什么是缺失值?缺失值指数据集中某些变量的值有缺少的情况,缺失值也被称为NA(not available)值。在pandas里使用浮点值NaN(Not a Number)表示浮点数和非浮点数组中的缺失值,用NaT表示时间序列中的缺失值,此外python内置的None值也会被当作是缺失值。需要注意的是,有些缺失值也会以其他形式出现,比如说用0或无穷大(inf)表示。
缺失值产生的原因: a. 数据采集时发生错误
b. 数据提取过程有问题
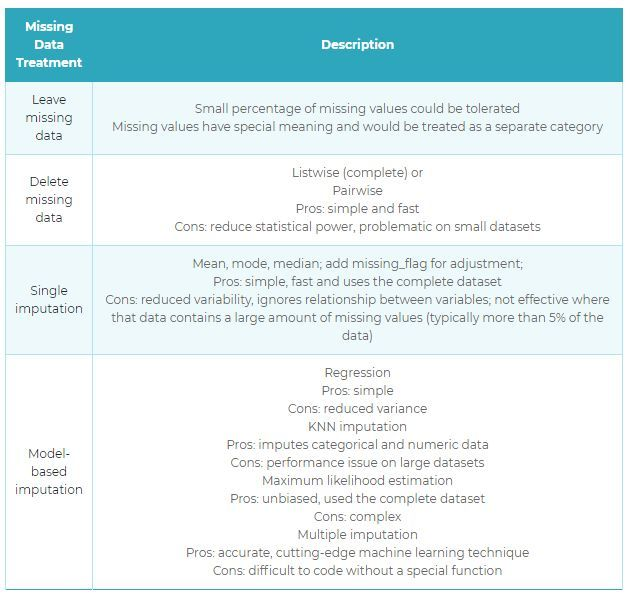
处理缺失值的方法:
1. 直接删除(Deletion):如果缺失值非常少,不影响整体数据,那么可以直接删除整条记录(list-wise deletion)。这种方法的优点是简单,缺点是减少了样本数量。
2. 用标量插补(Single Imputation):如果缺失值比较少,那么可以使用平均值,中位数,众数进行插补。
3. 插值法(Interpolation):先求得插值函数,然后将缺失值对应的点代入插值函数得到缺失值的近似值。常见插值方法有拉格朗日插值法、分段插值法、样条插值法、线性插值法。
4. 用模型预测(Model-based Imputation):通过模型来估计缺失值,是处理缺失值比较复杂的方法。 如果缺失值很多,但是比较适用模型预测。在这种情况下,我们将数据集分为两组:一组没有缺失值,另一组有缺少值。 第一个数据集成为模型的训练数据集,而有缺失值的第二个数据集是测试数据集,有缺失值的变量被视为目标变量。 接下来,我们创建一个模型,根据训练数据集的特征预测目标变量,并填充测试数据集的缺失值。我们可以使用线性回归,随机森林,最近邻法,逻辑回归等各种建模技术来执行此操作。
这种方法有两个缺点:
- 模型的估计值通常比真实值更好
- 如果数据集中的特征与有缺少值的特征之间没有关系,那么模型估计将不精确。
附: