-
Working with spring data repositories
-1.1 Core concepts -
- Spring数据存储库抽象中的中心接口是repository。它使用域类和域类的ID类型作为类型参数来管理。这个接口主要作为一个标记接口来捕获要使用的类型,并帮助您发现扩展这个接口的接口。CrudRepository为正在管理的实体类提供了复杂的CRUD功能。
-
CrudRepository 接口
-

-
在CrudRepository之上,有一个PagingAndSortingRepository抽象,它添加了额外的方法来简化对实体的分页访问
-
PagingAndSortingRepository 接口
-

-
ex:要按页面大小20访问用户的第二个页面,可以执行以下操作

-
除了查询方法之外,还提供了count和delete查询的查询派生。下面的列表显示了派生count查询的接口定义

-下面的列表显示了派生delete查询的接口定义

-
1.2 Query methods
-
标准CRUD功能存储库通常对基础数据存储区进行查询。 使用Spring Data,声明这些查询将分为四个步骤:
-
- 声明扩展Repository或其子接口之一的接口,并将其键入应处理的域类和ID类型,如以下示例所示:

- 声明扩展Repository或其子接口之一的接口,并将其键入应处理的域类和ID类型,如以下示例所示:
-
- 在接口上声明查询方法。

- 在接口上声明查询方法。
-
- 设置Spring,使用JavaConfig或XML配置为这些接口创建代理实例。
-
a.要使用Java配置,请创建一个类似于下面的类

-
b.要使用XML配置,请定义一个类似于下面的bean
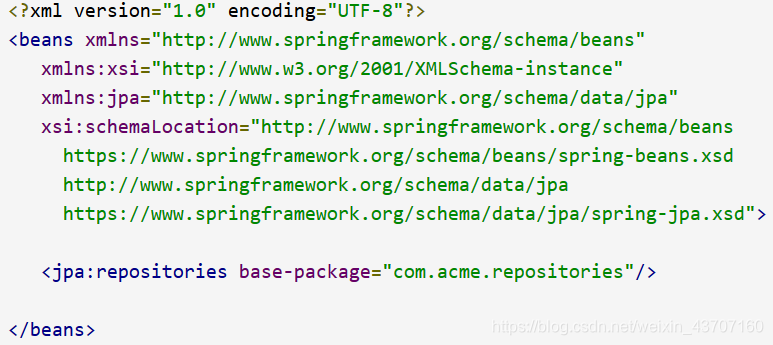
-
- 注入repository实例并使用它,如下面的示例所示

- 注入repository实例并使用它,如下面的示例所示
-
1.3 Defining Repository Interfaces
-
首先,定义一个特定于域类的存储库接口。接口必须扩展Repository,并将其类型转换为域类和ID类型。如果希望为该域类型公开CRUD方法,请扩展CrudRepository而不是Repository。
-
1.3.1 Fine-tuning Repository Definition
-
通常,存储库接口扩展了存储库、CrudRepository或PagingAndSortingRepository。另外,如果不希望扩展Spring data接口,还可以使用@RepositoryDefinition注释存储库接口。扩展CrudRepository公开了一组完整的方法来操作实体。如果您喜欢选择要公开的方法,请将要公开的方法从CrudRepository复制到域存储库中。
-
ex: 选择性地公开CRUD方法

