一、前言
前面已经学习了Lucene的分词、索引详解、搜索详解的知识,已经知道开发一个搜索引擎的流程了。现在就会有这样的一个问题:如果其他的系统也需要使用开发的搜索引擎怎么办呢?这个时候就需要把开发的搜索引擎封装成一个组件或者独立成一个单独的服务给其他系统使用了。目前市面上已经有基于Lucene的成熟的稳定的搜索引擎服务,例如Solr和ElasticSearch,如果没有特殊需求我们就可以直接拿过来使用,不需要自己再取开发一套了。下面我们就来介绍一下Solr。
二、Solr介绍
1. Solr是什么
基于Lucene的流行、高性能的开源企业级搜索平台。Lucene下的子项目。 官网链接: https://lucene.apache.org/solr
2. Solr的用途
独立地提供全文搜索服务
3. Solr的特性
3.1、独立的企业级搜索服务,基于http以类-REST API 对外提供服务
你可以通过http协议将文档以JSON/XML/CSV/binary格式发送给Solr进行索引。
你通过http GET 请求进行查询,可返回JSON/XML/CSV/binary格式的搜索结果。
3.2、近实时的索引能力
文档数据提交索引后,立马就可看到。
3.3、先进的全文检索能力
基于Lucene的强大搜索能力,支持任意数据类型的短语、通配、连接、分组等等查询
3.4、综合的管理界面
Slor内建了综合的管理用户界面,让你方便的管理你的solr实例
3.5、通过简单的配置方式来提供高灵活性、适用性
3.6、高伸缩和容错能力
