今天主要学习了集合的相关知识,同样,在新内容的开始之前,来先复习下我们昨天学习的知识。
1.小数据池:
1.小数据池: 小数据池是针对 str 和 int 所有的 int : -5 ~ 256 str :特殊字符,乘以数字不能超过20
2.编码:
2.编码:位,字节,字符 1)ASCII码:8位一个字节,表示一个字符。 2)Unicode码:32位四个字节,表示一个字符。 3)Utf-8:英文用8位1个字节,表示一个字符;中文用24位3个字节,表示一个字符;欧洲用16位2个字节,表示一个字符 4)Gbk: 英文用8位一个字节,表示一个字符;中文用16位两个字节,表示一个字符 字节和字符的区别: 字节是一个单位,8位表示一个字节。而字符是一个你看到的组成这个东西的最小元素(最小单位) Python3X 中 str 存储内部的编码方式是:Unicode Python3X 中 储存传输的字符串必须的编码方式 :UTF-8 所以必须将字符串转成bytes类型,因为bytes的编码方式是 Utf -8 eg. str = '123' b = str.encode('utf-8') # encode():是编码的意思 print(b) # b'123'
3.基础数据类型的补充:
str: 1.isspace() : 用来判断字符串是否存在空格,有一个或多个空格就是True,没有空格就是False。字符串空格和字符在一起,仍然是False 从 list: lis = [11,22,33,44,55] """ # eg.1 # s = '123' # s1 = s.isspace() # print(s1) # print('--------------') # m = '12 ' # m1 = m.isspace() # print(m1) #删除奇数的索引下标的值 #1. # lis = [11,22,33,44,55] # new = [] # for i in range(len(lis)): # if i % 2 == 0: # new.append(lis[i]) # else: # continue # print(new) #2. # lis = [11,22,33,44,55] # new = lis[0::2] # print(new) # 注意: # # 字典和列表,在循环列表和字典中,不要删除他们里面的东西,删了容易报错,删除时要特别注意,(他们随之改变的索引下标) #注意: #元祖里面只有一个元素,不加逗号,该是什么类型就是什么类型。加上逗号就都是元祖类型
说完小数据池,编码和基础数据类型补充的问题,下面我们来介绍集合。
首先是集合的定义:
集合:
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。
一下是集合最重要的两点:
去重:把一个列表变成集合,就自动去重了。
关系测试:测试两组数据之前的交集,差集,并集等关系
集合的两种创建方法:
集合的两种创建方式: set1 = set({1,2,3}) print(set1) set2 = {1,2,'3',True} print(set2)
从集合的增加,删除和查找,这3个方面介绍集合,集合的方法的使用
1.增加: 1)add(): 给集合加一个元素,('元素值')。 2)update(): ('元素值'),元素值会被遍历的添加,eg. 'ab' -> 'a','b' eg. setl = {1,2,3,4} setl.add('56') print(setl) setl.update('78') print(setl) 2.删除: 1)pop():随机删除,有返回值的。 2)remove(): 按照元素进行删除,元素如果不在集合里,会报错 3)clear(): 清空集合,set()表示空集合 4)del set : 删除整个集合 eg. setl = {1,2,3,4,'alex','boy'} setl.pop() print(setl) setl.remove('boy') print(setl) setl.clear() print(setl) del setl print(setl) 3.查找: for循环遍历 eg. for i in setl: print(i)
然后我们从集合的交集,并集,差集.....等方面来拓展集合:
1.交集;(求出公共的部分) 1)set1 & set2 2)intersection() 2.并集:(将所有元素都放在一起) 1)set1 | set2 2)union() 3.反交集:(将两个不相等的元素放在一起) 1)set1 ^ set2 2)symmetric_difference() 4.差集:set1独有的(左边独有的) 1)set1 - set2 2)difference() 5.子集: 1)set1 < set2 (set1中的元素set2全部包含,set1是set2的子集,返回的是Bool值) 2)issubset() 6.超集: 1)set2 > set1 (set2 是 set1 的超集) 2)issuperset()
下面我们开始介绍一个集合相对来说,比较重要的知识点:集合的去重:
去重: li = [1,2,33,44,33,2,1,4,5,6,6] set1 = set(li) list1 = list(set1) print(list1)
我们通过将列表转化成集合,来去掉列表中重复的元素,再将集合转化成列表,然后打印出来。最终实现了去重的效果。
在集合中,集合中的元素是不可变数据类型,而集合是可变数据类型,在Python中出现不可变集合,下面我们来看一下。
不可变数据类型: frozenset:不可变集合 eg. set1 = frozenset('deng') #是一种随机遍历添加 print(set1,type(set1))
下面我们面临一个最后的问题,深浅copy:
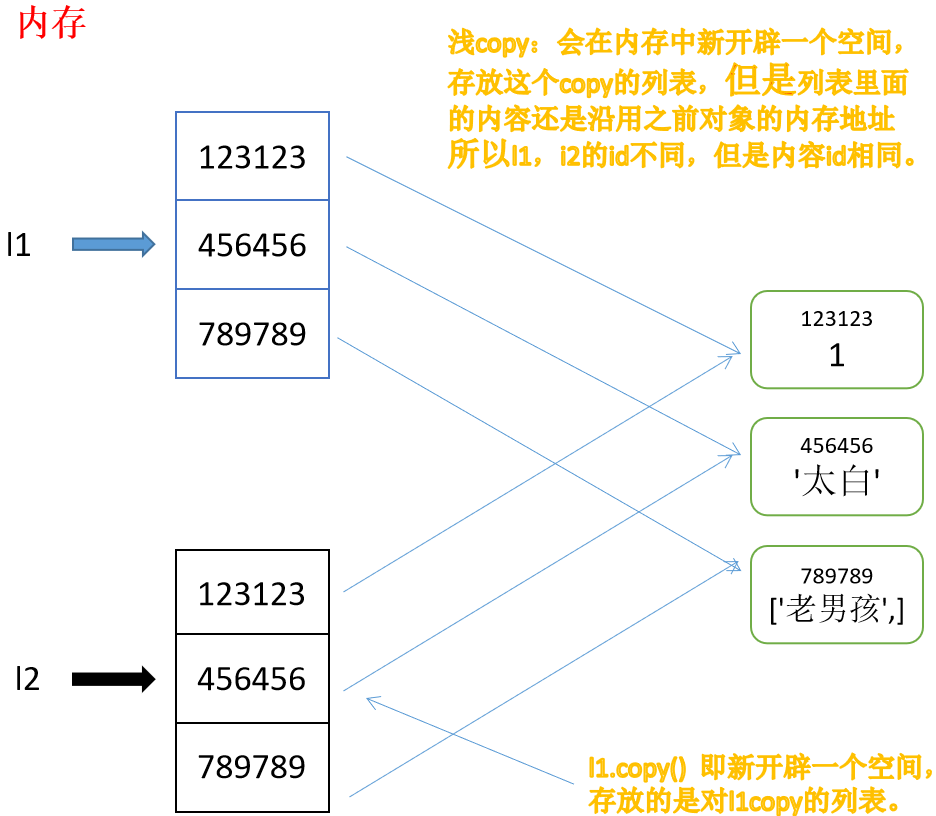
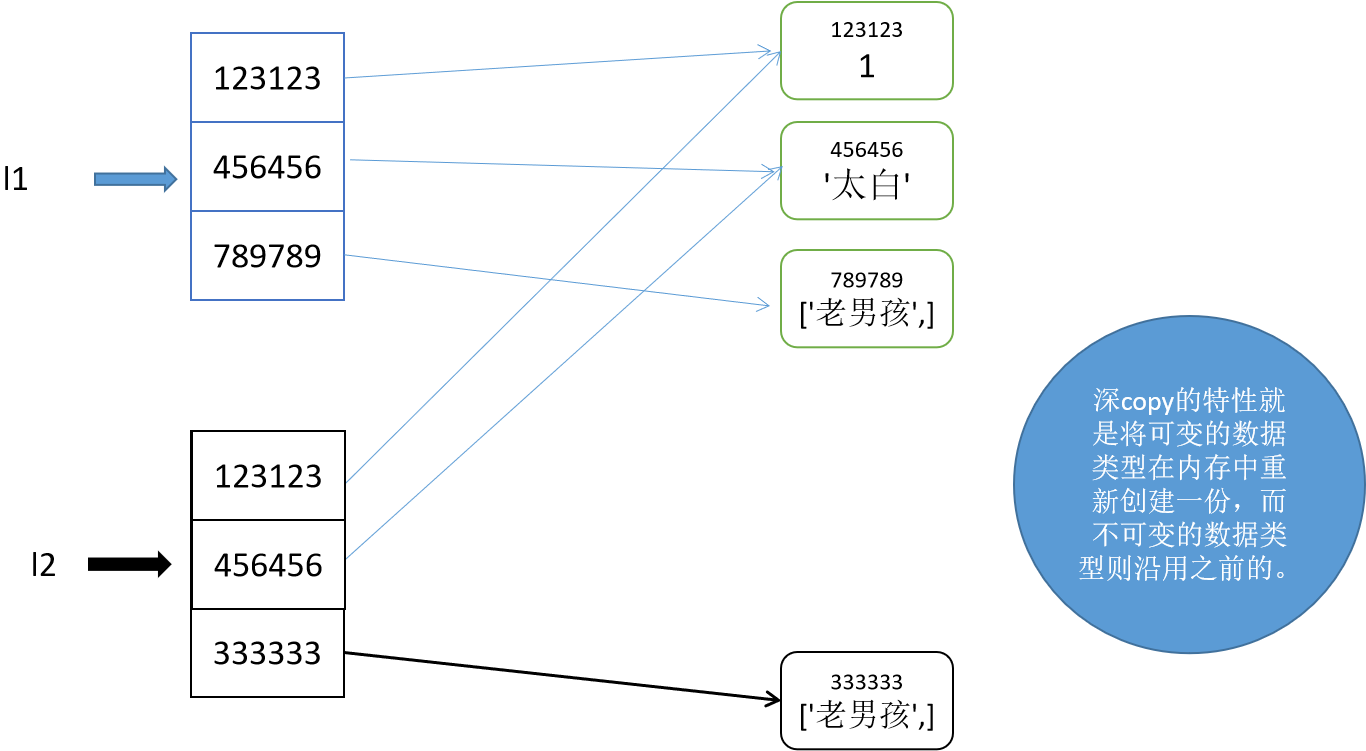
深浅copy: 1.浅copy:copy() 对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与 原列表中的元素是公用的。 也就是说,会在内存中新开辟一个空间,存放这个copy的列表,但是列表里面的内容还是沿用之前对 象的内存地址,所以id不同,但是内容id相同。 eg. l2 = li.copy() 2.深copy:deepcopy() 深copy的特性就是将可变的数据类型在内存中重新创建一份,而不可变的数据类型则延用之前的。 对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的 不可变的数据类型是公用的。