-
在前面的示例中,您为所有域存储库定义了一个公共基本接口,并公开了findById(…)以及save(…)。这些方法被路由到Spring Data提供的所选商店的基本存储库实现中( 例如,如果您使用JPA,则实现是SimpleJpaRepository),因为它们与CrudRepository中的方法签名匹配。 因此,UserRepository现在可以保存用户,按ID查找单个用户,并触发查询以通过电子邮件地址查找用户。
-
ps: 中间存储库接口使用@NoRepositoryBean注释。 确保将该注释添加到Spring Data不应在运行时创建实例的所有存储库接口。
-
1.3.2 Null Handling of Repository Methods (Repository 方法的空处理)
-
从Spring Data 2.0开始,返回单个聚合实例的repository CRUD方法使用Java 8 s可选方法来表示可能缺少值。除此之外,Spring Data支持在查询方法上返回以下包装器类型
-
- com.google.common.base.Optional
-
- scala.Option
-
- io.vavr.control.Option
-
- javaslang.control.Option (deprecated as Javaslang is deprecated)
-
或者,查询方法可以选择根本不使用包装器类型。然后通过返回null来指示查询结果的缺失。返回集合、集合替代方案、包装器和流的存储库方法保证永远不会返回null,而是相应的空表示。有关详细信息,请参阅存储库查询返回类型。
-
Nullability Annotations
-
您可以使用Spring Framework的nullability注解来表示存储库方法的nullability约束。它们提供了一种工具友好的方法,并在运行时检查空值,如下所示
-
@NonNullApi:在包级别上使用,以声明参数和返回值的默认行为是不接受或生成空值。
-
@NonNull:用于不能为null的参数或返回值(在应用@NonNullApi的参数和返回值上不需要)。
-
@Nullable:用于可以为null的参数或返回值。
-
Spring注释是使用JSR 305注释进行元注释的(一种休眠但广泛传播的JSR)。 JSR 305元注释允许IDEA,Eclipse和Kotlin等工具供应商以通用方式提供空安全支持,而无需对Spring注释进行硬编码支持。 要为查询方法启用运行时检查可空性约束,需要在package-info.java中使用Spring的@NonNullApi来激活包级别的非可空性,如以下示例所示:
-
ex: Declaring Non-nullability in package-info.java(在package-info.java中声明不可空性)

-
一旦设置了非空默认值,就会在运行时验证存储库查询方法调用是否为空约束。如果查询执行结果违反了定义的约束,则抛出异常。当方法返回null但声明为不可空时,就会发生这种情况(默认情况下,在存储库所在的包上定义了注释)。如果您想再次选择进入可空结果,请有选择地对单个方法使用@Nullable。使用本节开始时提到的结果包装器类型继续按预期工作:空结果是transl
-
*ex:*Using different nullability constraints

-
Nullability in Kotlin-based Repositories
-
Kotlin对语言中的可空性约束进行了定义。 Kotlin代码编译为字节码,它不通过方法签名表达可空性约束,而是通过编译元数据表达。 确保在项目中包含kotlin-reflect JAR,以便对Kotlin的可空性约束进行内省。 Spring Data存储库使用语言机制来定义这些约束以应用相同的运行时检查,如下所示:
-
*ex:*Using nullability constraints on Kotlin repositories

-
1.3.3 Using Repositories with Multiple Spring Data Modules
-
在应用程序中使用唯一的Spring Data模块会使事情变得简单,因为定义范围内的所有存储库接口都绑定到Spring Data模块。 有时,应用程序需要使用多个Spring Data模块。 在这种情况下,存储库定义必须区分持久性技术。 当它在类路径上检测到多个存储库工厂时,Spring Data进入严格的存储库配置模式。 严格配置使用存储库或域类的详细信息来确定存储库定义的Spring Data模块绑定:
-
- 如果存储库定义扩展了特定于模块的存储库,那么它是特定Spring Data模块的有效候选者。
-
- 如果使用特定于模块的类型注释对域类进行注释,则它是特定Spring Data模块的有效候选者。 Spring Data模块接受第三方注释(例如JPA的@Entity)或提供自己的注释(例如Spring Data MongoDB和Spring Data Elasticsearch的@Document)。
-
ex: Repository definitions using module-specific interfaces(使用特定于模块的接口的存储库定义)

-
MyRepository和UserRepository在其类型层次结构中扩展JpaRepository。 它们是Spring Data JPA模块的有效候选者。
-
**ex:**Repository definitions using generic interfaces(使用泛型接口的存储库定义)

-
AmbiguousRepository和AmbiguousUserRepository仅在其类型层次结构中扩展Repository和CrudRepository。 虽然这在使用独特的Spring Data模块时非常好,但是多个模块无法区分这些存储库应该绑定到哪个特定的Spring Data。
-
The following example shows a repository that uses domain classes with annotations:
-
**ex:**Repository definitions using domain classes with annotations(使用带注释的域类的存储库定义)

-
PersonRepository引用Person, Person使用JPA @Entity注释,因此该存储库显然属于Spring Data JPA。UserRepository引用User,后者使用Spring Data MongoDB s @Document注释。
-
存储库类型详细信息和区分域类注释用于严格存储库配置,以识别特定Spring数据模块的存储库候选。 在同一域类型上使用多个持久性技术特定的注释是可能的,并允许跨多种持久性技术重用域类型。 但是,Spring Data不再能够确定用于绑定存储库的唯一模块。
-
区分存储库的最后一种方法是通过确定存储库基础包的范围。 基础包定义了扫描存储库接口定义的起点,这意味着将存储库定义放在相应的包中。 默认情况下,注释驱动的配置使用配置类的包。 基于XML的配置中的基础包是必需的。
-
The following example shows annotation-driven configuration of base packages:
-
**ex:**Annotation-driven configuration of base packages(基础包的注释驱动配置)

-
1.4 Defining Query Methods
-
存储库代理有两种方法从方法名派生特定于存储的查询:
-
- 通过直接从方法名派生查询
-
- 通过使用手动定义的查询
-
可用选项取决于实际存储。但是,必须有一个策略来决定创建什么实际查询。下一节将介绍可用的选项。
-
1.4.1 Query Lookup Strategies (查询查找策略)
-
存储库基础结构可以使用以下策略来解析查询。 使用XML配置,您可以通过query-lookup-strategy属性在命名空间配置策略。 对于Java配置,您可以使用Enable $ {store}存储库注释的queryLookupStrategy属性。 特定数据存储可能不支持某些策略。
-
CREATE尝试从查询方法名称构造特定于存储的查询。 一般方法是从方法名称中删除一组已知的前缀,并解析方法的其余部分。 您可以在“查询创建”中阅读有关查询构造的更多信息。
-
USE_DECLARED_QUERY尝试查找声明的查询,如果找不到,则抛出异常。 查询可以通过某处的注释来定义,也可以通过其他方式声明。 查阅特定存储的文档以查找该存储的可用选项。 如果存储库基础结构在引导时未找到该方法的声明查询,则它将失败。
-
CREATE_IF_NOT_FOUND(默认)结合了CREATE和USE_DECLARED_QUERY。 它首先查找声明的查询,如果没有找到声明的查询,它会创建一个基于自定义方法名称的查询。 这是默认的查找策略,因此,如果您未明确配置任何内容,则使用此策略。 它允许通过方法名称进行快速查询定义,还可以根据需要引入声明的查询来自定义这些查询。
-
1.4.2 Query Creation
-
Spring Data存储库基础结构中内置的查询构建器机制对于构建对存储库实体的约束查询非常有用。 该机制剥离前缀find … By,read … By,query … By,count … By,and get …来自该方法并开始解析其余部分。 introduction子句可以包含更多表达式,例如Distinct在要创建的查询上设置不同的标志。 但是,第一个By用作分隔符以指示实际条件的开始。 在最基本的层面上,您可以在实体属性上定义条件,并将它们与And和Or连接起来。 以下示例显示了如何创建大量查询:
-
ex: Query creation from method names

