目录
一、Flink 容错机制概述
Flink 中的每个函数和运算符都可以是有状态的。有状态功能在处理单个元素/事件的过程中存储数据,使状态成为任何类型的更复杂操作的关键构建块。为了使状态容错,Flink 需要检查点状态。检查点允许 Flink 恢复流中的状态和位置,从而为应用程序提供与无故障执行相同的语义。
1.1 先决条件
Flink的检查点机制与流和状态的持久存储交互。通常,它要求:
- 一个持久(或耐用,可以重放记录在一定量的时间)的数据源。此类消息源的示例是持久消息队列(例如,Apache Kafka,RabbitMQ,Amazon Kinesis,Google PubSub)或文件系统(例如,HDFS,S3,GFS,NFS,Ceph等)。
- 状态的持久性存储,通常是分布式文件系统(例如,HDFS,S3,GFS,NFS,Ceph等)
二、Flink CheckPoint 核心组成
If you want to use keyed state, you first need to specify a key on a DataStream that should be used to partition the state (and also the records in the stream themselves). You can specify a key using keyBy(KeySelector) on a DataStream. This will yield a KeyedDataStream, which then allows operations that use keyed state.
A key selector function takes a single record as input and returns the key for that record. The key can be of any type and must be derived from deterministic computations.
The data model of Flink is not based on key-value pairs. Therefore, you do not need to physically pack the data set types into keys and values. Keys are “virtual”: they are defined as functions over the actual data to guide the grouping operator.
The following example shows a key selector function that simply returns the field of an object:
如果要使用 keyedState,则首先需要在 DataStream上指定一个key,该 key 应用于划分状态(以及流本身中的记录)。您可以在DataStream上使用 keyBy 算子(key的选择器)来指定一个key。这将产生一个KeyedDataStream,然后允许操作生成keyedState。
key算子(选择器)将单个记录作为输入,并返回该记录的键。key 可以是任何类型,并且必须从确定性计算中得出。
Flink的数据模型不是基于 key-value键值对。因此,您无需将数据集类型打包到 key和 value中。key 是“虚拟的”:key 从实际数据中定义出来,用于后续的一些分组操作。
下面的示例显示了一个 key 算子(选择器),该函数仅返回对象的字段:
2.1 State 状态
Flink 实时计算程序为了保证计算过程中,出现异常可以容易,就要将中间的计算结果数据存储起来,如果不保存中间结果那么需要重新计算效率就非常低下,这些中间数据就叫做 State。
State 可以是多种类型的,状态保存在 TaskManager 的内存中,检查点保存在 JobManager 的内存中。也可以保存到 TaskManager 本地文件系统或HDFS 这样的分布式文件系统。
2.2 StateBackEnd
用来保存 State 的存储后端就叫做 StateBackEnd。默认:状态保存在 TaskManager 的内存中,检查点保存在 JobManager 的内存中,也可以保存在本地文件系统或HDFS这样的分布式文件系统。
2.3 CheckPointing
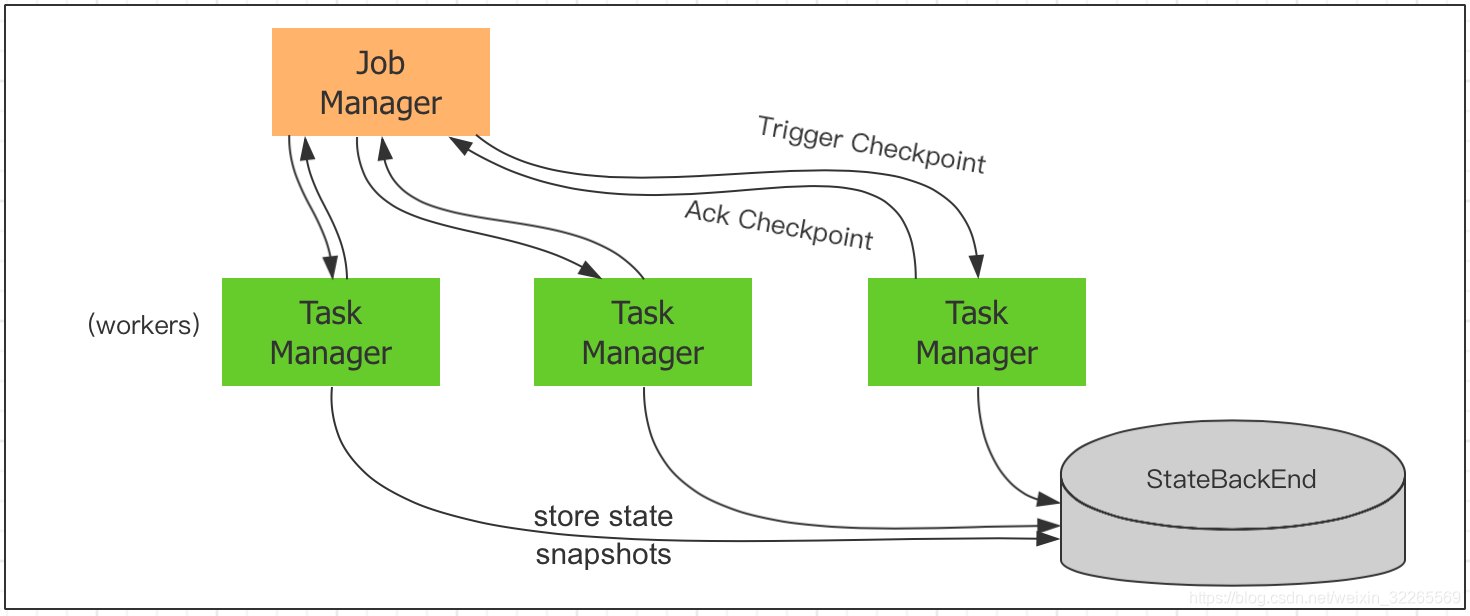
Flink 实时计算为了容错,可以将中间数据定期保存起来,这种定期触发保存中间结果的机制叫 CheckPointing。CheckPointing 是周期性执行的,具体的过程是 :JobManager 周期性地向 TaskManager 中的 SubTask 发送 RPC 消息,SubTask 将其计算的 State 保存到 StateBackEnd 中,并且向 JobManager 响应 Checkpoint 是否成功,如果程序出现异常或重启,TaskManager 中的 SubTask 可以从上一次成功的 CheckPointing 的State 恢复。
