设备性能测试 : 内存带宽的测试
zero, 说明:
为了对系统的性能进行优化,因而需要分析系统的性能瓶颈在哪里,需要对系统的一些设备的性能进行测试。这一篇文章用于记录内存带宽的测试,如果文章中有不足的地方,请不吝赐教。
一,背景知识:
下面提供一些关于内存结构的链接,如若侵权,请联系我进行删除.
CMU MainMemory
圖解RAM結構與原理,系統記憶體的Channel、Chip與Bank
二,实验环境
所使用的CPU的信息如下 : 一台机器有24个物理核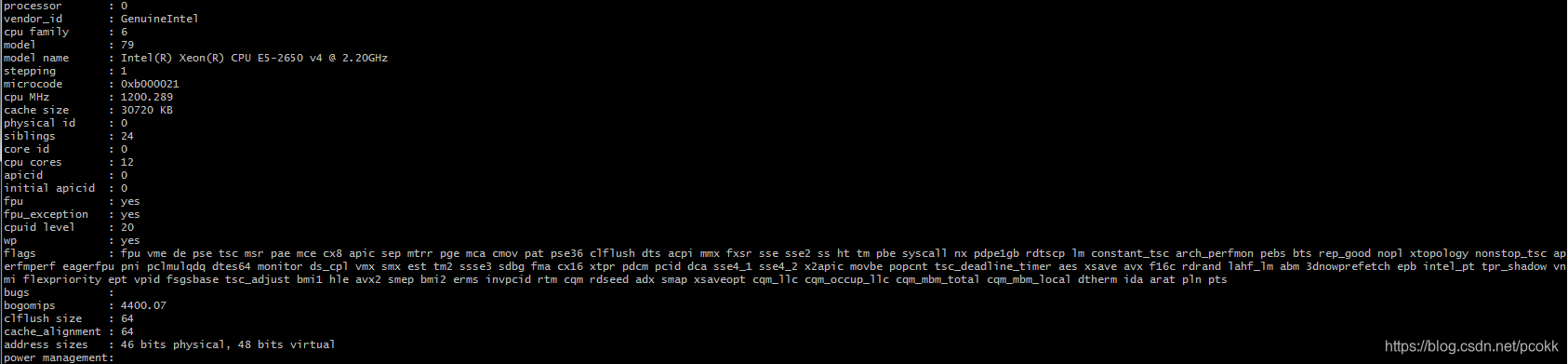
所使用的内存条的信息如下 : 一台机器有8个相同的内存条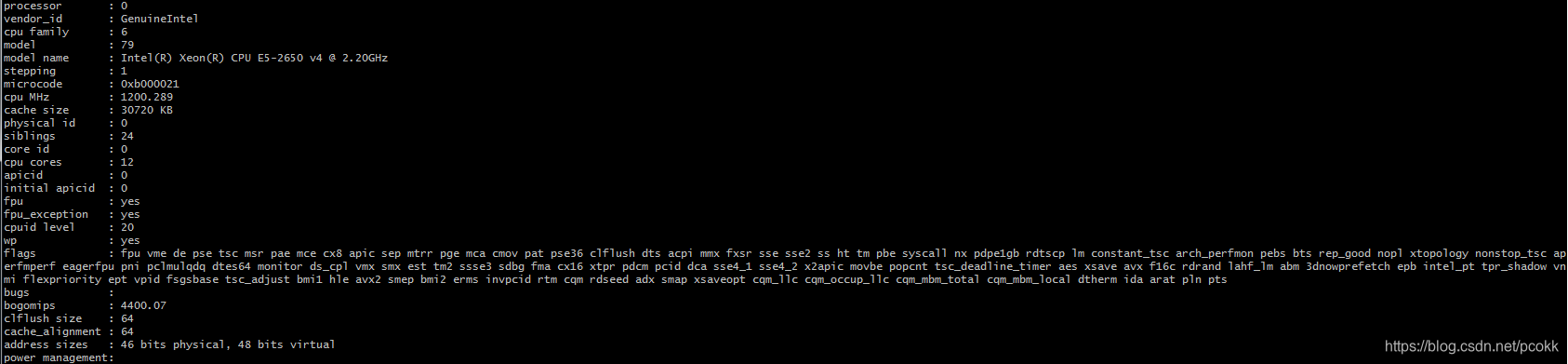
三,初步测试
最初打算寻找一些现有的工具对直接进行测试,测试的结果如下:
1,使用dd命令进行测试,命令如下 :
dd if=/dev/zero of=/dev/shm/A bs=2M count=1024
测试的结果如下 :

