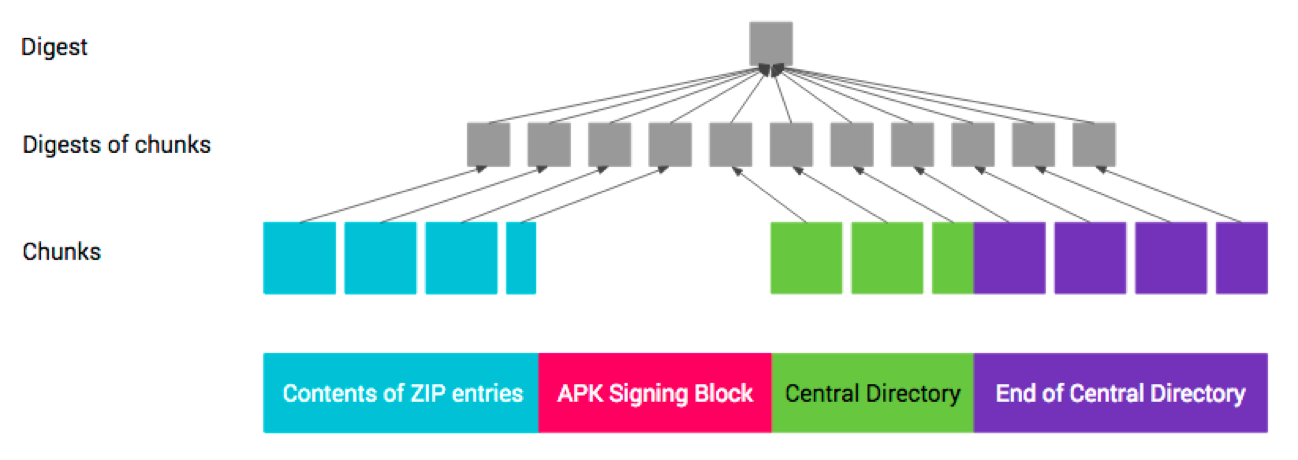
第1、3和4部分的摘要要采用以下的计算方法
- 拆分chunk:将每个部分拆分成为多个大小为1MB大小的chunk,最后一个chunk可能小于1MB,之所以要分块,是为了可以通过并行计算摘要以加快计算速度。
- 计算chunk摘要:字节
0xa5+块的长度(字节数)+块的内容进行计算 - 计算整体摘要:字节
0x5a+chunk数+块的摘要的连接(按块在APK中的顺序)进行计算。
从上面我们可以看到 v2 模式块有点类似于我们 META-INF 文件夹下的信息内容。
zipalign
- 对签名后的apk进行对齐处理,在apk中所有的未压缩文件,如图片、raw资源,按照4字节来对齐。
- 其实就是使用空间换时间,CPU是按字节读取内存的,内存对齐可以避免读取某个类型数据时需要二次读取。对于Linux系统,CPU就可以直接用mmap()来存取数据。因此,在加载资源时,系统不需要把全部数据都加载到RAM,降低了内存占用和电量的消耗,提高了资源存取效率。
多渠道打包
- Flavor + BuildType
- 在assets目录添加配置文件
- META-INF
- v2签名的多渠道打包