终于到了传说中的异步了,感觉异步这个名字听起来就很酷酷的,以前还不是多擅长Python时,就跑去看twisted的源码,结果给我幼小的心灵留下了创伤。反正包括我在内,都知道异步编程很强大,但是却很少在项目中使用它,我自己使用异步也仅仅是在爬虫当中。而很多人一提到Python中的异步,首先想到的便是gevent,tornado,twisted这些框架。然而异步真的会经常出现问题,首先是编写异步代码难度较大,另一方面是经常会不小心把异步写成同步。因此在使用异步框架,很多人会感觉异步没厉害到哪去啊,其实是用法出现了问题,因此做web开发时,还是会选择Django或者flask。
现在的时代,主要是大数据的时代,但我认为,还是高并发的时代。go语言目前之所以这么火,便是因为其内部的goroutine,使得go语言在语言层面支持高并发,这也是go语言最大的卖点。当然Python也是一样,由Python之父在2013年开始亲自披挂上阵主持了asyncio的开发。
因此在介绍tornado的异步之前,我会先介绍一下Python中的异步以及与相关的知识点
1.什么是异步编程
通过学习相关概念,我们逐步解释异步编程是什么
1.1 阻塞
程序未得到所需计算资源时,被挂起的状态
程序在等待某个操作完成期间,自身无法去干别的事情,则称程序在该操作上是阻塞的
常见的阻塞形式有:网络I/O阻塞,磁盘I/O阻塞,用户输入阻塞等等。
阻塞是无处不在的,包括cpu在切换上下文的时候,所有的进程都无法真正干事情,它们也会被阻塞。如果利用多核,那么正在执行上下文切换的核没有被利用
1.2 非阻塞
程序在等待某个操作完成期间,自身不被阻塞,可以继续干别的事情,则称程序在该操作上是不被阻塞的。
非阻塞并不是在任何程序级别,任何情况都可以存在的
仅当程序封装的级别可以囊括独立的程序子单元时,它才可能存在非阻塞状态。
非阻塞存在是因为阻塞存在,正因为某个阻塞操作导致的耗时与效率低下,所以我们才需要非阻塞。
1.3 同步
不同的程序单元为了完成某个任务,在执行过程中需要靠某种通信方式来协调一致,称这些程序单元是同步执行的。
例如购物系统中更新商品库存,需要使用“行锁”作为通信信号,让不同的更新请求强制排队顺序执行,那么更新库存的操作是同步的
简而言之,同步意味着有序
1.4 异步
为完成某个任务,不同程序单元之间执行过程中无需通信协调,也能完成任务的方式。
不相关的程序单元之间是可以异步的。
主要是有些操作是不耗费CPU的,那么在其处于等待状态,我们可以去执行其它的任务,当不阻塞了再回来执行。
例如,爬虫下载图片。首先要下载器要下载网页,然后spider进行解析图片的URL。然而调度器在调用下载程序之后,即可调度其它任务,而无需和下载器保持通信以协调行为。同理,spider进行解析图片的URL也无需和下载器保持通信。当我们在获取页面,等待服务器响应的这段时间,是阻塞的,那么我们可以利用这段时间来进行spider的解析。不同网页的下载和保存操作都是无关的,也无需相互通知相互协调,因此这些异步操作的完成时刻并不确定。
简而言之,异步意味着无序。
1.5 并发
在同一时间段有多个任务被CPU执行
1.6 并行
在同一时间点有多个任务被CPU执行
1.7 概念总结
并行:充分利用CPU的核数,同时执行多个任务。
并发:让所有的子任务都有机会被执行,因此如果是纯计算,那么当任务数超过CPU核数时,不一定能加速效率,因为要进行切换。但现如今大部分都是I/O操作,当阻塞时我去操作别的。
非阻塞:用于提高程序整体执行效率。
异步:高效的组织非阻塞任务的一种方式。
要保持高并发,必须拆分为多任务,不同任务相对而言,才会有阻塞/非阻塞,同步/异步。所以并发、异步、非阻塞三个词总是出现在一起。比方说异步,之所以用异步,不正是为了实现高并发吗?
1.8 异步编程
以进程、线程、协程、函数/方法作为执行程序的基本单位,结合回调、事件循环、信号量等机制,以提高程序整体执行效率和并发能力的编程方式
如果在某程序运行时,能根据已执行的指令,准确判断它接下来要执行那个具体操作,那它便是同步程序,反之成为异步程序(无序和有序的区别)
同步/异步,阻塞/非阻塞之间并非水火不容,要看程序所处的封装级别。例如购物程序在处理的用户的浏览请求可以是同步的,而更新库存则必须是同步的。
1.9 异步之难与回调之痛
和多线程不一样,线程之间的切换是由操作系统调度的,而协程的切换是由程序员决定的。正是因为如此,我控制不住我自己啊,一旦出了问题,要想找出来bug是非常困难的。同步是顺序执行的,如果出错,可以很快的找出问题。然而异步,要想找出问题,会很麻烦。而且在并行情况下,会更痛苦
所以,几乎所有的异步框架都将异步编程模型简化,因此现在关于异步的讨论都集中了单线程内。
如果某个任务处理需要花费很长的时间,那么其他的部分会被阻塞。
所以一旦采取了异步编程,每个异步调用必须足够小,不能耗时太久,否则其他部分无法执行。那么如何将异步任务进行拆分便成了难题。
程序的下一步的输入往往以来上一步的输出,如何知晓上一步异步调用已完成并获取结果。
因此callback则成了必然的选择,那又要面临回调的折磨。
同步代码改为异步代码,必然会破坏代码结构。
所以程序员更喜欢使用同步的方式,编写异步代码。改变解决问题的逻辑,不要一条路走到黑,要精心安排设计任务。
2.如此煞费苦心于异步,究竟所为哪般?
