读书,是提高个人知识、能力的有效途径。教师——传道授业解惑者,这种特殊的职业就决定了教师必须把读书作为一生中的头等大事。
1.学习目的
以学校开展读书活动为契机,计划读好一本书,至少写好5篇读书笔记,能够真正开启深度学习之旅,基本掌握深度学习在NLP中的应用,是我的读书目标。
2.学习方法及成果
以《TensorFlow实战Google深度学习框架》书为主,查阅了《强化学习精要核心算法与TensorFlow实现》、《PaddlePaddle深度学习实战》、《21个项目玩转深度学习》等参考资料,当然也少不了参考TensorFlow官网。按照读书计划采用以自学为主,辅以和参加了百度、中南大学在湖南长沙联合承办的“新工科产学研联盟2019年第四期深度学习师资培训班”,一边学习一边在阿里云平台和百度平台上实践,顺利完成了学习目标。同时,对于难懂的函数、方法以及不同深度学习平台的差异与解决方法,基于自己的观点和看法写出反思和随笔,已经完成读书笔记5篇和1篇读书心得,都发布在博客园的个人播客(https://www.cnblogs.com/bigdata-sanya/)。
3.学习过程中的收获
3.1 加深了基本概念的理解
掌握深度学习及Python开发语言的基本概念是非常重要的,因为其是解决问题的基础,只有基本概念清晰、理解正确、思维才会敏捷。譬如:理解Python 类中的 __init__、__new__、__call__ 方法。
__init__方法负责对象的初始化,系统执行该方法前,其实该对象已经存在了。__new__ 方法,它作为构造函数用于创建对象,是一个工厂函数,专用于生产实例对象。前面两种方法,很容易理解,但是对于__call__ 方法,值得花费一点时间来理解,因为它在深度学习,尤其TensorFlow中大量使用。
__call__,即可调用对象(callable),如果在类中实现了 __call__ 方法,那么实例对象也将成为一个可调用对象,利用这种特性可以实现基于类的装饰器,在类里面记录状态。
3.2 熟练了常用函数的使用方法
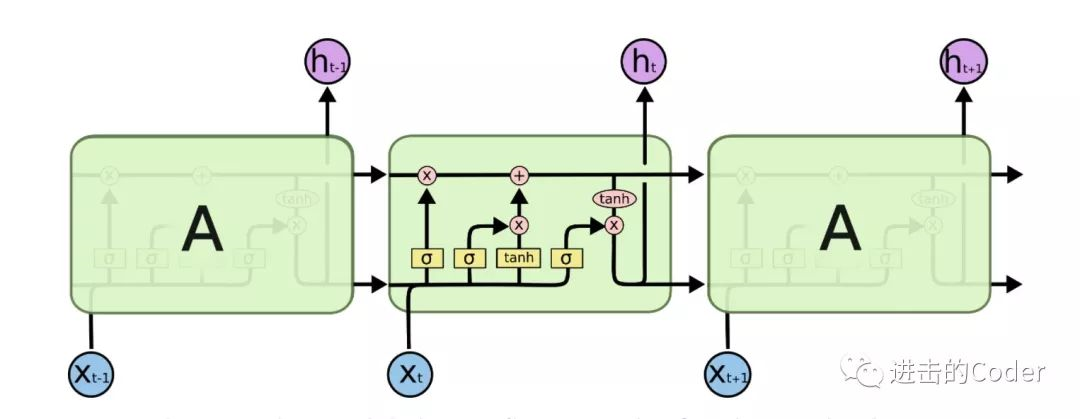
LSTM,Long Short Term Memory Networks,是 RNN 的一个变种,经试验它可以用来解决更多问题,并取得了非常好的效果,了解深度学习的人都不陌生。但是对于tf.nn.rnn_cell.BasicLSTMCell()的用法却不一定很熟练,尤其对想快速掌握的人来说。有两个个问题必须要了解,因为在LSTM中有大量使用。
1)为什么使用tanh?
为了克服梯度消失问题,需要一个二阶导数在趋近零点之前能维持很长距离的函数。tanh是具有这种属性的合适的函数。
2)为什么要使用Sigmoid?