基于zookeeper,solr支持分布式、备份、再平衡,来提供高伸缩和容错能力
3.7、插件体系架构,易扩展
Solr发布了许多定义良好的扩展点,这使得插件很容易插入索引和查询时的过程中。
三、Solr应用架构
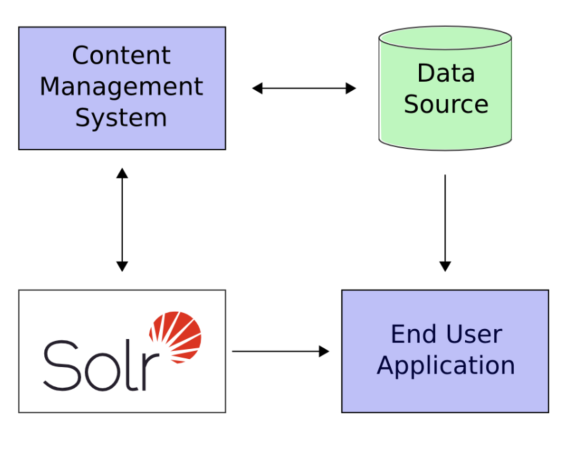
要在系统中使用Solr只需完成以下三个步骤即可:
1、在solr中定义一个schema(模式),来告诉solr你要索引的文档document由哪些Field构成。
2、将需要让用户搜索的文档发送给solr
3、在你的应用中公开搜索功能。应用的搜索功能通过调用Solr的搜索API实现。
四、Solr安装、使用
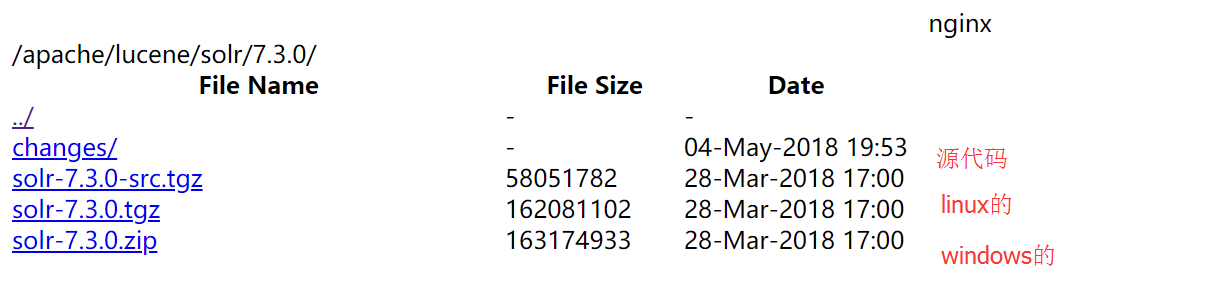
1. Solr 下载
从官网下载最新版本http://mirrors.hust.edu.cn/apache/lucene/solr/7.3.0/
这里下载的windows版本的
2. 系统环境要求
JDK1.8
操作系统:Linux, MacOS/OS X, and Microsoft Windows
3. 安装准备
Solr的安装很简单,只需解压到安装目录。但在安装之前针对你的使用环境:开发、测试、生产,需要进行一个评估,来决定是在独立的机器上部署单应用服务; 还是需要分布式集群。
特别是在生产环境部署时,需认真评估需要的服务规模。考量因素:
文档的数量、结构
要存储的字段数量
用户数量
影响硬件规模的因素
Lucene的严格限制: 单个索引中的最大文档数: 约2.14 billion documents (约21.4亿,2,147,483,647 )
