图1
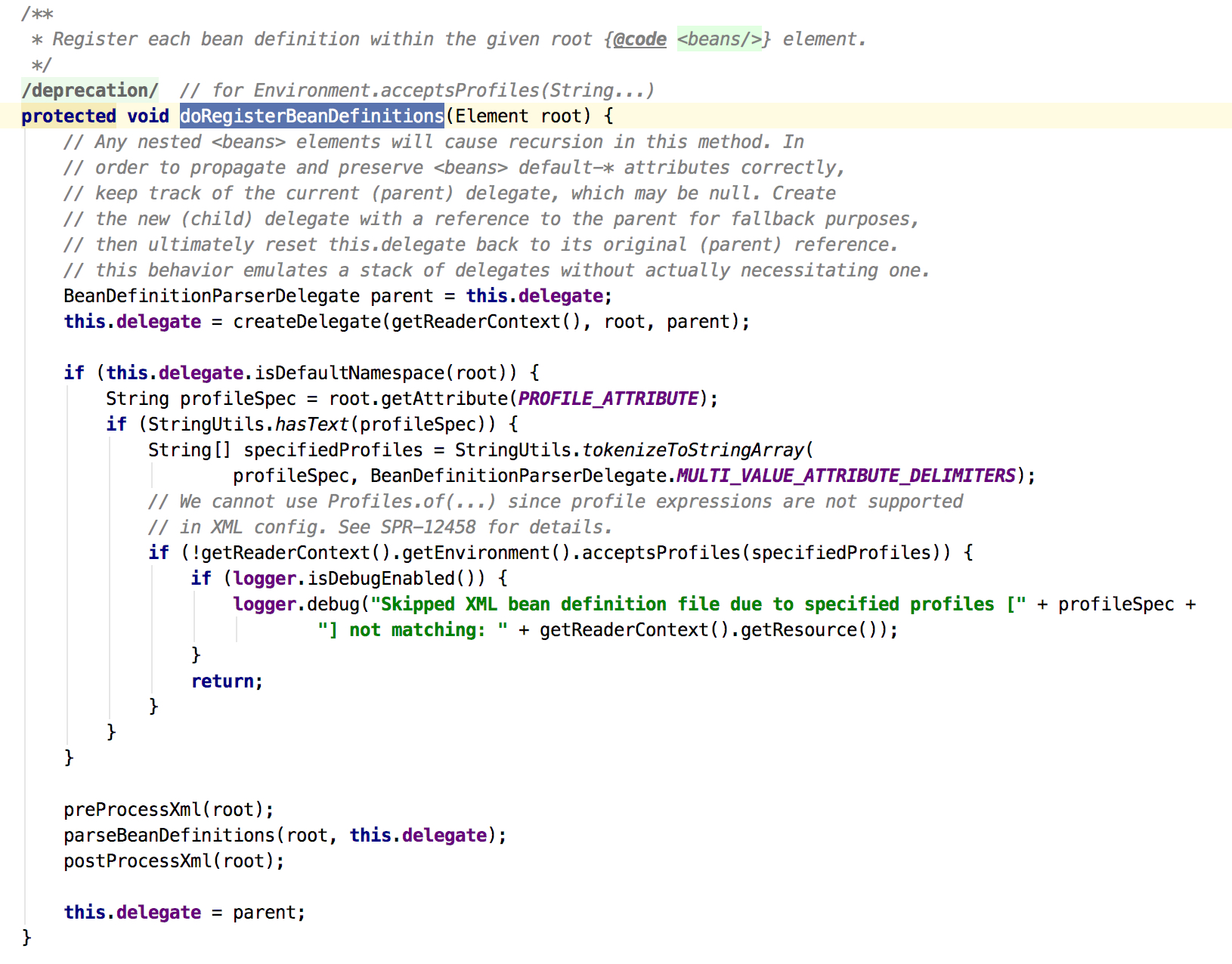
上次看到doRegisterBeanDefinitions方法,是DefaultBeanDefinitionDocumentReader这个类,这里是真正开始解析xml。
那么先来看下doRegisterBeanDefinitions做了些什么,先调用了createDelegate方法,如图2:
图2