三、如何启用和配置检查点
默认情况下,CheckPoint 检查点是禁用的。为了使检查点,通过StreamExecutionEnvironment 对象调用 enableCheckpointing(n)方法,其中Ñ是以毫秒为单位的检查点间隔。
Flink 官网链接:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/state/checkpointing.html
3.1 重启策略
Flink支持不同的重新启动策略,这些策略控制在出现故障时如何重新启动作业。Flink 实时计算程序,为了容错,需要开启 CheckPointing,一旦开启 CheckPointing,如果没有重启策略,默认的重启策略是无限重启,也可以设置其他重启策略,如:重启固定次数且可以延迟执行的策略。
重启示例程序如下:运行结果就是如果前3次输入null,重启策略会生效,Flink 会将中间结果保存、还原。
package com.lei.apitest.c05_project;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// Flink 的重启策略
public class C05_RestartStrategiesDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 只有开启了checkpointing 才会有重启策略,默认保存到JobManager中的内存中
env.enableCheckpointing(5000); // 开启,检查点周期,单位毫秒;默认是-1,不开启
// 默认的重启策略是固定延迟无限重启
//env.getConfig().setRestartStrategy(RestartStrategies.fallBackRestart());
// 设置固定延迟固定次数重启
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000));
DataStreamSource<String> lines = env.socketTextStream("localhost", 7777);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
if (word.startsWith("null")) {
throw new RuntimeException("输入为null,发生异常");
}
return Tuple2.of(word, 1);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = wordAndOne.keyBy(0).sum(1);
summed.print();
env.execute("C05_RestartStrategiesDemo");
}
}
3.2 选择适合的状态后端
Flink的检查点机制将所有状态的一致快照周期性存储和有状态operators,包括连接器,窗口和任何用户定义的状态。检查点的存储位置(例如JobManager内存,文件系统,数据库)取决于所配置的 State Backend。
默认情况下,状态保存在 TaskManager 的内存中,检查点保存在 JobManager 的内存中。为了适当保留大状态,Flink支持在其他状态后端中存储和检查点状态的各种方法。可以通过来配置状态后端的选择StreamExecutionEnvironment.setStateBackend(…)。
需要注意的是如下操作都需要进行设置才会生效:
- 只有开启了checkpointing,重启策略才会生效;默认不开启重启策略
- 设置固定延迟固定次数重启;默认是无限重启
- 设置状态数据存储的后端;默认:状态保存在 TaskManager 的内存中,检查点保存在 JobManager 的内存中
- 程序异常退出或人为cancel掉,不删除checkpoint的数据;默认是会删除Checkpoint数据
话不多说,直接上示例代码:
package com.lei.apitest.c05_project;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// Flink 的StateBackend的使用
public class C06_StateBackendDemo {
public static void main(String[] args) throws Exception {