实际中不可能在单个索引中达到这个文档数量级还运行良好,在到达这个数量之前早就会用分布式索引集群。如果在部署时,就能估计出将达到如此量级,就应该用solrCloud分布式集群方式安装。
4. 安装
将安装包解压到安装目录即可。
Linux系统下解压命令: tar zxf solr-7.3.0.tgz
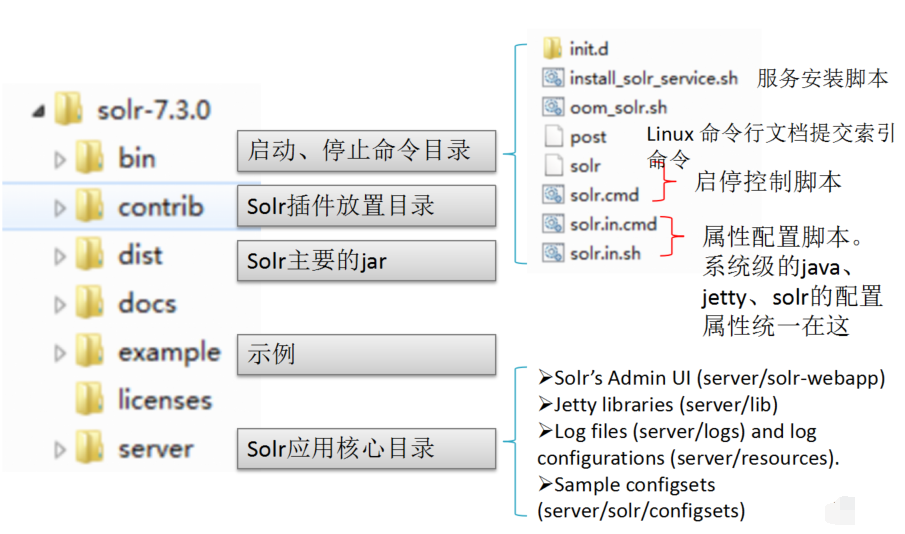
Solr目录说明:
5. 独立服务器模式启动Solr
Linux: bin/solr start
Windows: bin\solr.cmd start
默认端口: 8983
查看Solr是否在运行的命令: bin/solr status
6. solr的相关命令
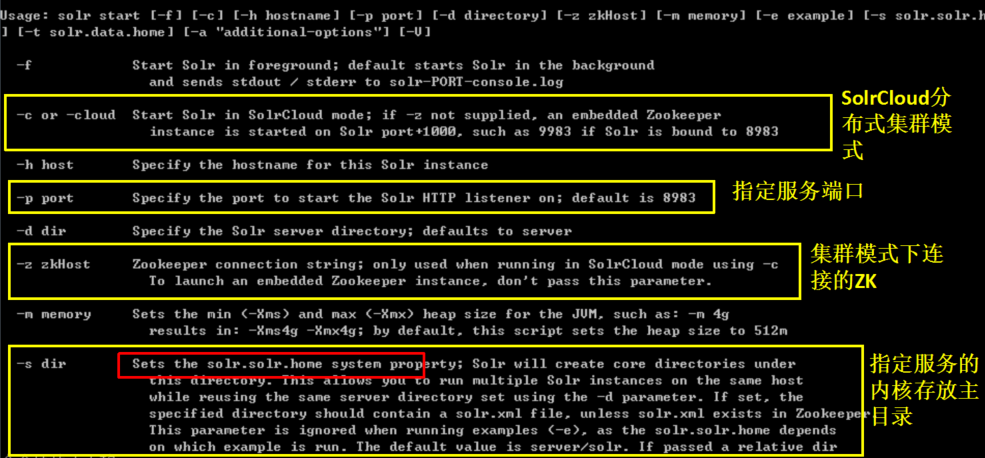
在命令行下,直接 solr.cmd 回车,查看命令的使用帮助说明
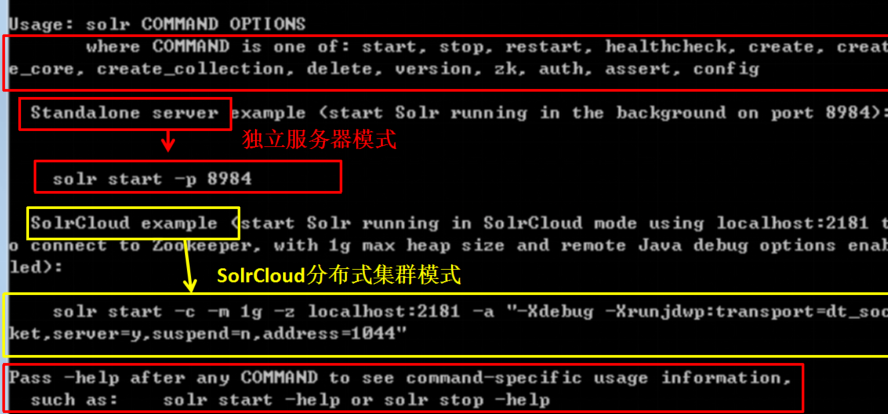
输入 solr.cmd start –help 详细了解它的选项
7. Solr 管理控制台介绍
http://localhost:8983/solr/
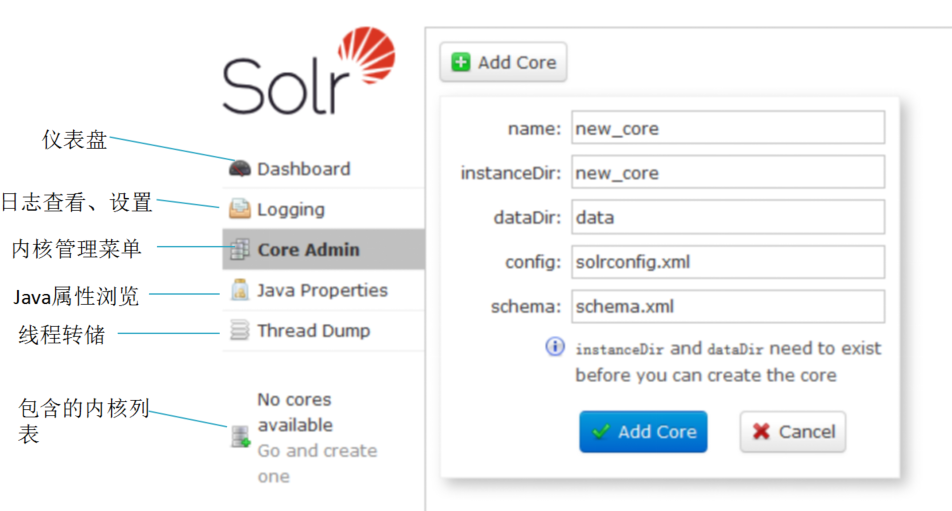
8. Solr core 介绍
内核:是运行在Solr服务器中的具体唯一命名的、可管理和可配置的索引。
一台solr服务器可以托管一个或多个内核。
疑问:内核就是索引,为什么需要多个内核?