实例化了一个BeanDefinitionParserDelegate(这里用了代理模式,不知道对不对),在来看下initDefaults方法,如图3:
图3

能看到有个populateDefaults方法,defaults全局变量是DocumentDefaultsDefinition defaults = new DocumentDefaultsDefinition();这个类包含了最外层<beans>的一些属性,关键还是看下populateDefaults方法,如图4:
图4

方法太长用两张截图

这里是解析最外层的<beans>的一些属性,一共有6个:
- default-lazy-init:延迟加载,延迟实例化bean;
- default-merge:在继承关系时在子类中合并父类的值;
- default-autowire:按哪种方式注入,byType、byName等;
- default-autowire-candidates:匹配到的bean才能加载;
- default-init-method:初始化方法;
- default-destroy-method:销毁方法;
能看到最后有一个setSource方法,这个可以自己实现SourceExtractor,额外的source信息,通过XmlBeanDefinitionReader.setSourceExtractor(SourceExtractor);来实现。如图5:
图5

使用的话如图6:
图6

好了那么继续下看,在解析完这些属性以后,有个this.readerContext.fireDefaultsRegistered(this.defaults);方法,如图7:
图7

这里有个eventListener,默认是EmptyReaderEventListener,可以自己实现ReaderEventListener以后覆盖掉,具体用法和SourceExtractor是一样的,这里不再累述了。
那创建完代理类就是真正的解析啦,就是parseBeanDefinitions(root, this.delegate);方法,如图8:
图8
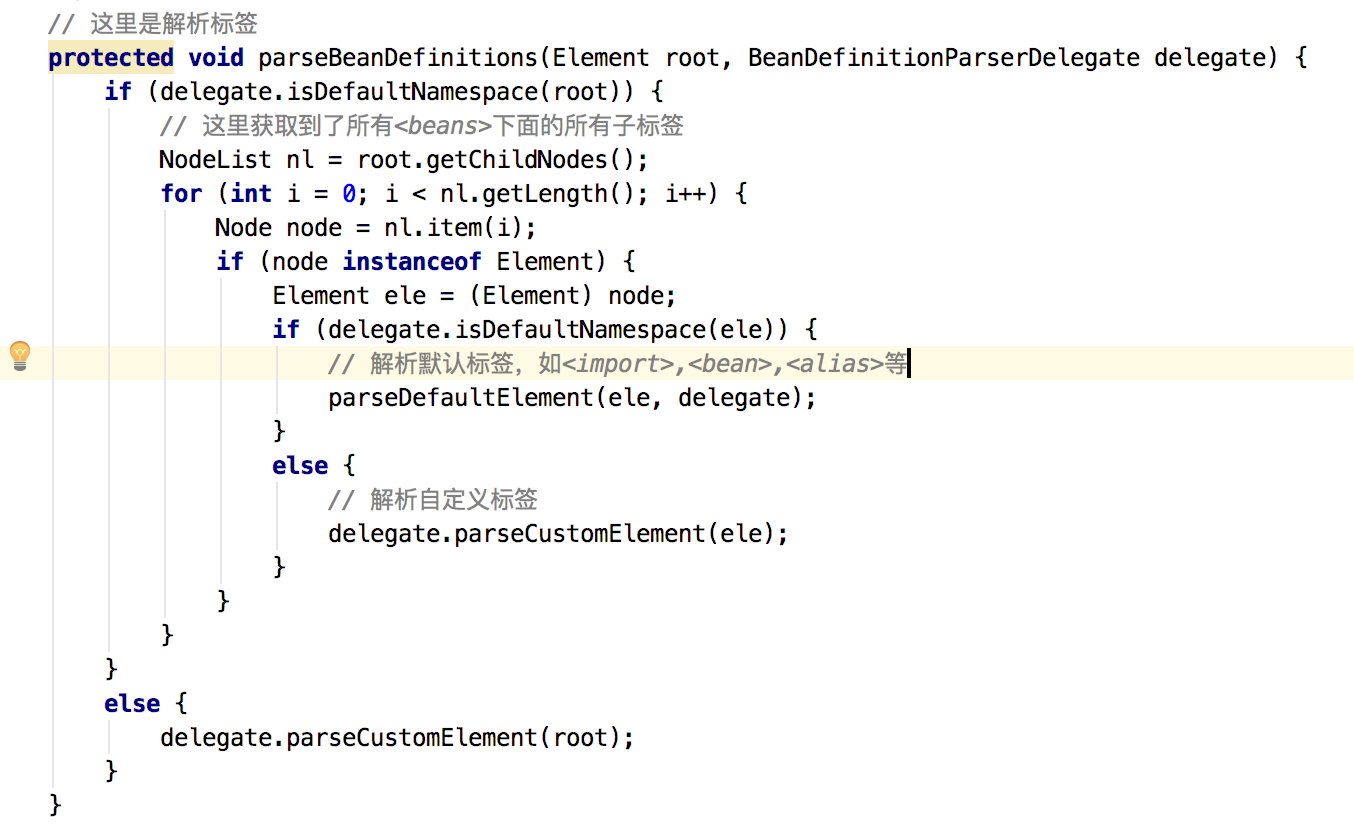
关于自定义标签我们下次再讲,还是来看下parseDefaultElement(ele, delegate);方法把,如图9:
图9
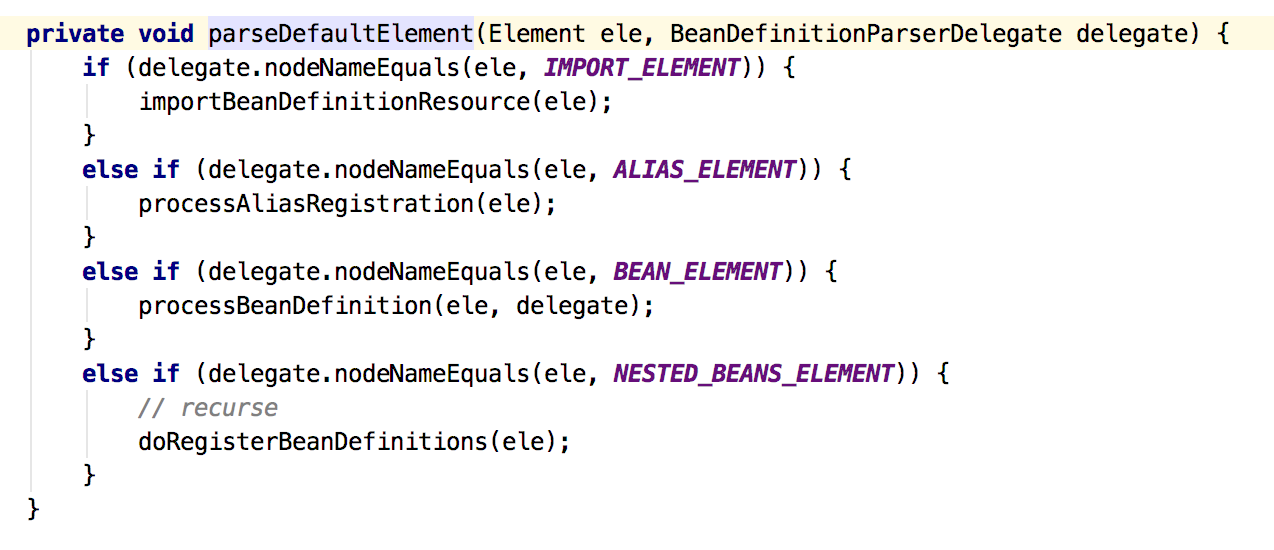
很明确就是解析四个标签:<import>、<bean>、<aliias>、<beans>,先来看下在复杂也最繁琐的解析<bean>吧,如图10:
图10