-
解析方法的实际结果取决于您为其创建查询的持久性存储。 但是,有一些一般要注意的事项:
-
- 表达式通常是属性遍历与可以连接的运算符相结合。 您可以将属性表达式与AND和OR组合在一起。 对于属性表达式,您还可以获得诸如Between,LessThan,GreaterThan和Like之类的运算符。 支持的运算符可能因数据存储而异,因此请参阅参考文档的相应部分。
-
- 方法解析器支持为各个属性设置IgnoreCase标志(例如,findByLastnameIgnoreCase(…))或支持忽略大小写的类型的所有属性(通常是String实例 - 例如,findByLastnameAndFirstnameAllIgnoreCase(…))。 是否支持忽略大小写可能因商店而异,因此请参阅参考文档中有关特定于从存储的查询方法的相关章节。
-
- 您可以通过将OrderBy子句附加到引用属性的查询方法并提供排序方向(Asc或Desc)来应用静态排序。 要创建支持动态排序的查询方法,请参阅“特殊参数处理”。
-
1.4.4 Special parameter handling(特殊参数处理)
-
要处理查询中的参数,请按照前面示例中所示定义方法参数。此外,基础结构可以识别某些特定类型,比如分页和排序,以便动态地将分页和排序应用于查询。下面的示例演示了这些特性
-
ex: Using Pageable, Slice, and Sort in query methods
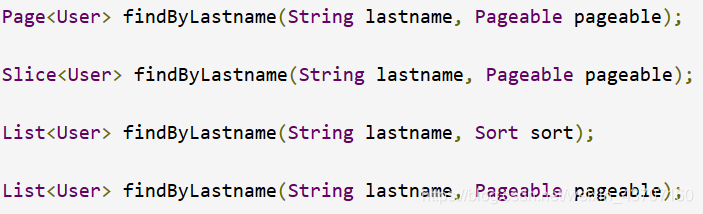
-
第一种方法允许您将org.springframework.data.domain.Pageable实例传递给查询方法,以动态地向您的静态定义查询添加分页。 页面知道可用元素和页面的总数。 它通过基础结构触发计数查询来计算总数来实现。 由于这可能很奢侈(取决于所使用的存储),您可以改为返回切片。 Slice只知道下一个Slice是否可用,这在遍历更大的结果集时可能就足够了。
-
排序选项也通过Pageable实例处理。 如果只需要排序,请在方法中添加org.springframework.data.domain.Sort参数。 如您所见,也可以返回List。 在这种情况下,不会创建构建实际页面实例所需的其他元数据(反过来,这意味着不会发出必要的附加计数查询)。 相反,它限制查询仅查找给定范围的实体。
-
要找出整个查询的页数,必须触发一个附加的count查询。默认情况下,此查询派生自您实际触发的查询。
-
1.4.5 Limiting Query Results(限制查询结果)
-
查询方法的结果可以通过使用第一个或顶部关键字来限制,这些关键字可以互换使用。 可选的数值可以附加到top或first,以指定要返回的最大结果大小。 如果省略该数字,则假定结果大小为1。 以下示例显示如何限制查询大小:
-
*ex:*Limiting the result size of a query with Top and First(使用Top和First限制查询的结果大小)

-
限制表达式也支持Distinct关键字。 此外,对于将结果集限制为一个实例的查询,支持使用Optional关键字将结果包装。
-
如果将分页或切片应用于限制查询分页(以及可用页数的计算),则将其应用于有限结果中。
-
通过使用Sort参数将结果与动态排序结合使用,可以表达“K”最小元素和“K”元素的查询方法。
-
1.4.6 Streaming query results (流查询结果)
-
通过使用Java 8 Stream作为返回类型,可以增量地处理查询方法的结果。使用特定于流数据存储的方法来执行流,而不是将查询结果包装在流数据存储中,如下面的示例所示
-
*ex:*Stream the result of a query with Java 8 Stream
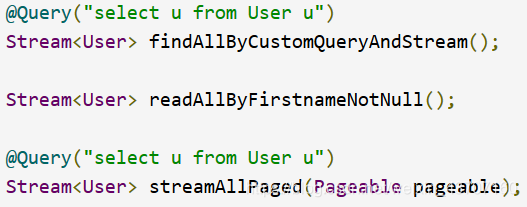
-
流可能会包装特定于数据库的底层资源,因此必须在使用后关闭。您可以使用close()方法手动关闭流,也可以使用Java 7 try-with-resources块,如下面的示例所示
-
*ex:*Working with a Stream result in a try-with-resources block

并非所有Spring data模块目前都支持流作为返回类型。
-
1.4.7 Async query results(异步查询结果)
-
通过使用Spring的异步方法执行功能,可以异步运行存储库查询。这意味着方法在调用时立即返回,而实际查询执行发生在已提交给Spring TaskExecutor的任务中。异步查询执行与反应性查询执行不同,不应该混合执行。有关响应性支持的详细信息,请参阅特定于商店的文档。下面的示例显示了一些异步查询