// 状态后端数据存储应该存储在分布式文件系统里,便于管理维护
System.setProperty("HADOOP_USER_NAME", "root");
System.setProperty("hadoop.home.dir", "/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/bin/");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 只有开启了checkpointing,重启策略才会生效;默认不开启重启策略
env.enableCheckpointing(5000); // 开启,检查点周期,单位毫秒;默认是-1,不开启
// 默认的重启策略是固定延迟无限重启
//env.getConfig().setRestartStrategy(RestartStrategies.fallBackRestart());
// 设置固定延迟固定次数重启;默认是无限重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 1000));
// 设置状态数据存储的后端,本地文件系统;默认:状态保存在 TaskManager 的内存中,检查点保存在 JobManager 的内存中
env.setStateBackend(new FsStateBackend("file:\\\\test_project\\idea_workspace\\FlinkTutorial\\check_point_dir"));
// 生产环境将StateBackend保存到分布式文件系统
//env.setStateBackend(new FsStateBackend("hdfs://node-01:8020/user/root/sqoop/flink_state_backend"));
// 程序异常退出或人为cancel掉,不删除checkpoint的数据;默认是会删除Checkpoint数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
DataStreamSource<String> lines = env.socketTextStream("node-01", 7777);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
if (word.startsWith("null")) {
throw new RuntimeException("输入为null,发生异常");
}
return Tuple2.of(word, 1);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = wordAndOne.keyBy(0).sum(1);
summed.print();
env.execute("C06_StateBackendDemo");
}
}
3.3 在迭代作业中的状态检查点
Flink 当前仅为没有迭代的作业提供处理保证。在迭代作业上启用检查点会导致异常。为了在迭代程序上强制检查点,用户需要在启用检查点时设置一个特殊标志:env.enableCheckpointing(interval, CheckpointingMode.EXACTLY_ONCE, force = true)。
请注意,在故障期间,循环边缘中正在运行的记录(以及与它们相关的状态更改)将丢失。
四、Flink 占用内存空间越来越大,原因/优化
原因可能是:
- 开启了checkpoint机制,没有设置或设置StateBackEnd策略为内存,所以运行越久,占用内存越高
- 数据量大,使用了大对象存储
- 数据结构选取不合理,导致占用内存过多
优化思路:
- 可以将大的状态数据存入checkpoint 状态后端,减少内存占用;
- 可以使用合适的数据结构;如去重,可以考虑使用布隆过滤器;
- 尽可能使用常规数据类型,如int,float,double 代替 Integer,Float,Double;
文章最后,给大家推荐一些受欢迎的技术博客链接:
- JAVA相关的深度技术博客链接
- Flink 相关技术博客链接
- Spark 核心技术链接
- 设计模式 —— 深度技术博客链接
- 机器学习 —— 深度技术博客链接
- Hadoop相关技术博客链接
- 超全干货--Flink思维导图,花了3周左右编写、校对
- 深入JAVA 的JVM核心原理解决线上各种故障【附案例】
- 请谈谈你对volatile的理解?--最近小李子与面试官的一场“硬核较量”
- 聊聊RPC通信,经常被问到的一道面试题。源码+笔记,包懂
- 深入聊聊Java 垃圾回收机制【附原理图及调优方法】
欢迎扫描下方的二维码或 搜索 公众号“大数据高级架构师”,我们会有更多、且及时的资料推送给您,欢迎多多交流!
![]()