如上面所述,异步编程面临诸多难点,Python之父亲自上阵打磨4年才使得asyncio模块,在Python3.6中正式转正。如此苦心是为何?因为:值得。让我们看看为什么值得。
2.1 CPU的时间观
我们将一个2.6GHz的CPU 拟人化,如果延迟了0.38纳秒,CPU感觉像是过了1秒。CPU是计算机的处理核心,也是最宝贵的资源,如果有浪费CPU的运行时间,导致其利用率不足,那么程序的效率必然低下,因为实际上还有资源可以使效率更高。
在千兆网传输2KB数据,如果延迟20微妙,CPU感觉过了14.4个小时。从SSD读取1M连续数据,用1毫秒,CPU感觉过了1个月。在这么长的时间里,CPU只能傻等着而不能做其他事情,这岂不是在浪费CPU的青春。
我国的白学家鲁迅也说过:“浪费CPU的时间等于谋财害命,而凶手就是程序员”

2.2 面临的问题
成本问题
如果一个程序不能有效利用一台计算机资源,那必然需要更多的计算机通过运行更多的程序实例来弥补需求缺口。
效率问题
如果不在乎钱的消耗,那也会在意效率问题。当服务器数量堆叠到一定规模后,如果不改进软件架构和实现,加机器是徒劳,而且运维成本会骤然增加。比如别人家的电商平台支持6000单/秒支付,而自家在下单量才支撑2000单/秒,在双十一这种活动的时候,钱送上门也赚不到。
C10k/C10M挑战
C10k(concurrently handling 10k connections)是一个在1999年被提出来的技术挑战,如何在一颗1GHz CPU,2G内存,1gbps网络环境下,让单台服务器同时为1万个客户端提供FTP服务。而到了2010年后,随着硬件技术的发展,这个问题被延伸为C10M,即如何利用8核心CPU,64G内存,在10gbps的网络上保持1000万并发连接,或是每秒钟处理100万的连接。(两种类型的计算机资源在各自的时代都约为1200美元)
成本和效率问题是从企业经营角度讲,C10k/C10M问题则是从技术角度出发挑战软硬件极限。C10k/C10M 问题得解,成本问题和效率问题迎刃而解。2.3 解决方案
《约束理论与企业优化》中指出:“除了瓶颈之外,任何改进都是幻觉。”
CPU告诉我们,它自己很快,而上下文切换慢、内存读数据慢、磁盘寻址与取数据慢、网络传输慢……总之,离开CPU 后的一切,除了一级高速缓存,都很慢。我们观察计算机的组成可以知道,主要由运算器、控制器、存储器、输入设备、输出设备五部分组成。运算器和控制器主要集成在CPU中,除此之外全是I/O,包括读写内存、读写磁盘、读写网卡全都是I/O。I/O成了最大的瓶颈。
异步程序可以提高效率,而最大的瓶颈在I/O,业界诞生的解决方案没出意料:异步I/O吧,异步I/O吧,异步I/O吧!3.协程
协程(Co-routine),即是协作式的例程。
它是非抢占式的多任务子例程的概括,可以允许有多个入口点在例程中确定的位置来控制程序的暂停与恢复执行。
例程是什么?编程语言定义的可被调用的代码段,为了完成某个特定功能而封装在一起的一系列指令。一般的编程语言都用称为函数或方法的代码结构来体现3.1 基于生成器的协程
def func():
yield 1
yield 2
yield 3
yield 4
# 函数里面包含yield,所以被标记为一个生成器
f = func()
print(f.__next__())
print("古明地盆")
print(f.__next__())
'''
1
古明地盆
2
'''可以看到,当遇到了yield就暂停,即便我中间去做别的事情。当我继续运行生成器的时候,还能从当前位置继续前进。还有一个生产者消费者的栗子,也是一个简单的协程。
下面介绍一下函数和生成器的运行原理
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:love_cat
# python的函数是如何工作的
# 比方说我们定义了两个函数
def foo():
bar()
def bar():
pass
# 首先python解释器(python.exe)会用一个叫做PyEval_EvalFrameEx()的C语言函数去执行foo,所以python的代码是运行在C程序之上的
# 当运行foo函数时,会首先创建一个栈帧(stack frame),表示函数调用栈当中的某一帧,相当于一个上下文,函数要在对应的栈帧上运行。
# 正所谓python一切皆对象,栈帧也是一个对象
# python虽然是解释型语言,但在解释之前也要进行一次预编译,编译成字节码对象,然后在对应的栈帧当中运行
# 关于python的编译过程,我们可以是dis模块查看编译后的字节码是什么样子
import dis
print(dis.dis(foo))
# 程序运行结果
'''
13 0 LOAD_GLOBAL 0 (bar)
2 CALL_FUNCTION 0
4 POP_TOP
6 LOAD_CONST 0 (None)
8 RETURN_VALUE
None
'''
# 首先LOAD_GLOBAL,把bar这个函数给load进来
# 然后CALL_FUNCTION,调用bar函数的字节码
# POP_POP,从栈的顶端把元素打印出来
# LOAD_CONST,我们这里没有return,所以会把None给load进来
# RETURN_VALUE,把None给返回
'''
以上是字节码的执行过程
'''
# 过程就是:
'''
1.先预编译,得到字节码对象
2.python解释器去解释字节码
3.当解释到foo函数的字节码时,会为其创建一个栈帧
4.然后调用C函数PyEval_EvalFrameEx()在foo对应的栈帧上执行foo的字节码,参数就是foo对应的栈帧对象
5.当遇到CALL_FUNCTION,也就是在foo中执行到bar的字节码时,会继续为其创建一个栈帧
6.然后把控制权交给新创建的栈帧对象,在bar对应的栈帧中运行bar的字节码
'''
# 我们看到目前已经有两个栈帧了,这不是关键。关键所有的栈帧都分配在堆的内存上,而不是栈的内存上
# 堆内存有一个特点,如果你不去释放,那么它就一直待在那儿。这就决定了栈帧可以独立于调用者存在
# 即便调用者不存在,或者函数退出了也没有关系,因为它始终在内存当中。只要有指针指向它,我们就可以对它进行控制
# 这个特性决定了我们对函数的控制会相当精确。# 我们可以改写这个函数
# 在此之前,我们要引用一个模块inspect,可以获取栈帧
import inspect
frame = None
def foo():
bar()
def bar():
global frame
frame = inspect.currentframe() # 将获取到的栈帧对象赋给全局变量
foo()
# 此时函数执行完毕,但是我们依然可以拿到栈帧对象
# 栈帧对象一般有三个属性
# 1.f_back,当前栈帧的上一级栈帧
# 2.f_code,当前栈帧对应的字节码
# 3.f_locals,当前栈帧所用的局部变量
print(frame.f_code)
print(frame.f_code.co_name)
'''
<code object bar at 0x000000000298C300>
bar
'''
# 可以看出,打印的是我们bar这个栈帧
# 之前说过,栈帧可以独立于调用方而存在
# 我们也可以拿到foo的栈帧,也就是bar栈帧的上一级栈帧
foo_frame = frame.f_back
print(foo_frame.f_code)
print(foo_frame.f_code.co_name)
'''
<code object foo at 0x000000000239C8A0>
foo
'''
# 我们依然可以拿到foo的栈帧
# 总结一下:就是有点像递归。遇见新的调用,便创建一个新的栈帧,一层层地创建,然后一层层地返回关于类似于递归这个现象,我们可以看一张图
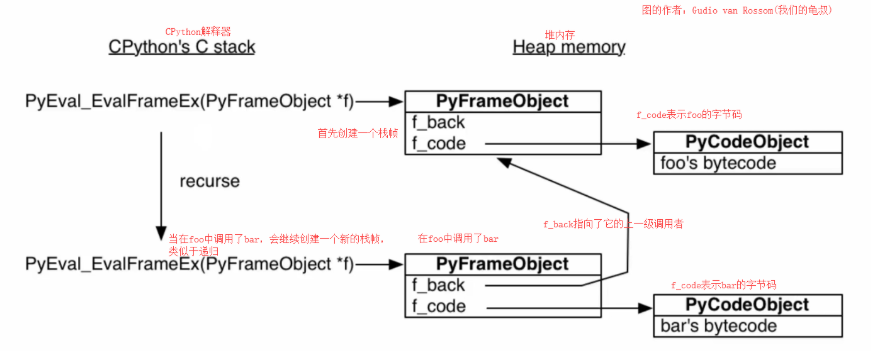
生成器的运行原理
# 我们之前说了,栈帧是分配在堆内存上的
# 正是因为如此,生成器才有实现的可能
# 我们定义一个生成器
def gen_func():
yield 123
name = "satori"
yield 456
age = 18
return "i love satori" # 注意在早期的版本中生成器是不允许有返回值的,但在后来的版本中,允许生成器具有返回值
# python解释之前,也进行预编译,在编译的过程中,发现有yield,就已经被标记为生成器了如何实现的呢?实际上是对PyFrameObject做了一层封装

def gen_func():
yield 123
name = "satori"
yield 456
age = 18
return "i love satori"
import dis
gen = gen_func()
print(dis.dis(gen))
'''
2 0 LOAD_CONST 1 (123)
2 YIELD_VALUE
4 POP_TOP
3 6 LOAD_CONST 2 ('satori')
8 STORE_FAST 0 (name)
4 10 LOAD_CONST 3 (456)
12 YIELD_VALUE
14 POP_TOP
5 16 LOAD_CONST 4 (18)
18 STORE_FAST 1 (age)
6 20 LOAD_CONST 5 ('i love satori')
22 RETURN_VALUE
None
'''
# 可以看到,结果中有两个yield,因为我们的函数中有两个yield
# 最后的LOAD_CONST后面的('i love satori'),表示我们的返回值
# 最后RETURN_VALUE
# 前面的图也解释了,gi_frame的f_lasti会记录最近的一次执行状态,gi_locals会记录当前的局部变量
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
'''
-1
{}
'''
# 我们创建了生成器,但是还没有执行,所以值为-1,当前局部变量也为空
# 我们next一下
next(gen)
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
'''
2
{}
'''
