快跑!这是林荫最想逃避的算法之一!
树链剖分——计算机术语,指一种对树进行划分的算法,它先通过轻重边剖分将树分为多条链,保证每个点属于且只属于一条链,然后再通过数据结构(树状数组、BST、SPLAY、线段树等)来维护每一条链。
前置芝士:
- DFS序
- 线段树
先来一道水题:
将树从x到y结点最短路径上所有节点的值都加上z
这个很好办,树上差分就可以解决这个林荫也不熟练
再来一个:求树从x到y结点最短路径上所有节点的值之和
这个也不错,先将点权转化为边权,同时维护树上点的深度,求LCA深度*2与两点深度作差即可。
但是要是将这两者结合起来怎么办?每次改变边权就DFS一次?那么N一次的改变会使你T上天。
_________________________________________林荫的分割线_____________________________________________________________
锵锵锵!树链剖分大魔王登场啦!
众所周知线段树可以维护一个数列的加减乘对吧,那么我们如果将这棵树拆成很多条链是不是就可以用线段树维护变化了呢?
那肯定是啊!
树剖是通过轻重边剖分将树分割成多条链,然后利用数据结构来维护这些链(本质上是一种优化暴力)
下个定义:
-
重儿子:父亲节点的所有儿子中子树结点数目最多(size最大)的结点;
-
轻儿子:父亲节点中除了重儿子以外的儿子;
-
重边:父亲结点和重儿子连成的边;
-
轻边:父亲节点和轻儿子连成的边;
-
重链:由多条重边连接而成的路径;
-
轻链:由多条轻边连接而成的路径;
先来一张网上广为流传的图:
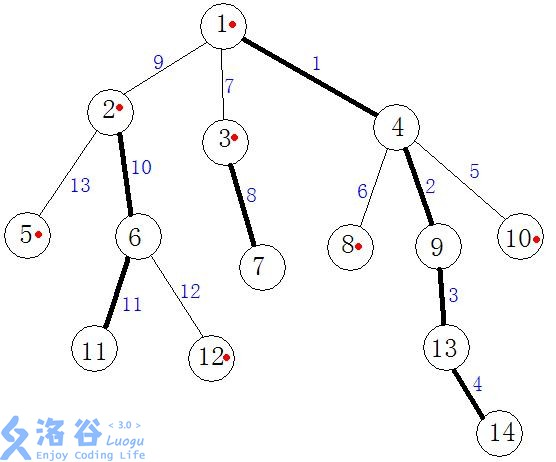
嗯,就是这样。
通过上面的定义,我们可以看到图中加黑的粗线就是重遍,重链也有3条。图中带有红点的点就是自己所在重链的起点,轻链上的叶子节点也是以自己为首的重链的起点哦(小小箍桶将,在家也是当家人/市长)
注意一下,图中边上的数字是DFS访问的顺序,点上的数字只是编号,至于像⑥的重儿子具体是11还是12这个倒是无所谓了。
struct PE { int sum,mx; }; PE t[120001]; int fa[30001],val[30001],size[30001],id[30001],rk[30001],son[30001],top[30001],dep[30001]; vector<int> b[30001];
声明变量:照样是网图(这份代码里面没写lazy标记)
| 名称 | 解释 |
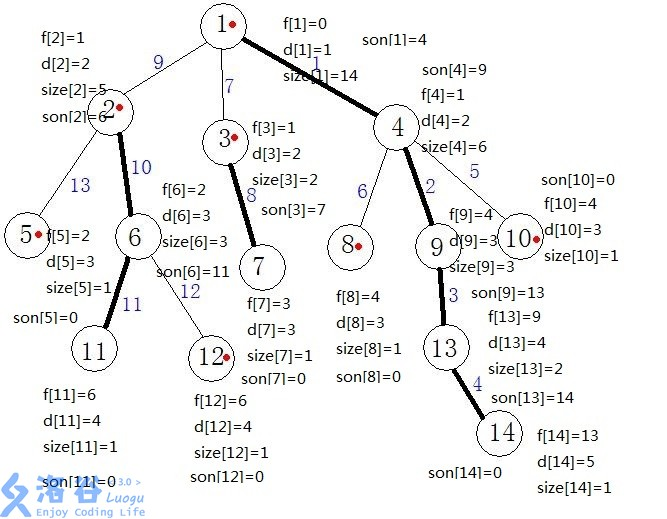
| f[u] | 保存结点u的父亲节点 |
| d[u] | 保存结点u的深度值 |
| size[u] | 保存以u为根的子树节点个数 |
| son[u] | 保存重儿子 |
| rk[u] | 保存当前dfs标号在树中所对应的节点 |
| top[u] | 保存当前节点所在链的顶端节点 |
| id[u] | 保存树中每个节点剖分以后的新编号(DFS的执行顺序) |
好啦,这些变量中f,d,size,son都可以在第一次DFS中求出。
void dfs1(int x) { size[x]=1,d[x]=d[f[x]]+1; for(int v,i=head[x];i;i=e[i].next) if((v=e[i].to)!=f[x]) { f[v]=x,dfs1(v),size[x]+=size[v]; if(size[son[x]]<size[v]) son[x]=v; } }
处理出这些就是为了下面分出链做准备。
第二次DFS!
void dfs2(int x,int tp) { top[x]=tp,id[x]=++cnt,rk[cnt]=x; if(son[x]) dfs2(son[x],tp); for(int v,i=head[x];i;i=e[i].next) if((v=e[i].to)!=f[x]&&v!=son[x]) dfs2(v,v); }
在这次DFS中维护了重链上每个点的TOP,id和rk是用于维护线段树所必须的参数。(在线段树中所谓的区间就是指一段DFS序,那么x的所在位置就是id[x])
DFS跑完长这样!
下面的话,线段树的基本操作大家都会吧,唯一有所不同的是,启动线段树上对于节点X的调用时,