Part 1:Python学习笔记
====================
12.对象持久化
12.1.扁平文件
12.1.1.文本文件
- 文本文件存储持久化对象
- 把你传递过来的字符串转换为Python表达式,这样就可以当Python语句一样运行
- 示例
1 #文本文件存储持久化对象 2 3 scores = [88,99,77,55] 4 5 def write_scores(): 6 with open('data_list.txt','w',encoding='utf8') as f: 7 f.write(str(scores)) 8 print('File writing completed......') 9 10 def read_scores(): 11 with open('data_list.txt','r',encoding='utf8') as f: 12 lst = eval(f.read()) #把你传递过来的字符串转换为Python表达式,这样就可以当Python语句一样运行 13 14 lst[0] = 99 15 print(lst) 16 17 if __name__ == '__main__': 18 # write_scores() # run this first to create the data_list.txt file 19 read_scores()
12.2.pickle
12.2.1.pickle模块
- 序列化位字符串
- .dumps(obj): 将对象序列转为字符串
- .loads(s): 将字符串发序列转化对象
- 示例
1 import pickle 2 person = {'name':'Tom','age':20} 3 s = pickle.dumps(person) 4 s
运行结果:b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x03\x00\x00\x00Tomq\x02X\x03\x00\x00\x00ageq\x03K\x14u.'
1 p = pickle.loads(s) 2 p
运行结果:{'name': 'Tom', 'age': 20}
- 序列化对象到文件
- .dump(obj,file)
- .load(file)
- 示例
1 person = {'name':'Tom','age':20} 2 pickle.dump(person,open('pickle.db','wb')) 3 p = pickle.load(open('pickle.db','rb')) 4 p
运行结果:Out[14]: {'name': 'Tom', 'age': 20}
12.3.shelve
12.3.1.shelve
将多个对象存在一个文件中
- .open('dbfile')
- .close()
- db['key'] = obj
- len(db)
- del db['key']
- 示例
1 # Shelve 序列化自定义类实例 2 3 import shelve 4 5 class Student: 6 def __init__(self,name,age): 7 self.name = name 8 self.age = age 9 10 11 def __str__(self): 12 return self.name 13 14 def write_shelve(): 15 s = Student('Tom', 20) 16 db = shelve.open('shelve_student_db') 17 db['s'] = s 18 db.close() 19 20 def read_shelve(): 21 db = shelve.open('shelve_student_db') 22 st = db['s'] 23 print(st) 24 print(st.name) 25 print(st.age) 26 db.close() 27 28 29 if __name__ == '__main__': 30 # write_shelve() # First run this so that the shelve_student_db.* files can be created 31 read_shelve()
12.4.数据库
12.5.ORM
13.字符串
13.1.概述
13.1.1.类型
- str 字符串
- bytes 字节
- bytearray 字节数组
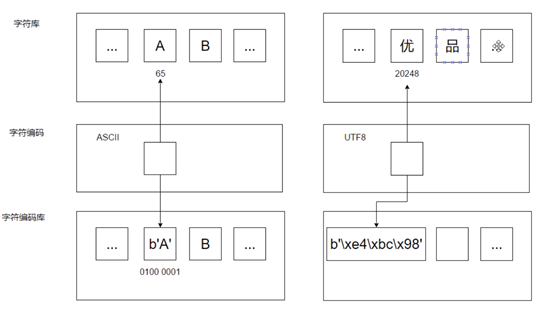
13.1.2.字符编码架构
- 字符集:赋值一个编码到某个字符,以便在内存中表示
- 编码 Encoding:转换字符到原始字节形式
- 解码 Decoding:依据编码名称转换原始字节到字符的过程
- 字符编码架构图:
13.1.3.字符串存储
- 编码只作用于文件存储或中间媒介转换时
- 内存中总是存储解码以后的文本
13.2.字符编码
13.2.1.ASCII
- 存储在一个Byte 0-127
- 存储在一个Byte 128-255
- 可变字节
13.2.2.latin-1
13.2.3.UTF-8
• 0-127 使用单字节
• 128-2047 双字节存储
• > 2047 3-4 Byte
• 每Byte使用 128-255
13.2.4.UTF-16
- 2 Byte存储字符(另加2 Byte作为标识)
- 4 Byte
13.2.5.UTF-32
13.3.内置函数
13.3.1.ord()获取字符代码点
13.3.2.chr()获取代码点对应的字符
13.3.3.str.encode('编码') 将特定字符编码
13.3.4.bytes.decode('编码') 将字符编码解码位字符文本
13.3.5.encode与decode示例
1 s1 = 'ABCD' 2 s1.encode('ASCII') 3 4 s2 = '优品课堂' 5 s2.encode('UTF-8') 6 7 b1 = b'\xe4\xbc\x98\xe5\x93\x81\xe8\xaf\xbe\xe5\xa0\x82' 8 9 b1.decode('utf-8')-->'优品课堂' 10 b1.decode('utf-16')-->看到乱码
- 注意:encode与decode,默认的编码方式是utf-8
1 import sys 2 sys.getdefaultencoding() 3 4 --> utf-8
13.3.6. 文件处理时制定编码类型示例
1 open('data.txt','w',encoding='utf-8').write('优品课堂') 2 open('data.txt','r',encoding='utf-8').read()
13.4.类型转换
13.4.1.bytes
- 手动声明 b''
- 字符串编码 str.encode()
- 构造函数 bytes()
- 不支持原位改变
13.4.2.bytearray
- bytearray(‘字符’,'编码')
- .decode() 解码为字符串
- 支持原位改变