-
1.5 Creating Repository Instances(创建存储库实例)
-
在本节中,您将为已定义的存储库接口创建实例和bean定义。一种方法是使用Spring名称空间,它与支持存储库机制的每个Spring数据模块一起提供,不过我们通常建议使用Java配置。
-
1.5.1 XML configuration
-
每个Spring Data模块都包含一个存储库元素,允许您定义Spring为您扫描的基础包,如以下示例所示:
-
ex: Enabling Spring Data repositories via XML(通过XML启用Spring Data存储库)

-
Using filters(使用过滤器)
-
默认情况下,基础结构会选择扩展位于已配置的基础包下的特定于持久性技术的Repository子接口的每个接口,并为其创建一个bean实例。 但是,您可能希望对哪些接口为其创建bean实例进行更细粒度的控制。 为此,请在元素中使用和元素。 语义完全等同于Spring的上下文命名空间中的元素。 有关详细信息,请参阅这些元素的Spring参考文档。
-
例如,要将某些接口从实例化为存储库bean中排除,可以使用以下配置
-
ex: Using exclude-filter element(使用排除筛选器元素)

-
前面的示例排除了在SomeRepository中结束的所有接口的实例化。
-
1.5.2 JavaConfig
-
还可以通过在JavaConfig类上使用特定于商店的@ Enable $ {store}存储库注释来触发存储库基础结构。 有关Spring容器的基于Java的配置的介绍,请参阅Spring参考文档中的JavaConfig。
-
ex: Sample annotation based repository configuration(基于注释的库配置示例)

-
前面的示例使用特定于jpa的注释,您可以根据实际使用的存储模块更改注释。EntityManagerFactory bean的定义也是如此。请参阅有关特定于商店的配置的部分。
-
1.5.3 Standalone usage
-
例如,您还可以在CDI环境中使用Spring容器外部的存储库基础设施。您的类路径中仍然需要一些Spring库,但通常也可以通过编程设置存储库。提供存储库支持的Spring数据模块提供了一个特定于持久性技术的RepositoryFactory,您可以使用它,如下所示
-
*ex:*Standalone usage of repository factory(独立的存储库工厂的使用)

-
1.6 Custom Implementations for Spring Data Repositories(Spring data存储库的自定义实现)
-
本节介绍存储库自定义以及片段如何构成复合存储库。
-
当查询方法需要不同的行为或无法通过查询派生实现时,则需要提供自定义实现。 Spring Data存储库允许您提供自定义存储库代码,并将其与通用CRUD抽象和查询方法功能集成。
-
1.6.1 Customizing Individual Repositories(自定义个人存储库)
-
要使用自定义功能丰富存储库,必须首先定义片段接口和自定义功能的实现,如以下示例所示:
-
ex: Interface for custom repository functionality(用于自定义存储库功能的接口)
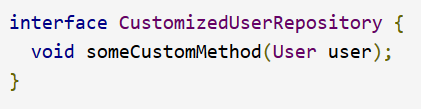
-
然后可以让存储库接口从fragment接口扩展,如下面的示例所示
-
ex: Implementation of custom repository functionality(自定义存储库功能的实现)

-
类名中与fragment接口对应的最重要部分是Impl后缀。
-
实现本身不依赖于Spring Data,可以是常规的Spring bean。 因此,您可以使用标准依赖项注入行为来注入对其他bean(例如JdbcTemplate)的引用,参与方面等。
-
您可以让存储库接口扩展fragment接口,如下面的示例所示
-
*ex:*Changes to your repository interface(更改存储库接口)

-
使用存储库接口扩展fragment接口结合了CRUD和自定义功能,并使其对客户端可用。
-
Spring Data存储库通过使用形成存储库组合的片段来实现。 片段是基本存储库,功能方面(如QueryDsl),自定义接口及其实现。 每次向存储库界面添加接口时,都可以通过添加片段来增强组合。 每个Spring Data模块都提供了基本存储库和存储库方面的实现。
-
下面的示例显示了自定义接口及其实现
-
ex: Fragments with their implementations

-
下面的示例显示了扩展CrudRepository的自定义存储库的接口
-
ex: Changes to your repository interface(更改存储库接口)