这个方法就是处理<bean>解析并完成注册的方法,代理方法开始显威啦delegate.parseBeanDefinitionElement(ele);如图11:
图11
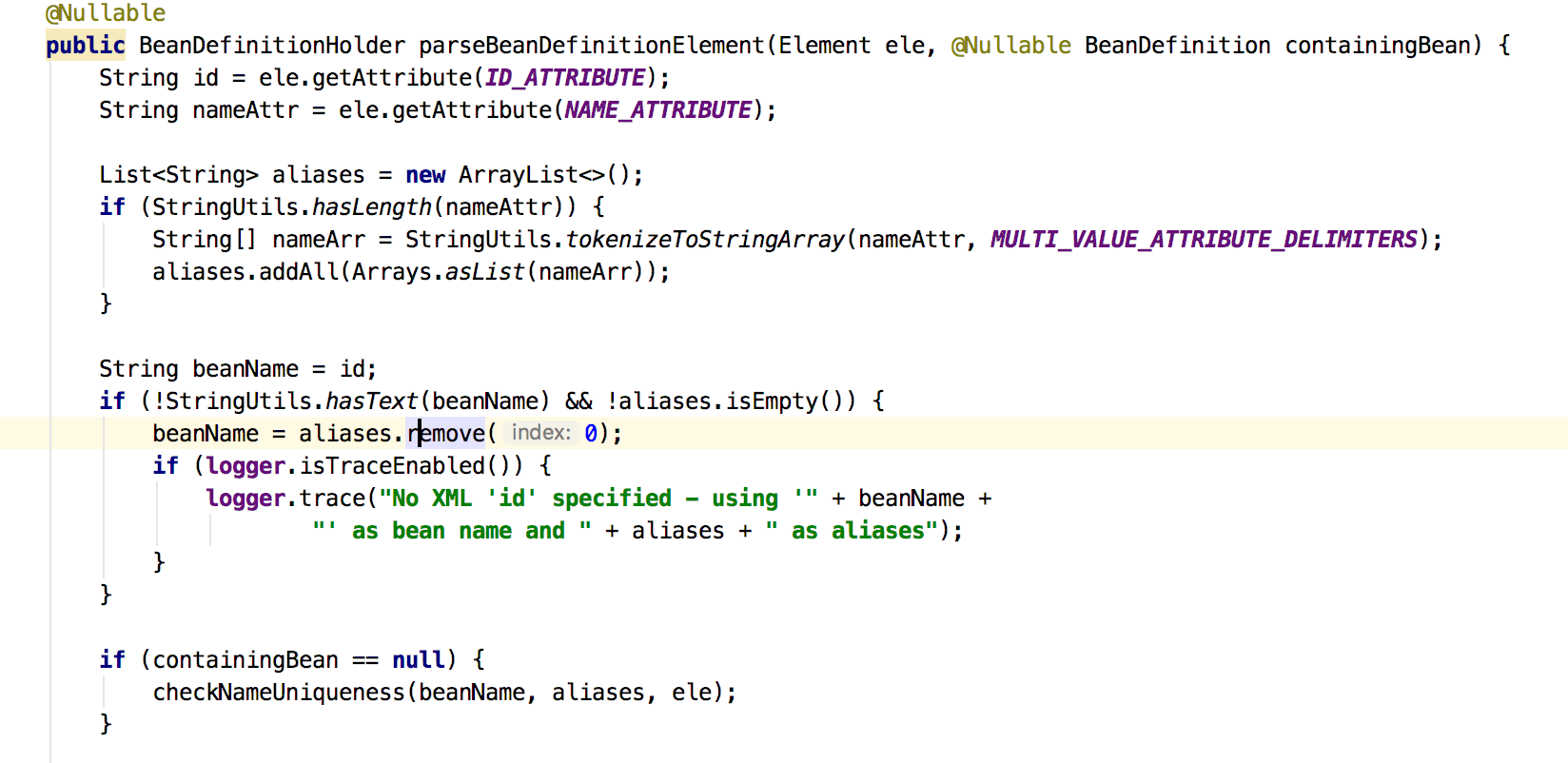
能看到先取id和name,默认的bean name是id,但是如果id没有,name就是bean name,在配置中name还可以用",; "分隔开,一个bean可以拥有多个别名,最后别名放到哪里我们后面会看到,如图12:
图12

