一、单线程的redis为什么这么快
#1、纯内存操作 #2、单线程操作,避免了频繁的上下文切换 #3、采用了非阻塞 I/O 多路复用机制
二、redis的过期策略和内存淘汰机制
# Redis 只能存 5G 数据,可是你写了 10G,那会删 5G 的数据。怎么删的
1、过期策略
#1、为什么不用定时删除策略 #定时删除: 用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源 #2、定期删除+惰性删除 # 2.1定期删除, #Redis默认每隔100ms检查,是否有过期的key,有过期key则删除。 需要说明的是,Redis不是每隔100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,Redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。 #2.2惰性删除 在我们获取某个key的时候,Redis会检查一下,这个key是否设置了过期时间,是否过期,过期了会删除 #2.3定期删除+惰性删除存在的问题 定期删除没删除key。然后我们也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
2、数据(内存)淘汰策略
lru算法
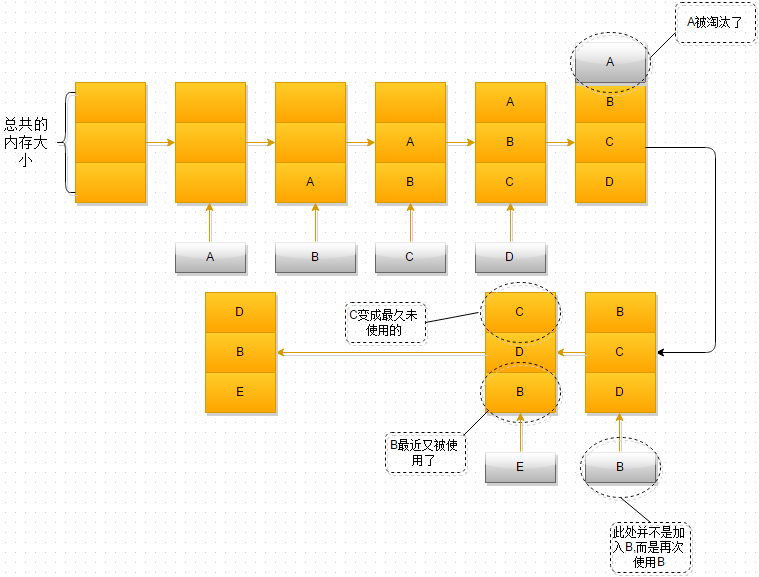
python中的LRU算法
#在redis.conf中有一行配置: maxmemory-policy allkeys-lru #noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错 #allkeys-lru: 当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用。 #allkeys-random: 当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。 #volatile-lru: 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐。 #volatile-random: 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐。 #volatile-ttl: 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐。
三、如何解决redis的并发竞争key问题
#也就是多个子系统去修改同一个key #不推荐使用事务的原因 因为我们的生产环境,基本都是 Redis 集群环境,做了数据分片操作。你一个事务中有涉及到多个 Key 操作的时候,这多个 Key 不一定都存储在同一个 redis-server 上。因此,Redis 的事务机制,十分鸡肋。
解决问题
#1、如果对这个 Key 操作,不要求顺序 这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做 set 操作即可,比较简单。 #2、如果对这个 Key 操作,要求顺序 假设有一个 key1,系统 A 需要将 key1 设置为 valueA,系统 B 需要将 key1 设置为 valueB,系统 C 需要将 key1 设置为 valueC。 期望按照 key1 的 value 值按照 valueA > valueB > valueC 的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。 假设时间戳如下: 系统 A key 1 {valueA 3:00} 系统 B key 1 {valueB 3:05} 系统 C key 1 {valueC 3:10} 那么,假设系统 B 先抢到锁,将 key1 设置为{valueB 3:05}。接下来系统 A 抢到锁,发现自己的 valueA 的时间戳早于缓存中的时间戳,那就不做 set 操作了,以此类推。其他方法,比如利用队列,将 set 方法变成串行访问也可以。