答案:不同的文档拥有不同的模式(字段构成、索引、存储方式),如商品数据和新闻数据就有不同的字段构成以及不同的字段索引、存储方式。就需要分别用两个内核来索引、存储它们。
内核的典型用途:区分不同模式的文档
9. 创建内核
方式一:web管理控制台加载已存在的内核
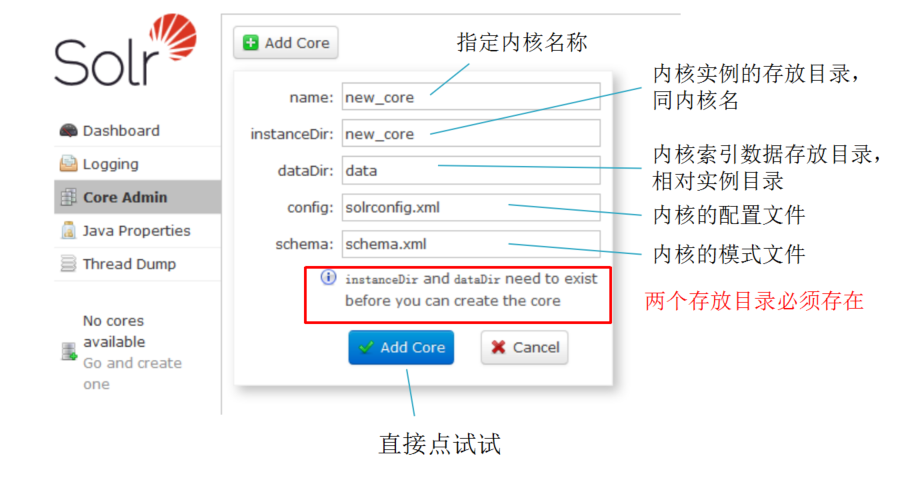
方式二:命令行命令创建一个新的内核
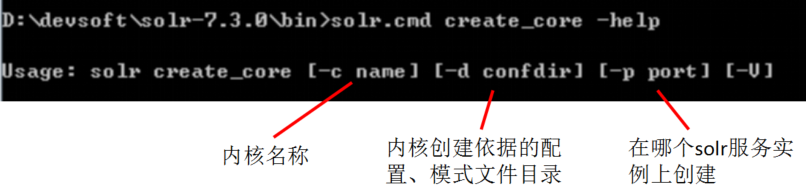
-d 选项可选值有两个:
_default 默认值,最少配置;
sample_techproducts_cnofigs 示例的配置
分别用它们创建一个内核:
solr.cmd create_core –c mycore
solr.cmd create_core -c techproducts –d sample_techproducts_configs