-
存储库可以由多个自定义实现组成,这些实现按其声明的顺序导入。 自定义实现的优先级高于基本实现和存储库方面。 如果两个片段提供相同的方法签名,则此排序允许您覆盖基本存储库和方面方法并解决歧义。 存储库片段不限于在单个存储库接口中使用。 多个存储库可以使用片段接口,允许您跨不同的存储库重用自定义。
-
下面的示例显示了存储库片段及其实现
-
ex: Fragments overriding save(…)

-
下面的示例显示了一个使用前面的存储库片段的存储库
-
*ex:*Customized repository interfaces

- 如果使用命名空间配置,则存储库基础结构会尝试通过扫描其找到存储库的包下面的类来自动检测自定义实现片段。 这些类需要遵循将命名空间元素的repository-impl-postfix属性附加到片段接口名称的命名约定。 此后缀默认为Impl。 以下示例显示了使用默认后缀的存储库以及为后缀设置自定义值的存储库:
- *ex:*Configuration example

- 前面示例中的第一个配置尝试查找一个名为com.acme.repository的类。CustomizedUserRepositoryImpl作为自定义存储库实现。第二个示例尝试查找com.acme.repository.CustomizedUserRepositoryMyPostfix。
- 如果在不同的包中找到具有匹配类名的多个实现,则Spring Data使用给定前面显示的CustomizedUserRepository的以下两个自定义实现,使用第一个实现。 它的bean名称是customizedUserRepositoryImpl,它与片段接口(CustomizedUserRepository)和后缀Impl的名称相匹配。bean名称来标识要使用的名称
- 给定前面显示的CustomizedUserRepository的以下两个自定义实现,使用第一个实现。 它的bean名称是customizedUserRepositoryImpl,它与片段接口(CustomizedUserRepository)和后缀Impl的名称相匹配。
- ex: Resolution of amibiguous implementations


- 如果使用@Component(“specialCustom”)注释UserRepository接口,则bean名称加上Impl将匹配为com.acme.impl.two中的存储库实现定义的名称,并使用它而不是第一个。
- 如果您的自定义实现仅使用基于注释的配置和自动装配,则前面显示的方法效果很好,因为它被视为任何其他Spring bean。 如果您的实现片段bean需要特殊连接,您可以声明bean并根据前一节中描述的约定命名它。 然后,基础结构按名称引用手动定义的bean定义,而不是自己创建一个。 以下示例显示如何手动连接自定义实现:
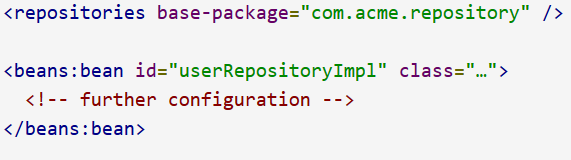
- ex: Manual wiring of custom implementations
- 1.6.2 Customize the Base Repository
- 当您要自定义基本存储库行为以便所有存储库都受到影响时,上一节中描述的方法需要自定义每个存储库接口。 要改为更改所有存储库的行为,可以创建一个扩展特定于持久性技术的存储库基类的实现。 然后,此类充当存储库代理的自定义基类,如以下示例所示:
- *ex:*Custom repository base class

- 该类需要具有特定于存储库工厂实现使用的超类的构造函数。如果存储库基类有多个构造函数,则覆盖一个包含EntityInformation和一个特定于存储库的基础设施对象(如EntityManager或模板类)的构造函数。
- 最后一步是使Spring Data Infrastructure了解自定义存储库基类。 在Java配置中,您可以使用@ Enable $ {store}存储库注释的repositoryBaseClass属性来执行此操作,如以下示例所示:
- ex: Configuring a custom repository base class using JavaConfig(使用JavaConfig配置自定义存储库基类)
 A corresponding attribute is available in the XML namespace, as shown in the following example:
A corresponding attribute is available in the XML namespace, as shown in the following example: - XML名称空间中有一个对应的属性,如下面的示例所示
- ex: Configuring a custom repository base class using XML(使用XML配置自定义存储库基类)
