Redis课程教案
1、 NoSQL数据库的发展历史简介
1、web系统的变迁历史

web1.0时代简介
基本上就是一些简单的静态页面的渲染,不会涉及到太多的复杂业务逻辑,功能简单单一,基本上服务器性能不会有太大压力
缺点:1、Service 越来越多,调用关系变复杂,前端搭建本地环境不再是一件简单的事。考虑团队协作,往往会考虑搭建集中式的开发服务器来解决。这种解决方案对编译型的后端开发来说也许还好,但对前端开发来说并不友好。天哪,我只是想调整下按钮样式,却要本地开发、代码上传、验证生效等好几个步骤。也许习惯了也还好,但开发服务器总是不那么稳定,出问题时往往需要依赖后端开发搞定。看似仅仅是前端开发难以本地化,但这对研发效率的影响其实蛮大。
2、JSP 等代码的可维护性越来越差。JSP 非常强大,可以内嵌 Java 代码。这种强大使得前后端的职责不清晰,JSP 变成了一个灰色地带。经常为了赶项目,为了各种紧急需求,会在 JSP 里揉杂大量业务代码。积攒到一定阶段时,往往会带来大量维护成本。
web2.0时代简介
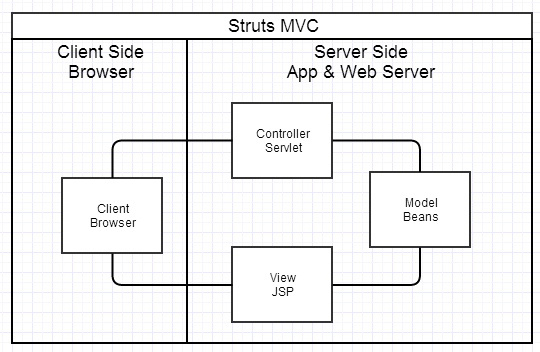
随着Web2.0的时代的到来,用户访问量大幅度提升,同时产生了大量的用户数据。加上后来的智能移动设备的普及,所有的互联网平台都面临了巨大的性能挑战。包括web服务器CPU及内存压力。数据库服务器IO压力等
为了解决服务器的性能压力问题,出现了各种各样的解决方案,最典型的就是使用MVC的架构,MVC 是个非常好的协作模式,从架构层面让开发者懂得什么代码应该写在什么地方。为了让 View 层更简单干脆,还可以选择 Velocity、Freemaker 等模板,使得模板里写不了 Java 代码。看起来是功能变弱了,但正是这种限制使得前后端分工更清晰。但是同样也会面临以下问题
1、前端开发重度依赖开发环境。这种架构下,前后端协作有两种模式:一种是前端写 demo,写好后,让后端去套模板。淘宝早期包括现在依旧有大量业务线是这种模式。好处很明显,demo 可以本地开发,很高效。不足是还需要后端套模板,有可能套错,套完后还需要前端确定,来回沟通调整的成本比较大。另一种协作模式是前端负责浏览器端的所有开发和服务器端的 View 层模板开发,支付宝是这种模式。好处是 UI 相关的代码都是前端去写就好,后端不用太关注,不足就是前端开发重度绑定后端环境,环境成为影响前端开发效率的重要因素。
2、前后端职责依旧纠缠不清。Velocity 模板还是蛮强大的,变量、逻辑、宏等特性,依旧可以通过拿到的上下文变量来实现各种业务逻辑。这样,只要前端弱势一点,往往就会被后端要求在模板层写出不少业务代码。还有一个很大的灰色地带是 Controller,页面路由等功能本应该是前端最关注的,但却是由后端来实现。Controller 本身与 Model 往往也会纠缠不清,看了让人咬牙的代码经常会出现在 Controller 层。这些问题不能全归结于程序员的素养,否则 JSP 就够了。
关于如何解决Web服务器的负载压力,其中最常用的一种方式就是使用nginx实现web集群的服务转发以及服务拆分等等
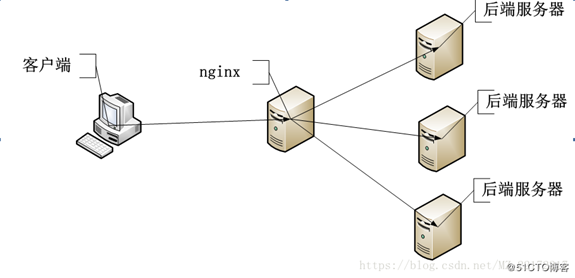
但是这样也会存在问题,后端服务器的多个tomcat之间如何解决session共享的问题,以及session存放的问题等等
为了解决session存放的问题,也有多种解决方案
方案一:存放在cookie里面。不安全,否定
方案二:存放在文件或者数据库当中。速度慢
方案三:session复制。大量session冗余,节点浪费大
方案四:使用NoSQL缓存数据库。例如redis或者memcache等,完美解决
NoSQL适用场景
- 对数据高并发的读写
- 海量数据的读写
- 对数据高可扩展性的
- 速度够快,能够快速的存取数据
NoSQL不适用场景
- 需要事务支持
- 基于sql的结构化查询存储,处理复杂的关系,需要即席查询(用户自定义查询条件的查询)。
总结:用不着sql的和用了sql也不行的情况,请考虑用NoSql
2、 NoSQL数据库兄弟会
1、memcache介绍
- 很早出现的NoSql数据库
- 数据都在内存中,一般不持久化
- 支持简单的key-value模式
- 一般是作为缓存数据库辅助持久化的数据库
- 几乎覆盖了Memcached的绝大部分功能
- 数据都在内存中,支持持久化,主要用作备份恢复
- 除了支持简单的key-value模式,还支持多种数据结构的存储,比如 list、set、hash、zset等。