# 我们发现数字是2,所以指向第二行,YIELD_VALUE,yield的值就是123
# 此时局部变量依旧为空
# 继续next,会执行到第二个yield的位置
next(gen)
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
'''
12
{'name': 'satori'}
'''
# 数字是12,所以指向第十二行,第二个YIELD_VALUE,yield的值就是456
# 此时name="satori",被添加到了局部变量当中
# 因此到这里便更容易理解了,为什么生成器可以实现了。
# 因为PyGenObject对函数的暂停和前进,进行了完美的监督,有变量保存我最近一行代码执行到什么位置
# 再通过yield来暂停它,就实现了我们的生成器
# 跟函数一样,我们的生成器对象也是分配在堆内存当中的,可以像函数的栈帧一样,独立于调用者而存在
# 我们可以在任何地方去调用它,只要我们拿到这个栈帧对象,就可以控制它继续往前走
# 正是因为可以在任何地方控制它,才会有了协程这个概念,这是协程能够实现的理论基础
# 因为有了f_lasti,生成器知道下次会在什么地方执行,不像函数,必须要一次性运行完毕
# 以上就是生成器的运行原理3.2 gevent中的协程
import gevent
from gevent import monkey
monkey.patch_all()
import time
def func(n):
time.sleep(3)
print(n)
st_time = time.time()
gevent.joinall([
gevent.spawn(func, 1),
gevent.spawn(func, 2),
gevent.spawn(func, 3),
gevent.spawn(func, 4),
gevent.spawn(func, 5),
gevent.spawn(func, 6),
gevent.spawn(func, 7),
])
end_time = time.time()
print("总耗时:", end_time - st_time)
'''
1
2
3
4
5
6
7
总耗时: 3.0030035972595215
'''
import gevent
from gevent import monkey
from gevent.pool import Pool
monkey.patch_all()
import time
def func(n):
time.sleep(3)
print(n)
pool = Pool(10)
st_time = time.time()
gevent.joinall([pool.spawn(func, n) for n in range(50)])
end_time = time.time()
print("总耗时:", end_time - st_time)
'''
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
总耗时: 15.011604309082031
'''
# 由于池子最多可以容纳10个协程,可以看到每隔三秒打印10个数字,因此总用时15秒
gevent是基于greenlet实现的,而greenlet实现的关键就是通过栈数据的拷贝、栈指针的位移来实现协程之间的切换。gevent不多做介绍,这个模块打猴子补丁,把Python内置的socket、ssl等全给改了,可以当做历史去了解
3.3 asyncio中的协程
asyncio是Python在3.5中正式引入的标准库,这是Python未来的并发编程的主流,非常重要的一个模块
asyncio模块提供了使用协程构建并发应用的工具。
threading模块通过应用线程实现并发,multiprocessing使用系统进程实现并发,asyncio使用一种单线程、单进程模式实现并发,应用的各个部分会彼此合作,在最优的时刻显式的切换任务。
大多数情况下,会在程序阻塞等待读写数据时发生这种上下文切换,不过asyncio也支持调度代码在将来的某个特定时间运行,从而支持一个协程等待另一个协程完成,以处理系统信号和识别其他一些事件(这些事件可能导致应用改变其工作内容)
asyncio中,有几个非常重要的概念
coroutine 协程:协程对象,指一个使用async关键字定义的函数,它的调用不会立即执行函数,而是会返回一个协程对象。协程对象需要注册到事件循环,由事件循环调用。future 未来对象:在asyncio中,如何才能得知异步调用的结果呢?先设计一个对象,异步调用执行完的时候,就把结果放在它里面。这种对象称之为未来对象。未来对象有一个result属性,用于存放未来的执行结果。还有个set_result()方法,是用于设置result的。task 任务:一个协程对象就是一个原生可以挂起的函数,任务则是对协程进一步封装,其中包含任务的各种状态。event_loop 事件循环:程序开启一个无限的循环,程序员会把一些函数注册到事件循环上。当满足事件发生的时候,调用相应的协程函数。async/await 关键字:python3.5 用于定义协程的关键字,async定义一个协程,await用于挂起阻塞的异步调用接口。
3.3.1 异步并发概念
使用其他并发模型的大多数程序都采用线性方式编写,而且依赖于语言运行时系统或操作系统的底层线程或进程管理来适当地改变上下文。
基于asyncio的应用要求应用代码显式地处理上下文切换,要正确地使用相关技术,这取决于是否能正确理解一些相关联的概念。
asyncio提供的框架以一个事件循环(event loop)为中心,这是一个首类对象,负责高效地处理I/O事件、系统事件、和应用上下文切换。
目前已经提供了多个循环实现来高效地利用操作系统的功能。尽管通常会自动选择一个合理的默认实现,但也完全可以在应用中选择某个特定的事件循环实现。
在很多情况下都很有用,例如:在Windows下,一些循环类增加了对外部进程的支持,这可能会以牺牲一些网络I/O效率为代价
与事件循环交互的应用要显式地注册将运行的代码,让事件循环在资源可用时向应用代码发出必要的调用。
例如:一个网络服务器打开套接字,然后注册为当这些套接字上出现输入事件时服务器要得到的通知。
事件循环在建立一个新的进入链接或者在数据可读取时都会提醒服务器代码。当前上下文中没有更多工作可做时,应用代码要再次短时间地交出控制权。
例如:如果一个套接字没有更多的数据可以接收,那么服务器会把控制权交给事件循环
所以,就是把代码注册到事件循环中,不断地循环这些事件,可以处理了那么就去处理,如果卡住了,那么把控制权交给事件循环,继续执行其他可执行的任务。
像传统的twisted、gevent、以tornado,都是采用了事件循环的方式,这种模式只适用于高I/O,低CPU的场景,一旦出现了耗时的复杂运算,那么所有任务都会被卡住。
将控制权交给事件循环的机制依赖于协程(coroutine),这是一些特殊的函数,可以将控制返回给调用者而不丢失其状态。
协程与生成器非常类似,实际上,在python3.5版本之前还未对协程提供原生支持时,可以用生成器来实现协程。
asyncio还为协议(protocol)和传输(transport)提供了一个基于类的抽象层,可以使用回调编写代码而不是直接编写协程。
在基于类的模型和协程模型时,可以通过重新进入事件循环显式地改变上下文,以取代python多线程实现中隐式的上线文改变
3.3.2 利用协程合作完成多任务
import asyncio
'''
协程是一个专门设计用来实现并发操作的语言构造。
调用协程函数时会创建一个协程对象,然后调用者使用协程的send方法运行这个函数的代码。协程可以使用await关键字(并提供另一个协程)暂停执行。
暂停时,这个协程的状态会保留,使得下一次被唤醒时可以从暂停的地方恢复执行
'''
# 使用async def可以直接定义一个协程
async def coroutine():
print("in coroutine")
# 创建事件循环
loop = asyncio.get_event_loop()
try:
print("start coroutine")
# 协程是无法直接运行的,必须要扔到事件循环里,让事件循环驱动运行
coro = coroutine()
print("entering event loop")
# 必须扔到事件循环里,这个方法的含义从名字也能看出来,直到协程运行完成
loop.run_until_complete(coro)
finally:
print("closing event loop")
# 关闭事件循环
loop.close()
'''
start coroutine
entering event loop
in coroutine
closing event loop
'''
# 第一步是得到事件循环的引用。
# 可以使用默认地循环类型,也可以实例化一个特定的循环类。
# run_until_complete方法启动协程,协程退出时这个方法会停止循环
当协程有返回值的时候
import asyncio
'''
我们也可以获取协程的返回值
'''
async def coroutine():
print("in coroutine")
return "result"
loop = asyncio.get_event_loop()
try:
coro = coroutine()
result = loop.run_until_complete(coro)
print(result)
finally:
loop.close()
'''
in coroutine
result
'''
# 在这里,run_until_complete还会返回它等待的协程的结果
import asyncio
'''
一个协程还可以驱动另一个协程并等待结果,从而可以更容易地将一个任务分解为可重用的部分。
'''
async def worker():
print("worker....")
# 使用await方法会驱动协程consumer执行,并得到其返回值
res = await consumer()
print(res)
async def consumer():
return "i am consumer"
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(worker())
finally:
loop.close()
'''
worker....
i am consumer
'''
# 在这里,使用await关键字,而不是向循环中增加新的协程。因为控制流已经在循环管理的一个协程中,所以没必要告诉循环管理这些协程。
# 另外,协程可以并发运行,但前提是多个协程。这个协程卡住了,可以切换到另一个协程。但是就卡住的协程本身来说,该卡多长时间还是多长时间,不可能说跳过卡住的部分执行下面的代码。
import asyncio
'''
协程函数时asyncio设计中的关键部分。
它们提供了一个语言构造,可以停止程序某一部分的执行,保留这个调用的状态,并在以后重新进入这个状态,这些动作都是并发框架很重要的功能。
python3.5中引入了一些新的语言特性,可以使用async def以原生方式定义这些协程,以及使用await交出控制,asyncio的例子应用了这些新特性。
但是早期版本,可以使用asyncio.coroutine装饰器将函数装饰成一个协程并使用yield from来达到同样的效果。
'''
@asyncio.coroutine
def worker():
print("worker....")
res = yield from consumer()
print(res)
@asyncio.coroutine
def consumer():
return "i am consumer"
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(worker())
finally:
loop.close()
'''
worker....
i am consumer
'''
# 尽管使用生成器可以达到同样的效果,但还是推荐使用async和await
'''
生成器既可以做生成器,又可以包装为协程,那么它到底是协程还是生成器呢?这会使得代码出现混乱
生成器应该做自己
基于async的原生协程比使用yield装饰器的协程要快,大概快10-20%
'''
3.3.3 调度常规函数调用
call_soon
import asyncio
from functools import partial
'''
除了管理协程和I/P回调,asyncio事件循环还可以根据循环中保存的一个定时器值来调度常规函数调用。
'''
# 如果回调的时间不重要,那么可以使用call_soon调度下一次循环迭代的调用
def callback(*args, **kwargs):
print("callback:", args, kwargs)
async def main(loop):
print("register callback")
# 接收一个回调函数,和参数
loop.call_soon(callback, "mashiro", 16)
print("********")
# 如果是关键字参数是不能直接传的,需要使用偏函数转换一下
wrapped = partial(callback, kwargs={"name": "satori", "age": 16})
loop.call_soon(wrapped, "mahsiro", 16)
print("—————————")
await asyncio.sleep(0.6)
event_loop = asyncio.get_event_loop()
try:
print("entering event loop")
event_loop.run_until_complete(main(event_loop))
finally:
print("closing event loop")
event_loop.close()
'''
entering event loop
register callback
********
—————————
callback: ('mashiro', 16) {}
callback: ('mahsiro', 16) {'kwargs': {'name': 'satori', 'age': 16}}
closing event loop
'''
# 可以看到,call_soon调用callback是最后执行的,为什么?因为call_soon虽然是立刻调用,但实际上是出现io才立刻调用
# 比如这里的asyncio.sleep,当call_soon把回调函数注册进去了之后,不会马上调用,当出现asyncio.sleep这种io阻塞之后才会调用
call_later
import asyncio
from functools import partial
'''
要将回调推迟到将来的某个时间调用,可以使用call_later。这个方法的第一个参数是延迟时间(单位为秒),第二个参数是回调。
'''
def callback(cb, n):
print(f"{cb} {n}")
async def main(loop):
print("register callback")
loop.call_later(0.2, callback, "call_later", "0.2s")
loop.call_later(0.1, callback, "call_later", "0.1s")
loop.call_soon(callback, "call_soon", 3)
print("-----------")
await asyncio.sleep(0.6)
event_loop = asyncio.get_event_loop()
try:
print("entering event loop")
event_loop.run_until_complete(main(event_loop))
finally:
print("closing event loop")
event_loop.close()
'''
entering event loop
register callback
-----------
call_soon 3
call_later 0.1s
call_later 0.2s
closing event loop
'''
# 可以看到,call_soon调用callback的延迟是最小的,当我们遇见了asyncio.sleep的时候,自动切换,瞬间执行。
# 对于call_later来说,也是一样的,必须要遇见异步io阻塞,比如asyncio.sleep,才会触发执行,但是计时是从注册回调的那一刻就开始了。
# 比如call_later中注册了5秒,遇见asyncio.sleep(5)的时候,过了2秒,那么对了call_later的回调来讲的话,再过3秒就可以执行了。
# 但是如果是asyncio.sleep(2)的话,那么当sleep结束的时候,总共过了4秒,而回调中注册是5秒
# 那么不好意思,程序会继续往下走,直到出现下一个异步io阻塞,但是对于call_soon和call_later来说,call_soon永远是先于call_later执行。
import asyncio
def callback(cb, n):
print(f"{cb} {n}")
async def main(loop):
print("register callback")
loop.call_later(5, callback, "call_later", "5s")
loop.call_later(4, callback, "call_later", "4s")
loop.call_soon(callback, "call_soon", 3)
import time
time.sleep(2)
print("-------")
await asyncio.sleep(2)
print("xxxxx")
time.sleep(2)
print("aaa")
await asyncio.sleep(1)
event_loop = asyncio.get_event_loop()
try:
print("entering event loop")
event_loop.run_until_complete(main(event_loop))
finally:
print("closing event loop")
event_loop.close()
'''
entering event loop
register callback
-------
call_soon 3
call_later 4s
xxxxx
aaa
call_later 5s
closing event loop
'''
# 分析一下执行结果
# 首先打印entering event loop和register callback无序解释
# 然后loop.call_later和loop.call_soon注册回调函数
# time.sleep(2)的时候会卡在这里,这虽然是阻塞,但不是可以异步化的阻塞。
# time.sleep之后,打印------
# 然后下面遇到了await asyncio.sleep(2),这是一个异步化的阻塞,因此协程会切换,去执行回调
# 首先执行call_later
# 然后由于一开始过了两秒,然后asyncio.sleep(2),总共4秒,那么对于第二个注册的call_later会执行
# 但是第一个call_later由于是5秒,所以暂时不会执行
# 然后程序打印xxxxx,然后程序又time.sleep(2),但这不是异步化的阻塞,所以不会切换,尽管此时总共已经超过5秒了
# 然后打印aaa,再往下遇见了异步io阻塞,所以会执行第一个call_later注册的回调,那么会立刻执行。
call_at
import asyncio
import time
'''
除了call_soon瞬间执行,和call_later延迟执行之外,还有一个call_at在指定之间内执行。
实现这个目的的循环依赖于一个单调时钟,而不是墙上的时钟时间,以确保now时间绝对不会逆转。
要为一个调度回调选择时间,必须使用循环的time方法从这个时钟的内部开始
'''
def callback(cb, loop):
print(f"callback {cb} invoked at {loop.time()}")
async def main(loop):
now = loop.time()
print("clock time:", time.time())
print("loop time:", now)
print("register callback")
loop.call_at(now + 0.2, callback, "call_at", loop)
loop.call_at(now + 0.1, callback, "call_at", loop)
loop.call_soon(callback, "call_soon", loop)
sum = 0
for i in range(99999999):
sum += i
print("sum =", sum)
print("是先打印我呢?还是先执行call_at或者call_sonn呢")
await asyncio.sleep(1)
event_loop = asyncio.get_event_loop()
try:
print("entering event loop")
event_loop.run_until_complete(main(event_loop))
finally:
print("closing event loop")
event_loop.close()
'''
entering event loop
clock time: 1565322635.1268628
loop time: 94965.984
register callback
sum = 4999999850000001
是先打印我呢?还是先执行call_at或者call_sonn呢
callback call_soon invoked at 94970.656
callback call_at invoked at 94970.656
callback call_at invoked at 94970.656
closing event loop
'''
# 首先call_soon无序解释,只有当出现了异步io阻塞才会立刻调用
# call_at本来是在0.2s之后执行的,但是当中出现了复杂的运算,所以计算时间往后推迟了,但是当计算结束之后没有执行call_at,而是执行下一个print
# 说明call_at和call_soon和call_later一样也是在遇到类似于asyncio.sleep之类的异步io阻塞之后才会触发。
3.3.4 异步的生成结果
import asyncio
import time
'''
Future表示还未完成的工作的结果。事件循环可以通过监视一个Future对象的状态来指示它已经完成,从而允许应用的一部分等待另一部分完成一些工作。
'''
# Future的做法类似于协程,所以等待协程所用的技术同样可以用于等待Future。
def mark_done(future, result):
print("setting result")
future.set_result(result)
event_loop = asyncio.get_event_loop()
try:
all_done = asyncio.Future()
print("sceduling mark_done")
event_loop.call_soon(mark_done, all_done, "the result")
print("entering loop")
event_loop.run_until_complete(all_done)
finally:
print("close loop")
event_loop.close()
print("future result:", all_done.result())
'''
sceduling mark_done
entering loop
setting result
close loop
future result: the result
'''
# 调用set_result时,Future的状态改为完成,Future实例会保留提供给方法的结果,以备后续获取
future = asyncio.Future()
# 设置只能设置一次
future.set_result("xxx")
# 但是取可以取多次
print(future.result()) # xxx
print(future.result()) # xxx
print(future.result()) # xxx
print(future.result()) # xxx
print(future.result()) # xxx
import asyncio
import time
'''
Future还可以结合await关键字使用
'''
def mark_done(future, result):
print("setting result")
future.set_result(result)
async def main(loop):
all_done = asyncio.Future()
print("scheduling mark_done")
loop.call_soon(mark_done, all_done, "the result")
# 会等到all_done这个Future对象里面有值位置
res = await all_done
print("res =", res)
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
'''
scheduling mark_done
setting result
res = the result
'''
# Future的结果由await返回,所以经常会让同样的代码处理一个常规的协程和一个Future实例
import asyncio
import functools
'''
除了做法与协程类似,Future也可以调用回调,回调的顺序按照其注册的顺序调用
'''
def callback(future, n):
print(f"future result: {future.result()} n:{n}")
async def register_callback(all_done):
print("register callback on futures")
all_done.add_done_callback(functools.partial(callback, n=1))
all_done.add_done_callback(functools.partial(callback, n=2))
async def main(all_done):
await register_callback(all_done)
print("setting result of future")
all_done.set_result("the result")
event_loop = asyncio.get_event_loop()
try:
all_done = asyncio.Future()
event_loop.run_until_complete(main(all_done))
finally:
event_loop.close()
'''
register callback on futures
setting result of future
future result: the result n:1
future result: the result n:2
'''
3.3.5 并发地执行任务
import asyncio
'''
任务是与事件循环交互的主要途径之一。
任务可以包装协程,并跟踪协程何时完成。
由于任务是Future的子类,所以其他协程可以等待任务,而且每个任务可以有一个结果,在它完成时可以获取这些结果
'''
# 启动一个任务,可以使用create_task函数创建一个Task实例。
# 只要循环还在运行而且协程没有返回,create_task得到的任务便会作为事件循环管理的并发操作的一部分运行
async def task_func():
print("in task func")
return "the result"
async def main(loop):
print("creating task")
task = loop.create_task(task_func())
print(f"wait for {task}")
return_value = await task
print(f"task completed {task}")
print(f"return value {return_value}")
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
'''
creating task
wait for <Task pending coro=<task_func() running at 5.asyncio.py:13>>
in task func
task completed <Task finished coro=<task_func() done, defined at 5.asyncio.py:13> result='the result'>
return value the result
'''
# 一开始task是pending状态,然后执行结束变成了done
# 这个Task是Futrue的子类,await task得到的就是任务task的返回值。
# future.set_result的时候,就代表这个Future对象已经完成了,可以调用注册的回调函数了
# 那么Task对象也是一样,当这个协程已经return了,就代表这个协程完成了,那么return的值就类似于set_result设置的值
# Task在注册回调,调用相应的回调函数的时候,也可以通过task.result方法获取返回值。
# 那么同理和Future对象一样,使用await Task()也可以直接获取返回值
import asyncio
'''
通过create_task可以创建对象,那么也可以在任务完成前取消操作
'''
async def task_func():
print("in task func")
return "the result"
async def main(loop):
print("creating task")
task = loop.create_task(task_func())
print("canceling task")
task.cancel()
print(f"canceled task: {task}")
try:
await task
except asyncio.CancelledError:
print("caught error from canceled task")
else:
print(f"task result: {task.result()}")
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
import asyncio
'''
ensure_future函数返回一个与协程执行绑定的Task。
这个Task实例再传递到其他代码,这个代码可以等待这个实例,而无须知道原来的协程是如何构造或调用的
'''
async def task_func():
print("in task func")
return "the result"
async def main(loop):
print("creating task")
task = asyncio.ensure_future(task_func())
print(f"return value: {await task}")
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
'''
creating task
in task func
return value: the result
'''
3.3.6 组合协程和控制结构
1.等待多个协程
import asyncio
'''
一系列协程之间的线性控制流用内置的await可以很容易地管理。
更复杂的结构可能允许一个协程等待多个其他协程并行完成,可以使用asyncio中的工具创建这些更复杂的结构
通常可以把一个操作划分为多个部分,然后分别执行,这会很有用。
例如:采用这种方法,可以高效的下载多个远程资源或者查询远程API。
有些情况下,执行顺序并不重要,而且可能有任意多个操作,这种情况下,可以使用wait函数暂停一个协程,直到其他后台操作完成
'''
async def phase(i):
print(f"in phase {i}")
await asyncio.sleep(0.1 * i)
print(f"done with phase {i}")
return f"phase {i} result"
async def main():
print("start main")
phases = [phase(i) for i in range(3)]
print("waiting for phases to complete")
# 可以await 一个协程,但如果是多个协程呢?可以将其组合成一个列表,然后交给asyncio.wait函数,再对其进行await,就可以等所有的协程了
# 会有两个返回值,一个是已完成的任务,一个是未完成的任务
completed, pending = await asyncio.wait(phases)
print(f"results: {[t.result() for t in completed]}")
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main())
finally:
event_loop.close()
'''
start main
waiting for phases to complete
in phase 1
in phase 0
in phase 2
done with phase 0
done with phase 1
done with phase 2
results: ['phase 1 result', 'phase 0 result', 'phase 2 result']
'''
# 可以看到顺序貌似乱了,这是因为在内部,wait函数使用一个set来保存它创建的Task实例,这说明这些实例会按一种不可预知的顺序启动和完成。
2.从协程收集结果
import asyncio
'''
如果后台阶段是明确的,而且这些阶段的结果很重要,那么gather方法可能对等待多个操作很有用
'''
async def phase(i):
print(f"in phase {i}")
await asyncio.sleep(0.1 * i)
print(f"done with phase {i}")
return f"phase {i} result"
async def main():
print("start main")
phases = [phase(i) for i in range(3)]
print("waiting for phases to complete")
# 当使用gather的时候,内部直接传入多个任务即可
# 所以我们还要将列表进行打散
# 并且和wait不一样,返回值不再是任务,而是任务的返回值,而且是完成的任务的返回值。
# 正因为是返回值,所以只有一个,并且顺序和我们添加任务的顺序是一致的
# 不管后台是怎么执行了,返回值得顺序和我们添加任务的顺序保持一致
completed = await asyncio.gather(*phases)
print(f"results: {[t for t in completed]}")
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main())
finally:
event_loop.close()
'''
start main
waiting for phases to complete
in phase 0
in phase 1
in phase 2
done with phase 0
done with phase 1
done with phase 2
results: ['phase 0 result', 'phase 1 result', 'phase 2 result']
'''
import asyncio
async def task1():
return "task1"
async def task2():
return "task2"
async def task3():
return "task3"
tasks = [task1(), task2(), task3()]
event_loop = asyncio.get_event_loop()
try:
completed, pending = event_loop.run_until_complete(asyncio.wait(tasks))
finally:
event_loop.close()
for t in completed:
print(t.result())
'''
task2
task3
task1
'''
import asyncio
async def task1():
return "task1"
async def task2():
return "task2"
async def task3():
return "task3"
tasks = [task1(), task2(), task3()]
event_loop = asyncio.get_event_loop()
try:
completed = event_loop.run_until_complete(asyncio.gather(*tasks))
finally:
event_loop.close()
for t in completed:
print(t)
'''
task1
task2
task3
'''
3.后台操作完成时进行处理
import asyncio
'''
as_completed函数是一个生成器,会管理指定的一个协程列表,并生成它们的结果,每个协程结束运行时一次生成一个结果。
与wait类似,as_completed不能保证顺序,从名字也能看出来,哪个先完成哪个先返回
'''
async def task1():
print("我是task1,我睡了3秒")
await asyncio.sleep(3)
print("我是task1,睡完了")
return "task1"
async def task2():
print("我是task2,我睡了1秒")
await asyncio.sleep(1)
print("我是task2,睡完了")
return "task2"
async def task3():
print("我是task3,我睡了2秒")
await asyncio.sleep(2)
print("我是task3,睡完了")
return "task3"
async def main():
print("start main")
tasks = [task1(), task2(), task3()]
for task in asyncio.as_completed(tasks):
res = await task
print(res)
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main())
finally:
event_loop.close()
'''
start main
我是task3,我睡了2秒
我是task2,我睡了1秒
我是task1,我睡了3秒
我是task2,睡完了
task2
我是task3,睡完了
task3
我是task1,睡完了
task1
'''
3.3.7同步原语
尽管asyncio应用通常作为单线程的进程运行,不过仍被构建为并发应用。
由于I/O以及其他外部事件的延迟和中断,每个协程或任务可能按照一种不可预知的顺序执行。
为了支持安全的并发执行,asyncio包含了threading和multiprocessing模块中一些底层原语的实现
1.锁
import asyncio
'''
Lock可以用来保护对一个共享资源的访问,只有锁的持有者可以使用这个资源。
如果有多个请求要得到这个锁,那么其将会阻塞,以保证一次只有一个持有者
'''
def unlock(lock):
print("回调释放锁,不然其他协程获取不到。")
print("但我是1秒后被调用,锁又在只能通过调用我才能释放,所以很遗憾,其他协程要想执行,至少要1秒后了")
lock.release()
async def coro1(lock):
print("coro1在等待锁")
# 使用async with语句很方便,是一个上下文。相当于帮我们自动实现了开始的lock.acquire和结尾lock.release
async with lock:
print("coro1获得了锁")
print("coro1释放了锁")
async def coro2(lock):
print("coro2在等待锁")
async with lock:
print("coro2获得了锁")
print("coro2释放了锁")
async def main(loop):
# 创建共享锁
lock = asyncio.Lock()
print("在开始协程之前创建一把锁")
await lock.acquire()
print("锁是否被获取:", lock.locked())
# 执行回调将锁释放,不然协程无法获取锁
loop.call_later(1, unlock, lock)
# 运行想要使用锁的协程
print("等待所有协程")
await asyncio.wait([coro1(lock), coro2(lock)])
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
'''
在开始协程之前创建一把锁
锁是否被获取: True
等待所有协程
coro2在等待锁
coro1在等待锁
回调释放锁,不然其他协程获取不到。
但我是1秒后被调用,锁又在只能通过调用我才能释放,所以很遗憾,其他协程要想执行,至少要1秒后了
coro2获得了锁
coro2释放了锁
coro1获得了锁
coro1释放了锁
'''
2.事件
import asyncio
'''
asyncio.Event基于threading.Event。它允许多个消费者等待某个事件发生,而不必寻找一个特定值与关联
首先Event对象可以使用set,wait,clear
set:设置标志位
wait:等待,在没有set的情况下,会阻塞。如果set之后,不会阻塞。
clear:清空标志位
'''
def set_event(event):
print("设置标志位,因为协程会卡住,只有设置了标志位才会往下走")
print("但我是一秒后才被调用,所以协程想往下走起码也要等到1秒后了")
event.set()
async def coro1(event):
print("coro1在这里卡住了,快设置标志位啊")
await event.wait()
print(f"coro1飞起来了,不信你看现在标志位,是否设置标志位:{event.is_set()}")
async def coro2(event):
print("coro2在这里卡住了,快设置标志位啊")
await event.wait()
print(f"coro2飞起来了,不信你看现在标志位,是否设置标志位:{event.is_set()}")
async def main(loop):
# 创建共享事件
event = asyncio.Event()
# 现在设置标志位了吗?
print("是否设置标志位:", event.is_set())
# 执行回调将标志位设置,不然协程卡住了
loop.call_later(1, set_event, event)
# 运行卡住的的协程
print("等待所有协程")
await asyncio.wait([coro1(event), coro2(event)])
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
'''
是否设置标志位: False
等待所有协程
coro1在这里卡住了,快设置标志位啊
coro2在这里卡住了,快设置标志位啊
设置标志位,因为协程会卡住,只有设置了标志位才会往下走
但我是一秒后才被调用,所以协程想往下走起码也要等到1秒后了
coro1飞起来了,不信你看现在标志位,是否设置标志位:True
coro2飞起来了,不信你看现在标志位,是否设置标志位:True
'''
# asyncio里面的事件和threading里面的事件的API是一致的。
3.队列
import asyncio
'''
asyncio.Queue为协程提供了一个先进先出的数据结构,这与线程的queue.Queue或者进程里面的Queue很类似
'''
async def consumer(q: asyncio.Queue, n):
print(f"消费者{n}号 开始")
while True:
item = await q.get()
print(f"消费者{n}号: 消费元素{item}")
# 由于我们要开启多个消费者,为了让其停下来,我们添加None作为停下来的信号
if item is None:
# task_done是什么意思?队列有一个属性,叫做unfinished_tasks
# 每当我们往队列里面put一个元素的时候,这个值就会加1,
# 并且队列还有一个join方法,表示阻塞,什么时候不阻塞呢?当unfinished_tasks为0的时候。
# 因此我们每put一个元素的时候,unfinished_tasks都会加上1,那么当我get一个元素的时候,unfinished_tasks是不是也应该要减去1啊,但是我们想多了
# get方法不会自动帮我们做这件事,需要手动调用task_done方法实现
q.task_done()
break
else:
await asyncio.sleep(3)
q.task_done()
async def producer(q: asyncio.Queue, consumer_num):
print(f"生产者 开始")
for i in range(20):
await q.put(i)
print(f"生产者: 生产元素{i},并放在了队列里")
# 为了让消费者停下来,我就把None添加进去吧
# 开启几个消费者,就添加几个None
for i in range(consumer_num):
await q.put(None)
# 等待所有消费者执行完毕
# 只要unfinished_tasks不为0,那么q.join就会卡住,知道消费者全部消费完为止
await q.join()
print("生产者生产的东西全被消费者消费了")
async def main(consumer_num):
q = asyncio.Queue()
consumers = [consumer(q, i) for i in range(consumer_num)]
await asyncio.wait(consumers + [producer(q, consumer_num)])
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(3))
finally:
event_loop.close()
'''
生产者 开始
生产者: 生产元素0,并放在了队列里
生产者: 生产元素1,并放在了队列里
生产者: 生产元素2,并放在了队列里
生产者: 生产元素3,并放在了队列里
生产者: 生产元素4,并放在了队列里
生产者: 生产元素5,并放在了队列里
生产者: 生产元素6,并放在了队列里
生产者: 生产元素7,并放在了队列里
生产者: 生产元素8,并放在了队列里
生产者: 生产元素9,并放在了队列里
生产者: 生产元素10,并放在了队列里
生产者: 生产元素11,并放在了队列里
生产者: 生产元素12,并放在了队列里
生产者: 生产元素13,并放在了队列里
生产者: 生产元素14,并放在了队列里
生产者: 生产元素15,并放在了队列里
生产者: 生产元素16,并放在了队列里
生产者: 生产元素17,并放在了队列里
生产者: 生产元素18,并放在了队列里
生产者: 生产元素19,并放在了队列里
消费者1号 开始
消费者1号: 消费元素0
消费者0号 开始
消费者0号: 消费元素1
消费者2号 开始
消费者2号: 消费元素2
消费者1号: 消费元素3
消费者0号: 消费元素4
消费者2号: 消费元素5
消费者1号: 消费元素6
消费者0号: 消费元素7
消费者2号: 消费元素8
消费者1号: 消费元素9
消费者0号: 消费元素10
消费者2号: 消费元素11
消费者1号: 消费元素12
消费者0号: 消费元素13
消费者2号: 消费元素14
消费者1号: 消费元素15
消费者0号: 消费元素16
消费者2号: 消费元素17
消费者1号: 消费元素18
消费者0号: 消费元素19
消费者2号: 消费元素None
消费者1号: 消费元素None
消费者0号: 消费元素None
生产者生产的东西全被消费者消费了
'''
3.4 twisted中的协程
from twisted.internet import reactor # 事件循环(终止条件,所有的socket都已经移除)
from twisted.internet import defer # defer.Deferred 特殊的socket对象(不发请求,手动移除)
from twisted.web.client import getPage # 用于创建socket对象(下载完成,自动从事件循环中移除)
# 1. 利用getPage创建socket
# 2. 将socket添加到事件循环
# 3. 开始事件循环(内部发送请求,并接受响应;当所有的socket完成后,终止事件循环)
def response(content):
print(content.decode('utf-8'))
@defer.inlineCallbacks
def task():
url = 'http://www.bilibili.com'
d = getPage(url.encode('utf-8')) # 加上装饰器,得到特殊的socket对象。不发请求,只待在事件循环里面,用于让事件循环一直持续,直到我们手动移除
d.addCallback(response)
yield d
task()
reactor.run()
"""
<!DOCTYPE html><html lang="zh-Hans"><head><meta charset="utf-8"><title>哔哩哔哩 (゜-゜)つロ 干杯~-bilibili</title><meta
....