刚只是方法的前半部分,还有后半部分,如图13:
图13
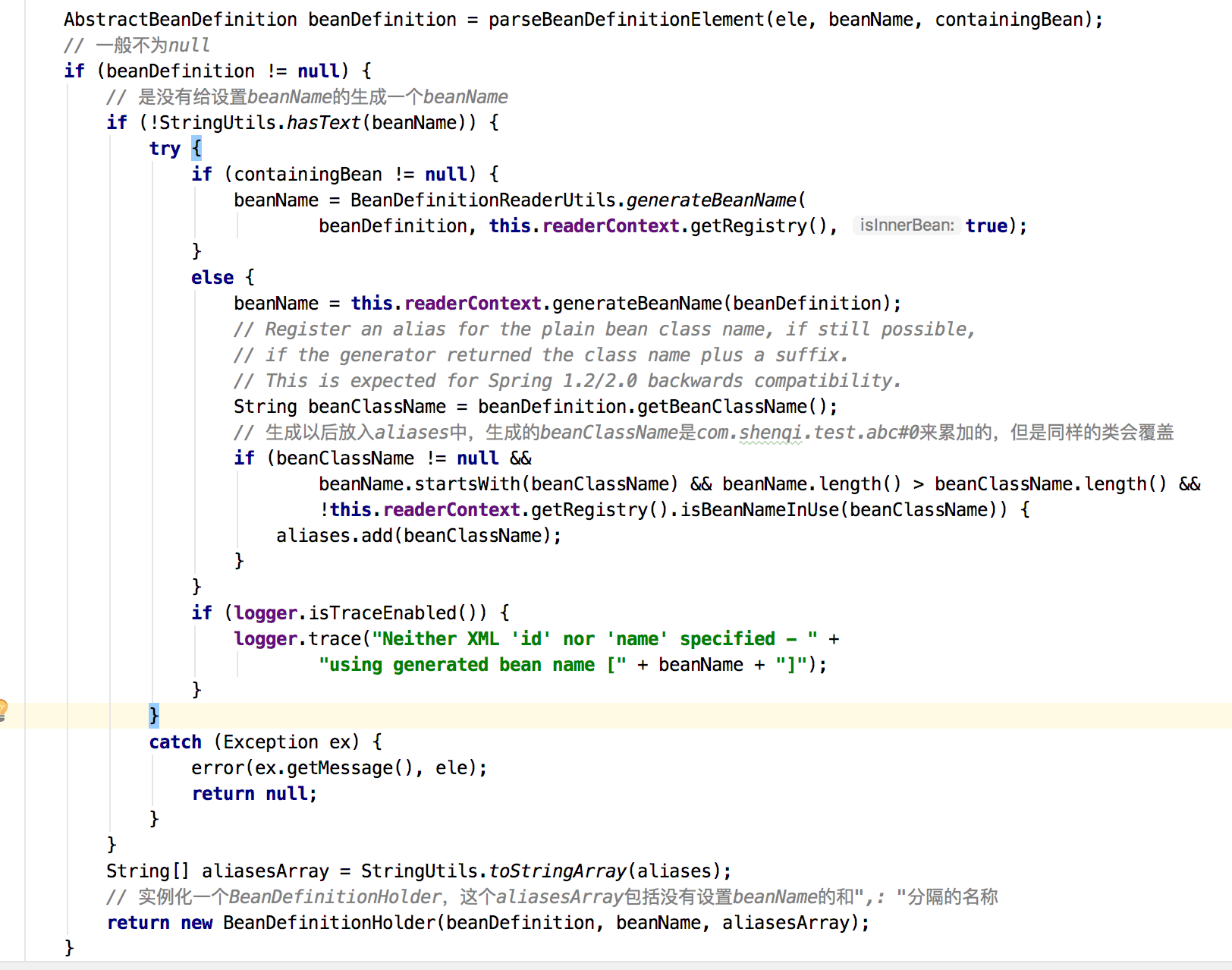
parseBeanDefinitionElement(ele, beanName, containingBean);方法就是解析<bean>中的所有属性,如图14:
图14

