1.flume简介
是分布式日志收集系统,用于高效收集、汇聚和移动大规模日志信息从多种不同的数据源到一个集中的数据存储中心(HDFS HBASE)
多种数据源:console、RPC、Text 、Tail、syslog等
2.log4j直接输出到flume-flume配置:
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.channels=c1
a1.sinks=k1
#configure the source
a1.sources.r1.type=avro
a1.sources.r1.bind=master
a1.sources.r1.port=4444
a1.sources.r1.type=avro
a1.sources.r1.bind=master
a1.sources.r1.port=4444
#configure the sink
a1.sinks.k1.type=file_roll
a1.sinks.k1.type=file_roll
#配置日志输出的位置,若tmpData不存在需要先创建,否则报错
a1.sinks.k1.sink.directory=/home/hzs/software/hadoop/flume/apache-flume-1.7.0-bin/tmpData
a1.sinks.k1.sink.rollInterval=86400
a1.sinks.k1.sink.batchSize=100
a1.sinks.k1.sink.serializer=text
a1.sinks.k1.sink.serializer.appendNewline=false
a1.sinks.k1.sink.directory=/home/hzs/software/hadoop/flume/apache-flume-1.7.0-bin/tmpData
a1.sinks.k1.sink.rollInterval=86400
a1.sinks.k1.sink.batchSize=100
a1.sinks.k1.sink.serializer=text
a1.sinks.k1.sink.serializer.appendNewline=false
#configure channal
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#bind source and sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
3.在idea新建一个java项目
-目录结构

log4j配置:
log4j.rootLogger=
INFO,flume
log4j.appender.console=
org.apache.log4j.ConsoleAppender
log4j.appender.console.target=
System.out
log4j.appender.console.layout=
org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=
"%d{yyyy-MM-dd HH:mm:ss} %p [%c:%L] - %m%n
log4j.appender.flume =
org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname =
master //已在host文件配置 master ip的映射关系
log4j.appender.flume.Port =
4444
log4j.appender.flume.UnsafeMode=
true
log4j.appender.flume.layout=
org.apache.log4j.PatternLayout
log4j.appender.flume.layout.ConversionPattern=
%d{yyyy-MM-dd HH:mm:ss} %p [%c:%L] - %m%n
java测试类
public class WriteLog {
protected static final Log
logger = LogFactory.
getLog(WriteLog.
class);
/**
*
@param
args
*
@throws
InterruptedException
*/
public static void main(String[] args)
throws InterruptedException {
//
TODO Auto-generated method stub
while (
true)
{
//
logger.info(
new Date().getTime()); Thread.
sleep(
20);
}
}
}
4.启动flume并跑测试类
启动flume:
bin/flume-ng agent -c conf -f conf/flume_log4j.conf --name a1 -Dflume.root.logger=INFO,console
跑java测试类 并查看flume输出日志目录可看到

源码下载:http://download.csdn.net/download/hzs33/10267525
上述例子是将flume收集的文件放在本地目录里面,也可以放在hdfs上,flume配置如下:
a1.sources=r1 a1.channels=c1 a1.sinks=k1 #configure the source a1.sources.r1.type=avro a1.sources.r1.bind=master a1.sources.r1.port=4444 #configure the sink a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=hdfs://master:9000/user/root/log4_hdfs_test a1.sinks.k1.hdfs.writeFormat=Text a1.sinks.k1.hdfs.fileType=DataStream #设置hdfs超时时长 a1.sinks.k1.hdfs.callTimeout=72000000 #设置使用当前时间错 a1.sinks.k1.hdfs.useLocalTimeStamp=true #当文件大小为52428800字节时,为临时文件滚动一个目标文件 a1.sinks.k1.hdfs.rollSize=52428800 #events数据达到该数量的时候,将临时文件滚动为目标文件 a1.sinks.k1.hdfs.rollCount=0 #每隔1200s将临时文件滚动成一个目标文件 a1.sinks.k1.hdfs.rollInterval=1200 #配置前缀后缀 a1.sinks.k1.hdfs.filePrefix=run #configure channal a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=1000 #bind source and sink a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1
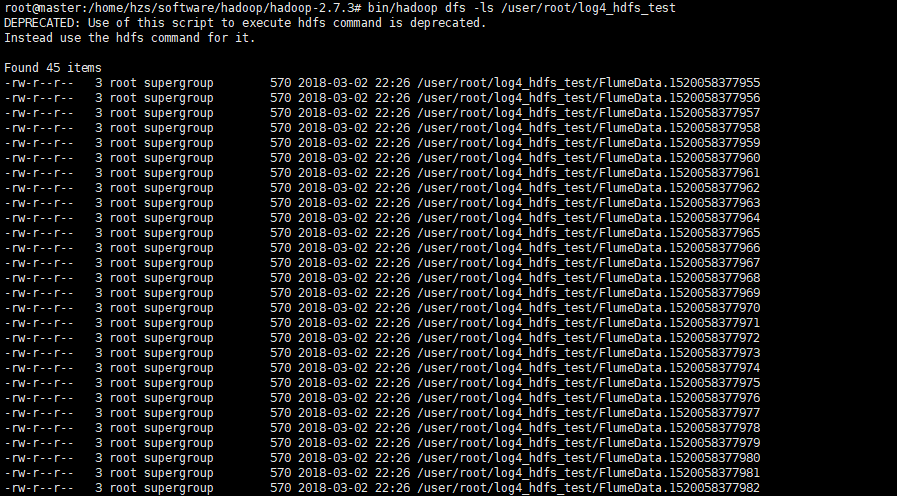
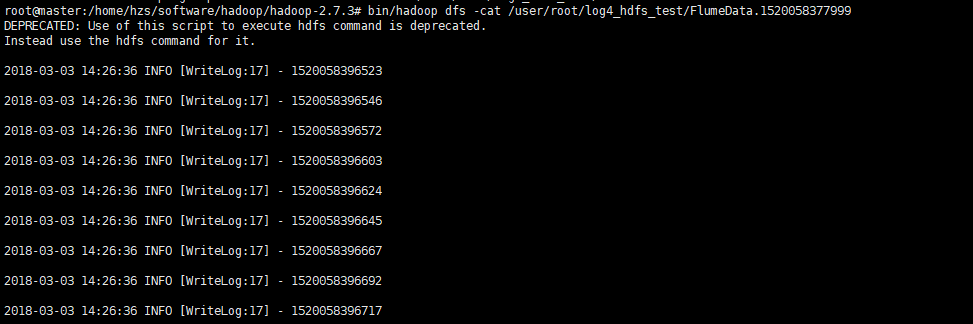
java代码无需修改,运行测试类,查看hdfs如下即成功:
若出现连接hdfs超时的错误,请把a1.sinks.k1.hdfs.callTimeout参数设置大一点