10. 在web管理控制台查看创建的内核
核心有了,但它是空的,搞点数据进去,来试试搜索吧
在solr的example目录下有不少示例数据。把它们搞进去:
用post命令:
Linux/Mac solr-7.3.0:$ bin/post -c techproducts example/exampledocs/*
Windows solr-7.3.0> java -jar -Dc=techproducts -Dauto example\exampledocs\post.jar example\exampledocs\*
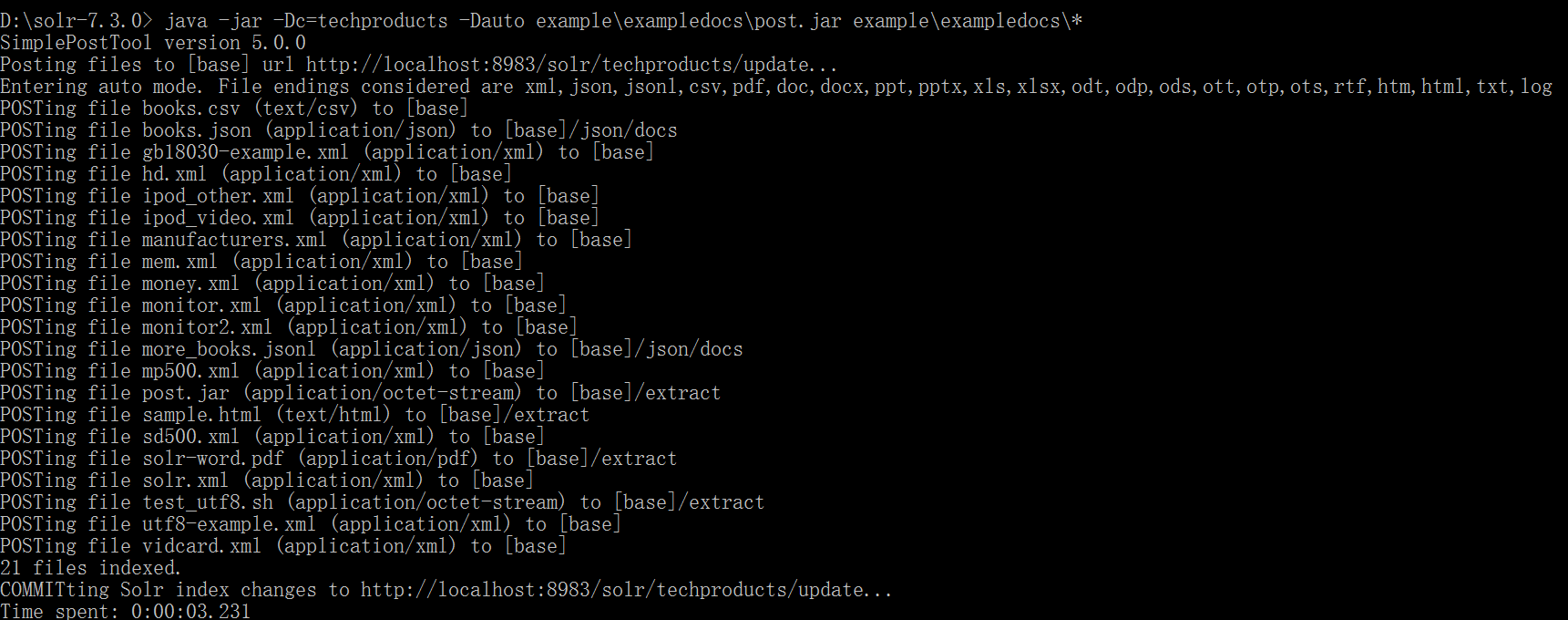
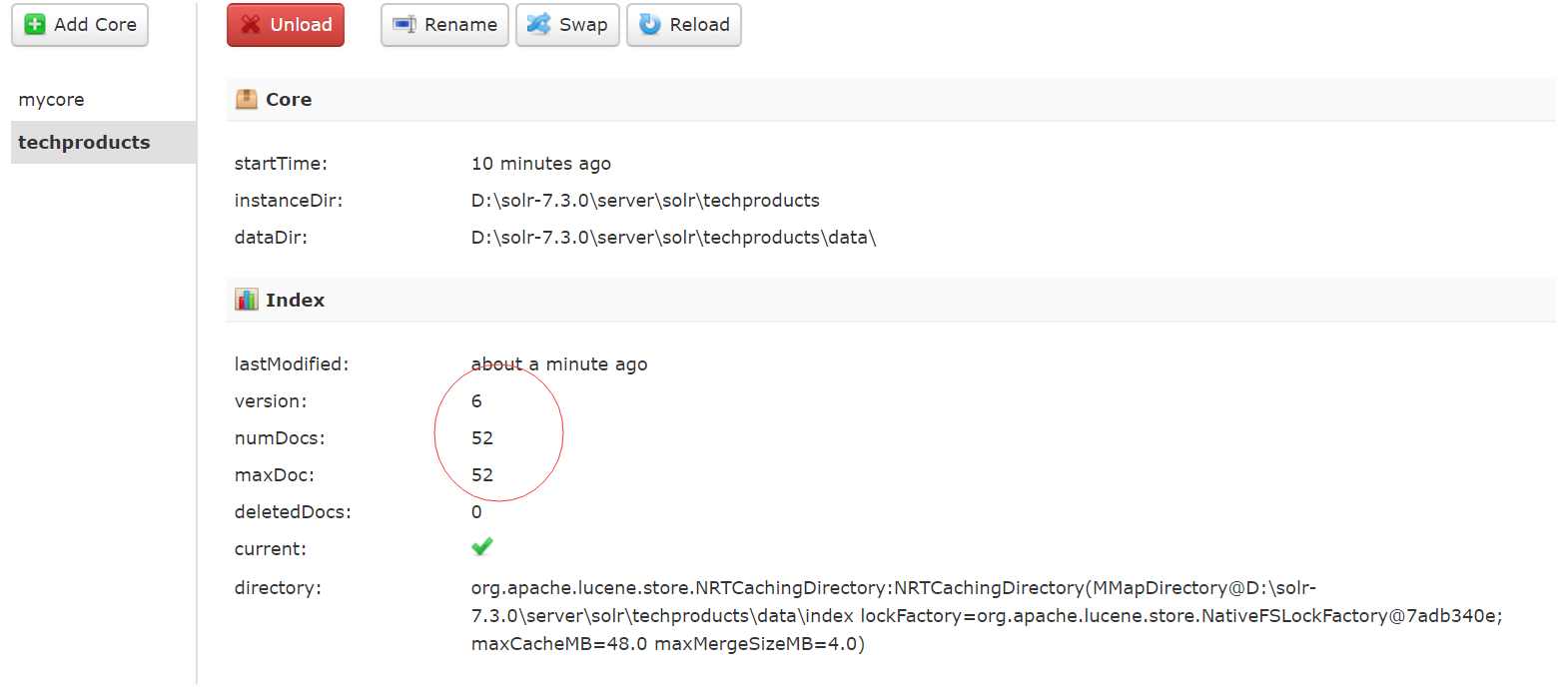
请注意看它的输出信息!然后到web管理控制台,看下 techproducts核心有多少个文档。试试搜索!