这是方法的前半部分,其实没啥好看的,关键还得看后半部分,如图15:
图15

这里就是解析<bean>里面所有的attribute了,具体这里就不在往下挖了因为实在太多了,最后所有解析出来的值都放入了AbstractBeanDefinition类中,好奇的小伙伴肯定想<bean>里面到底有多少属性,这里来列一下:
- scope
- abstract
- lazy-init
- autowire
- depends-on
- autowire-candidate
- primary
- init-method
- destroy-method
- factory-method
- factory-bean
具体怎么使用请看官网。
那么好了bean的所有信息都拿到了,接下去干嘛呢,回过头看图13,如果没有定义beanName的话,只有class,这个时候会去生成一个beanName,类似于com.shenqi.test.abc#0,如果有第二个就是#1这样以此类推。好,那么这个时候就返回了一个BeanDefinitionHolder,回过头来看图10的BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());方法,如图16:
图16
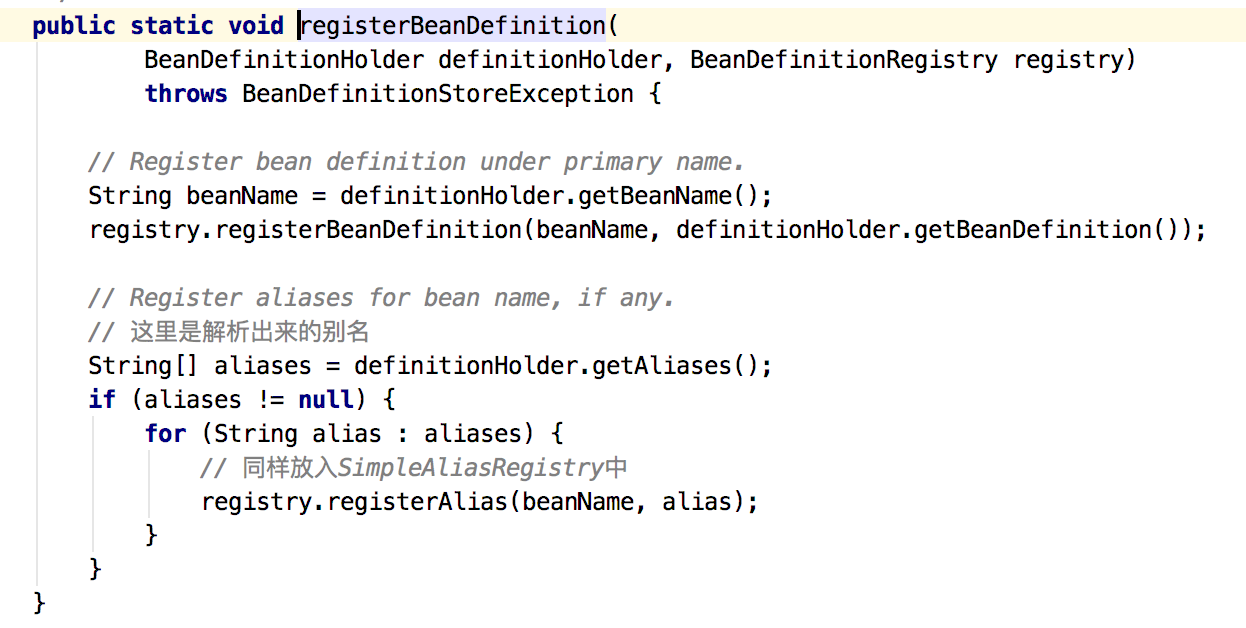
拿到了beanName,最后放入到DefaultListableBeanFactory,BeanDefinition放入Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);,beanName放入private volatile List<String> beanDefinitionNames = new ArrayList<>(256);中,别名的话会放入SimpleAliasRegistry的private final Map<String, String> aliasMap = new ConcurrentHashMap<>(16);中。
那么关于解析<alias>的话,其实最后就是放入SimpleAliasRegistry的private final Map<String, String> aliasMap = new ConcurrentHashMap<>(16);中。
<import>其实就是把读取xml和解析xml重新走一遍。
内嵌的<beans>的话就是解析图8的parseBeanDefinitions(root, this.delegate);重新走一遍。
这次一些细节的地方没有说明,大家可以自行去研究下,比如<meta>做获取,lookup,<qualifier>怎么使用等。
下次的话就是自定义啦。
如有问题请提出,共同提高,谢谢!!