显然,2.7GB/s的内存带宽这个结果,是不能令人满意的。
2,使用mbw命令进行测试,命令如下:
mbw 16 -b 4096
测试的结果如下 : (进行了多次测试,其中选取测试结果表现最好)
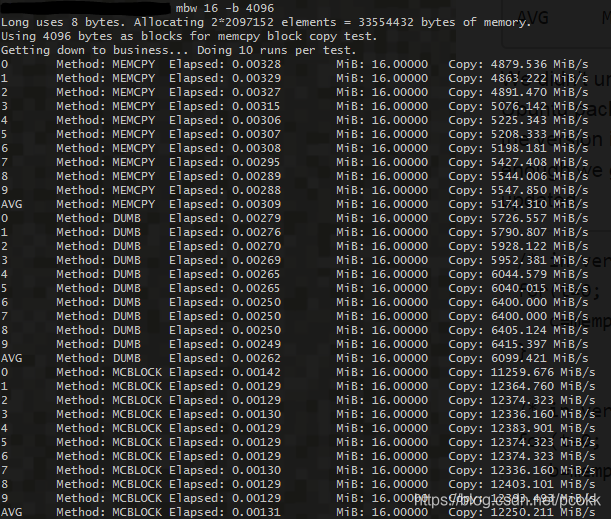
由于mbw使用了三种不同的方式进行了测试 :
(1), 使用memcpy将一个数组复制到另一个数组 :
其avg bandwidth为5.2GB/s,但是由于需要从一个数组复制到另一个,所以应该包括内存读和内存写,假设读写速度一样的话,其avg bandwidth应该为 5.2 * 2 = 10.4GB/s
(2), 使用for循环将一个数组复制到另一个数组 :
同理,可以看出其avg bandwidth为 12.2 GB/s
(3), 使用mempcpy将一个块复制到一个数组 :
由于只是重复地复制一个块,所以可以看做只有内存写操作,故其avg bandwidth为 12.2GB/s
3, 使用sysbench进行测试,测试命令如下
sysbench --test=memory --memory-block-size=4K --memory-totol-size=2G --num-threads=1 run sysbench --test=memory --memory-block-size=4K --memory-totol-size=2G --num-threads=16 run
其中第一个命令使用了1个线程,第二个命令使用了16个线程,测试结果如下 :
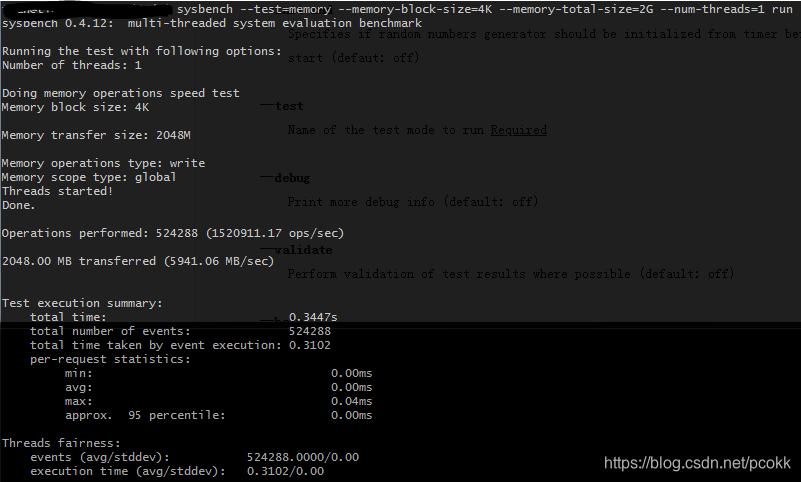
从上图可以看出,单线程的情况下,bindwidth为 5.94GB/s。
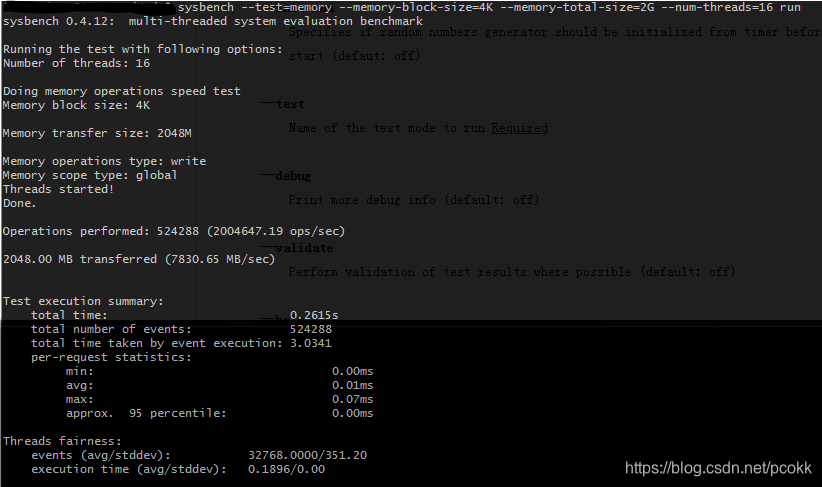
从上图可以看出,多线程的情况下,bindwidth为 7.8 GB/s。
由于目前尚未了解sysbench是将一个块重复复制到一个数组中,还是将一个数组复制到另一个数组中。所以假设是将一个块重复复制,那么其bandwidth在单线程和多线程的情况下分别为5.94GB/s , 7.83GB/s
四,理论峰值
后来和同学的讨论下,可以根据内存条的参数计算bandwidth的峰值,计算如下 :
因为内存条的频率为2400 MHz, 数据宽度为64bit,假设一个时钟周期能进行一次操作的话,那么最高的带宽为 :x=24001000×648=19.2GB/sx = \dfrac{2400}{1000} \times \dfrac{64}{8} = 19.2 GB/sx=10002400×864=19.2GB/s