11. 在左侧菜单切换搜索试一下

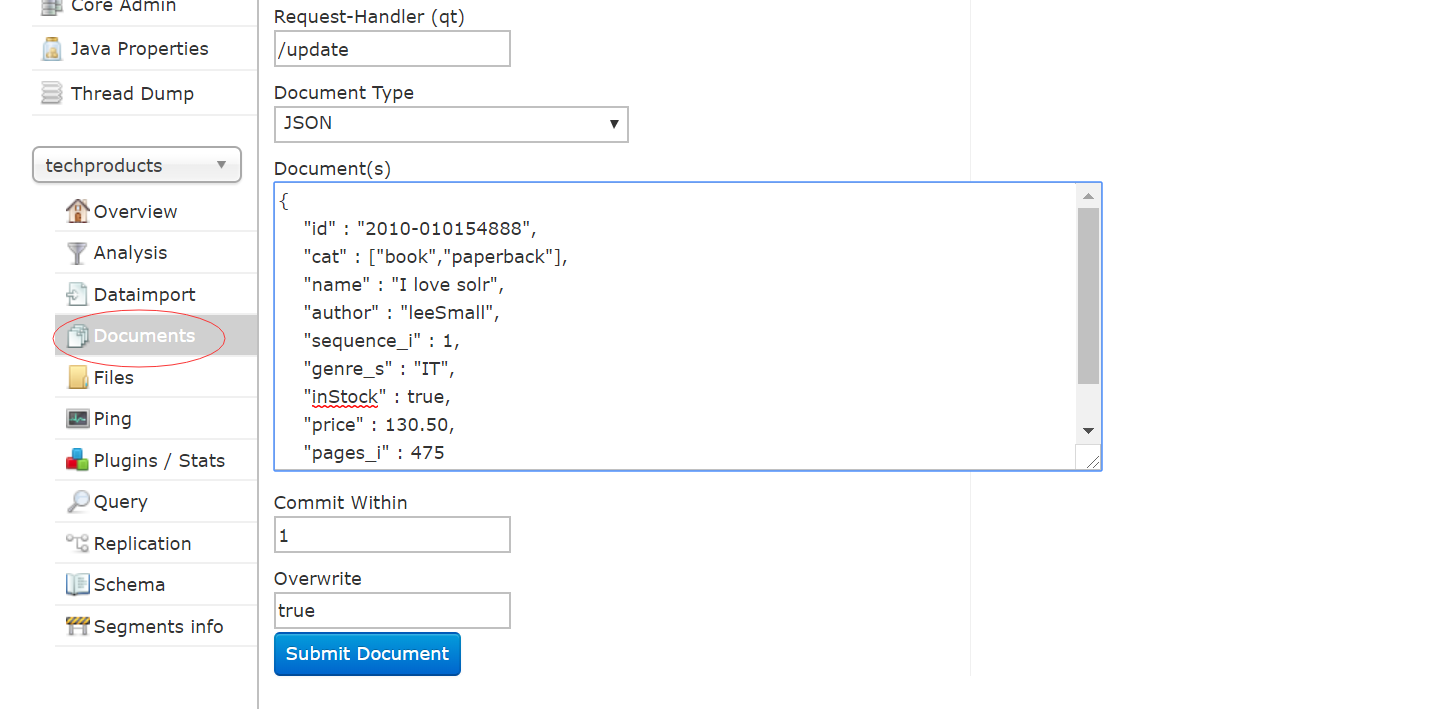
12. 提交一个文档
{ "id" : "2010-010154888", "cat" : ["book","paperback"], "name" : "I love solr", "author" : "leeSmall", "sequence_i" : 1, "genre_s" : "IT", "inStock" : true, "price" : 130.50, "pages_i" : 475 }
14. 我们的系统如何使用Solr?
通过http请求向solr提交查询数据