由于Sigmoid函数可以输出0或1,它可以用来决定忘记或记住信息。
在此基础上,再来看tf.nn.rnn_cell.BasicLSTMCell()。在tensorflow中文官网(https://tensorflow.google.cn/)居然只能看到BasicLSTMCell类的初始化函数。
1. __init__( 2. num_units, 3. forget_bias=1.0, 4. state_is_tuple=True, 5. activation=None, 6. reuse=None, 7. name=None, 8. dtype=None, 9. **kwargs 10. )
如果只要简单掌握,发现众多参数中只要给一个参数赋值。通过初始化方法 init()发现,该类继承了 RNNCell 类。必须传入的参数仍然是 num_units,即神经元的个数,然后 forget_bias 是初始化 Forget Gate 的偏置大小,state_is_tuple 指的是输出状态类型是元组类型,activation 代表默认激活函数,reuse 代表是否可以被重复使用。但是,如果需要熟练掌握,则需要弄懂每个参数的含义及应用。一般采用查看源代码,原汁原味。碰到不懂函数,必须抽茧剥丝,层层迭代,方有拨开云雾见天日,守得云开见月明的体会。
1. def __init__(self, num_units, forget_bias=1.0, 2. state_is_tuple=True, activation=None, reuse=None): 3. super(BasicLSTMCell, self).__init__(_reuse=reuse) 4. if not state_is_tuple: #isinstance(a,tuple) 5. logging.warn('%s: Using a concatenated state is slower and will soon be ' 6. 'deprecated. Use state_is_tuple=True.', self) 7. self._num_units = num_units 8. self._forget_bias = forget_bias 9. self._state_is_tuple = state_is_tuple 10. self._activation = activation or math_ops.tanh #tf.nn.relu、tf.sigmoid、tf.tanh 11. self._linear = None
只看函数,仍然不是很理解。再看此类的其他函数, state_size() 方法和 output_size() 方法,实现如下:
1. # 这里有两个属性state_size和output_size分别是RNNCell里定义的属性,根据需求重写与否。 2. @property 3. def state_size(self): 4. return (LSTMStateTuple(self._num_units, self._num_units) 5. if self._state_is_tuple else 2 * self._num_units) 6. 7. @property 8. def output_size(self): 9. return self._num_units
从上可以发现,存储LSTM单元的state_size,zero_state和output state的元组。按顺序存储两个元素(c,h),其中c是隐藏状态,h是输出。只有在state_is_tuple=True是才使用。
到这一步还没有完,还要熟悉该类的__call__函数。源代码如下:
1. def call(self, inputs, state): 2. sigmoid = math_ops.sigmoid 3. # Parameters of gates are concatenated into one multiply for efficiency. 4. if self._state_is_tuple: 5. c, h = state 6. else: 7. c, h = array_ops.split(value=state, num_or_size_splits=2, axis=1) 8. ## 这里体现了参数state_is_tuple的作用了,如果为True,则传入的状态(c,h)需要为一个元组传入, 9. ##如果False,则需要传入一个Tensor,其中分别是c和h层叠而成, 10. ##建议采用第一种为True的方案,减少split带来的开销。 11. 12. concat = _linear([inputs, h], 4 * self._num_units, True) 13. ## 这里将inputs和上一个输出状态拼接起来,尔后进行线性映射。 14. ##输出为4倍的隐藏层神经元数,是为了后面直接分割得到i,j,f,o(其中的j为公式中的g,代表gate) 15. ## 其中的_linear()是rnn_cell_impl.py中的一个函数,作用就是线性映射,还需要进一步阐述。 16. 17. i, j, f, o = array_ops.split(value=concat, num_or_size_splits=4, axis=1) 18. # 分割 19. new_c = ( 20. c * sigmoid(f + self._forget_bias) + sigmoid(i) * self._activation(j)) 21. new_h = self._activation(new_c) * sigmoid(o) 22. # 核心计算,更新状态得到new_c和new_h 23. 24. if self._state_is_tuple: 25. new_state = LSTMStateTuple(new_c, new_h) 26. else: 27. new_state = array_ops.concat([new_c, new_h], 1) 28. return new_h, new_state