所以查找到了一些资料[1] [2],打算根据这些资料,自己写一个程序来测试内存的带宽。
五,自行测试
原本打算使用将一个数组复制到另一个数组的方式,但是考虑到这样需要读一遍内存,再写一遍内存,感觉效率比较低。所以采用将一个字符直接写到一个数组中的方法,这样可以认为只有单独的写操作,因为一个字符可能会存放在寄存器或cache中,就无需重复地读取内存。
1,基本的测试函数体如下:
#define G (1024*1024*1024LL) #define NS_PER_S 1000000000.0 #define INLINE inline __attribute__((always_inline)) char src[2*G] __attribute__((aligned(32))); char dst[2*G] __attribute__((aligned(32))); int main(int argc, char* argv[]){ struct timespec start, end; unsigned int length = (unsigned int)2*G; memset(src, 1, length); memset(dst, 0, length); //这两个memset的作用是访问数组后,保证能加载所有的内存页,防止由于缺页中断影响测试的结果 clock_gettime(CLOCK_MONOTONIC, &start); /* * 这里是不同实现的memset函数 */ clock_gettime(CLOCK_MONOTONIC, &end); double timeuse = NS_PER_S * (end.tv_sec - start.tv_sec) + end.tv_nsec - start.tv_nsec; double s = timeuse / NS_PER_S; printf("timeval = %lf, io speed is %lf\n", s, length/G/s); return 0; }
2, 使用memset()测试
编译使用的命令 :
gcc ./memory_io_v4.c -o memory_io -O3 -mavx -mavx2 -msse3 -lrt
1),使用简单的for循环语句:
static INLINE void function_memset_for(char *src, char value, unsigned int length){ for(unsigned int i = 0; i < length; i++) src[i] = value; }
这个函数的结果测试如下:

显然,这结果不能令人满意。
2), 使用CSAPP中第5章提到的k路展开,k路并行(这里使用的k = 4) :
static INLINE void function_memset_k_fold(char *src, char value, unsigned int length){ for(unsigned int i = 0; i < length; i+=4){ src[i] = value; src[i+1] = value; src[i+2] = value; src[i+3] = value; } }
这是函数的测试结果如下:

结果与直接使用for循环的差别不大,原因可能是由于编译器进行优化,但具体还需要研究一下汇编,但是由于没有系统地学过汇编 : -( ,所以还需要进一步探究。。。。
3), 使用操作系统提供的memset()函数 :
static INLINE void function_memset(char *src, char value, unsigned int length){ memset(src, value, length); }
测试结果如下:

可以看出,内存的带宽接近 8 GB/s, 比上面的函数高出许多,但还是不能达不到理想状态。
4), 使用SIMD指令 :
static INLINE void function_memset_SIMD_32B(char *src, char value, unsigned int length){ __m256i *vsrc = (__m256i *)src; __256i ymm0 = _mm256_set_epi8(value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value); unsigned int len = length / 32; for(unsigned int i = 0; i < len; i++) _mm256_storeu_si256(&vsrc[i], ymm0); }
测试结果如下:

可以看出,其性能与直接使用memset()的效果一样。目前猜测其原因是在不同的架构中,这些基本函数都会使用汇编语言进行实现,从而确保更高的性能,所以两者能够达到同样的性能。(这个需要在学完汇编后进一步验证。)。
而且在实验过程中,还分别使用了一次读取64bit, 128bit的SIMD指令,其结果和上面所使用的一次读取256bit的SIMD指令的结果相差不大,这里的原因也需要探究。
5), 根据参考资料[2], 可以使用Non-temporal Instruction,避免一些cache的问题
static INLINE void function_memset_SIMD_s32B(char *src, char value, unsigned int length){ __m256i *vsrc = (__m256i *)src; __m256i ymm0 = _mm256_set_epi8(value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value, value); unsigned int len = length / 32; for(unsigned int i = 0; i < len; i++) _mm256_stream_si256(&vsrc[i], ymm0); }
测试的结果如下 :

可以看出,能够达到了 15.5GB/s 的带宽。
关于为什么相比之前的能达到这么高的bandwidth,请见资料[2]中的解释,具体如下,由于每次写32B,并且每个cache line的大小为32B,也就是如果不使用Non-temporal Instruction, 每次写的时候,先写到cache line中,最后会将cache line写到内存,由于是遍历访问数组,即每次写32B,需要先将数组从内存读到cache line,再写cache line,最后cache line写回内存,相当于每次需要两次内存访问;而使用了Non-temporal Instruction,可以直接写到内存中,这样只需要一次内存访问。即使这样,但是还是不尽人意。
6), 使用rep指令,这里使用与参考资料[2]一样的程序,但是效果却不佳,结果如下 :

涉及汇编指令的东西目前都尚不能解决,需要作进一步探究。
7), 使用Multi-core
关于参考资料中使用Multi-core的实验还未做,因为可能与NUMA架构相关。所以暂且放一放。
六,总结
这篇文章记录了测试内存带宽的过程,包括使用的一些Ubuntu系统的测试工具dd, mbw, sysbench,以及自己根据资料编写的代码,可以看出,最高能到达到一个内存条带宽的80%。
主要存在下面的三个问题还未解决 :
1, 关于一些涉及到汇编指令的测试结果还未能解释。
2, 根据内存条的标签的参数,以及机器的架构(NUMA, dual channel),可以计算出每个内存条的峰值为19.6GB/s, 并且机器是四通道,所以理论上一个Socket能达到的内存峰值为78.4GB/s.有没有什么方法能够利用机器提供的多通道来达到这个内存bandwidth呢?
3,有没有办法到达一个内存条更高的bandwidth,而不只是80%?
关于以上两个问题,如果有大佬能够指点一二,或者提供一些资料,不胜感激。
七,参考资料
[1],SIMD Instructions Official
[2],Achieving maximum memory bandwidth
[3],Testing Memory I/O Bandwidth