- 一般是作为缓存数据库辅助持久化的数据库
- 现在市面上用得非常多的一款内存数据库
- 高性能、开源、模式自由(schema free)的文档型数据库
- 数据都在内存中, 如果内存不足,把不常用的数据保存到硬盘
- 虽然是key-value模式,但是对value(尤其是json)提供了丰富的查询功能
- 支持二进制数据及大型对象
- 可以根据数据的特点替代RDBMS ,成为独立的数据库。或者配合RDBMS,存储特定的数据。
- HBase是Hadoop项目中的数据库。它用于需要对大量的数据进行随机、实时的读写操作的场景中。HBase的目标就是处理数据量非常庞大的表,可以用普通的计算机处理超过10亿行数据,还可处理有数百万列元素的数据表。
2、redis介绍
3、mongoDB介绍
4、列式存储HBase介绍
3、 Redis的基本介绍以及使用场景
redis官网地址:
中文网站
3.1、redis的基本介绍
Redis是当前比较热门的NOSQL系统之一,它是一个开源的使用ANSI c语言编写的key-value存储系统(区别于MySQL的二维表格的形式存储。)。和Memcache类似,但很大程度补偿了Memcache的不足。和Memcache一样,Redis数据都是缓存在计算机内存中,不同的是,Memcache只能将数据缓存到内存中,无法自动定期写入硬盘,这就表示,一断电或重启,内存清空,数据丢失。所以Memcache的应用场景适用于缓存无需持久化的数据。而Redis不同的是它会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,实现数据的持久化
3.2、redis的适用场景
1.取最新N个数据的操作
比如典型的取你网站的最新文章,通过下面方式,我们可以将最新的5000条评论的ID放在Redis的List集合中,并将超出集合部分从数据库获取
- 使用LPUSH latest.comments<ID>命令,向list集合中插入数据
- 插入完成后再用LTRIM latest.comments 0 5000命令使其永远只保存最近5000个ID
- 然后我们在客户端获取某一页评论时可以用下面的逻辑(伪代码)
FUNCTION get_latest_comments(start,num_items):
id_list = redis.lrange("latest.comments",start,start+num_items-1)
IF id_list.length < num_items
id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
END
RETURN id_list
END
如果你还有不同的筛选维度,比如某个分类的最新N条,那么你可以再建一个按此分类的List,只存ID的话,Redis是非常高效的。
2.排行榜应用,取TOP N操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
3.需要精准设定过期时间的应用
比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
4.计数器应用
Redis的命令都是原子性的,你可以轻松地利用INCR,DECR命令来构建计数器系统。
5.Uniq操作,获取某段时间所有数据排重值
这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
6.实时系统,反垃圾系统
通过上面说到的set功能,你可以知道一个终端用户是否进行了某个操作,可以找到其操作的集合并进行分析统计对比等。没有做不到,只有想不到。
7.Pub/Sub构建实时消息系统
Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天系统的例子。
8.构建队列系统
使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。
9.缓存
将数据直接存放到内存中,性能优于Memcached,数据结构更多样化。
3.3、redis的特点
高效性:Redis读取的速度是110000次/s,写的速度是81000次/s
原子性:Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
支持多种数据结构:string(字符串);list(列表);hash(哈希),set(集合);zset(有序集合)
稳定性:持久化,主从复制(集群)
其他特性:支持过期时间,支持事务,消息订阅。