至此,应该就可以理解LSTM类初始化参数的含义。只有这样在应用中才能灵活运用。首先继承父类RNNCell,按照你的需求重写state_size, output_size和call,有时候还需要重写zeros_state,其中state_size, output_size重写这两个属性才能在MultiRNNCell,DropoutWrapper,Dynamic_rnn等方法中正常使用。至于call就是其核心的方法了,如果自定义自己的单元,肯定需要重写的,zeros_state是进行细胞状态初始化的,一般初始化为全0张量即可。
3.3 体会到深度学习在NLP中的强大应用
此部分,以本人参加百度、中南大学在湖南长沙联合承办的“新工科产学研联盟2019年第四期深度学习师资培训班”的结业考试为例子-基于THUCNews数据集的文本分类比赛。
1)采用了LSTM网络。
1. # 创建lstm网络 2. def Bilstm_net(data, dict_dim, class_dim, emb_dim=512, hid_dim=512, hid_dim2=96, emb_lr=30.0): 3. # embedding layer 4. emb = fluid.layers.embedding(input=data, 5. size=[dict_dim, emb_dim], 6. param_attr=fluid.ParamAttr(learning_rate=emb_lr)) 7. 8. # bi-lstm layer 9. fc0 = fluid.layers.fc(input=emb, size=hid_dim * 4) 10. 11. rfc0 = fluid.layers.fc(input=emb, size=hid_dim * 4) 12. 13. lstm_h, c = fluid.layers.dynamic_lstm(input=fc0, size=hid_dim * 4, is_reverse=False) 14. 15. rlstm_h, c = fluid.layers.dynamic_lstm(input=rfc0, size=hid_dim * 4, is_reverse=True) 16. 17. # extract last layer 18. lstm_last = fluid.layers.sequence_last_step(input=lstm_h) 19. rlstm_last = fluid.layers.sequence_last_step(input=rlstm_h) 20. 21. # concat layer 22. lstm_concat = fluid.layers.concat(input=[lstm_last, rlstm_last], axis=1) 23. 24. # full connect layer 25. fc1 = fluid.layers.fc(input=lstm_concat, size=hid_dim2, act='tanh') 26. # softmax layer 27. prediction = fluid.layers.fc(input=fc1, size=class_dim, act='softmax') 28. return prediction
2)采用了多种方法减少过拟合的影响
a)初始代码
1. # 获取测试程序 2. test_program = fluid.default_main_program().clone(for_test=True) 3. #使用Adam算法进行优化, learning_rate 是学习率(它的大小与网络的训练收敛速度有关系) 4. optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.001) 5. opts = optimizer.minimize(avg_cost)
b)优化的代码
1. # 获取测试程序 2. test_program = fluid.default_main_program().clone(for_test=True) 3. #使用Adam算法进行优化, learning_rate 是采用指数衰减学习率(它的大小与网络的训练收敛速度有关系) 4. #对Weights进行正则化L2 5. learning_rate=fluid.layers.exponential_decay( 6. learning_rate=0.001, 7. decay steps=684, 8. decay_rate=0.5, 9. staircase=True) 10. optimizer = fluid.optimizer.AdamOptimizer(learning_rate=learning,regularization=fluid.regularizer.L2DecayRegularizer( 11. regularization_coeff=0.1)) 12. opts = optimizer.minimize(avg_cost)
采用LSTM结构、指数衰减学习率和对Weights进行正则化L2,accuary从 64.2% 上升到81.4%.在NLP结业考试中当时我提交效果如下:

4.存在的不足
现在主要理解别人的实现,处于归纳、总结,还没有个人的创新。后续工作还有基于循环神经网络的语言模型的实现、与TensorFlow的对比实验。
从目前我个人的使用情况,觉得TensorFlow暂时要比PaddlePaddle好用,主要是PaddlePaddle真正的参考书籍少,还有功能方面前者要灵活一些,还有函数还只能在Python环境下使用,如:paddle.fluid.optimizer.ExponentialMovingAverage(decay=0.999, thres_steps=None, name=None)。至于性能对比,后续工作将进行对比实验。
2019年8月28日
附:读书计划:
| 日期 |
章节 |
备注 |
| 7.1-7.10 |
TensorFlow环境搭建、TensorFlow入门 |
|
| 7.11-7.15 |
深层神经网络 |
读后感一篇 |
| 7.20-7.30 |
MNIST数字识别问题 图像识别与卷积神经网络 |
读后感两篇 |
| 8.1-8.15 |
循环神经网络 自然语言处理 |
读后感两篇 |
| 8.16-8.30 |
TensorFlow高层封装 TensorBoard可视化 |
|