....
"""
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:love_cat
from twisted.internet import reactor,task
def hello(name):
print('hello', name)
task1 = task.LoopingCall(hello, 'satori') # 每隔十秒钟运行一次
task1.start(10)
reactor.callWhenRunning(hello, 'mmp') # 当循环开始时,运行
reactor.callLater(3, hello, 'mmppp') # 循环开始后三秒,运行
reactor.run()
'''
hello satori
hello mmp
hello mmppp
hello satori
hello satori
hello satori
hello satori
hello satori
.....
.....
.....
'''
4.tornado中的异步
因为epoll主要是用来解决网络io的并发问题,所以tornado的异步,也主要体现在网络的io异步上,即异步web请求。
tornado.web.AsyncHTTPClient,tornado提供的异步请求客户端,用来进行异步web请求。
fetch(request, callback=None),用于执行一个wbe请求,并返回一个tornado.httpclient.HttpReponse。request可以是一个url,也可以是一个tornado.httpclient.HttpRequest,如果是一个url,会自动生成一个HttpRequest对象
HttpRequest对象:接收如下参数
url:要访问的网址
method:请求方式
headers:请求头
body:请求体
HttpResponse:接收如下参数
code:状态码
reason:状态码的描述
body:请求体
error:异常
因为epoll主要是用来解决网络io的并发问题,所以tornado的异步,也主要体现在网络的io异步上,即异步web请求。
client = tornado.httpclient.AsyncHTTPClient(),tornado提供的异步请求客户端,用来进行异步web请求。client.fetch(request, callback=None),用于执行一个wbe请求,并返回一个tornado.httpclient.HttpReponse。request可以是一个url,也可以是一个tornado.httpclient.HttpRequest,如果是一个url,会自动生成一个HttpRequest对象
HttpRequest对象:接收如下参数
url:要访问的网址
method:请求方式
headers:请求头
body:请求体
HttpResponse:接收如下参数
code:状态码
reason:状态码的描述
body:请求体
error:异常
@tornado.web.asynchronous,http方法被该装饰器装饰之后,不会主动关闭通信的通道,需要我们手动关闭。而且我用的tornado版本是5.1,pycharm中已经提示要被移除了,也就是通过回调来实现异步
import tornado.web
import tornado.httpclient
import tornado.gen
import json
class SatoriHandler(tornado.web.RequestHandler):
# 被该装饰器装饰之后,http方法不会主动关闭通信的通道,需要我们手动关闭
@tornado.web.asynchronous
def get(self, *args, **kwargs):
# 创建一个客户端
client = tornado.httpclient.AsyncHTTPClient()
# 调用fetch方法,该方法不会返回调用的结果,而是需要指定一个回调函数
# 在http方法结束之后,会调用回调函数
client.fetch("http://www.acfun.cn", callback=self.on_response)
# 用于处理逻辑,在get方法中,client.fetch所获取的内容,会传到on_response的response参数中
# 类似于requests.get获取到的结果
def on_response(self, response):
# 如果引发异常
if response.error:
self.send_error(500)
else:
# 我们关系的html文本则在response的body属性中
data = json.loads(response.body)
# 手动关闭通道
self.finish()
访问localhost:7777/satori
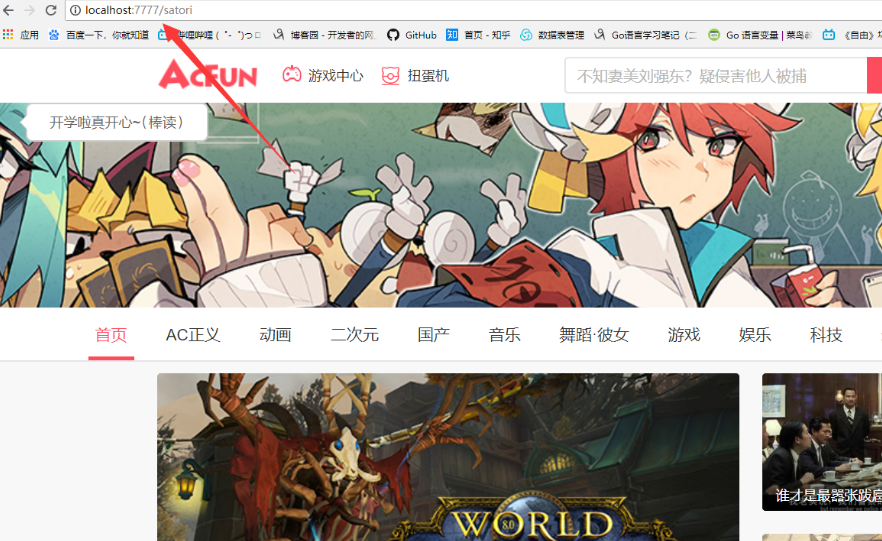
可以看到我们获取到了AcFun网站的页面
可以肯定,现在即使我访问两个请求,也是同时执行。如果我不开VPN访问谷歌,会一直请求链接,而我在连接谷歌的时候,要是再连接AcFun,也会请求成功,因为是异步的。如果是普通的方法,必须等请求谷歌结束之后,才会请求AcFun,所以目前我们异步做的还算可以。但是现在又出现了一个问题,那就是为了处理逻辑,我们不得不把代码分割成两个不同的方法。当我们有两个或更多的异步请求要执行的时候,编码和维护都显得非常困难,每个都依赖于前面的调用:不久你就会发现自己调用了一个回调函数的回调函数的回调函数。下面就是一个构想出来的(但不是不可能的)例子:
def get(self):
client = AsyncHTTPClient()
client.fetch("http://example.com", callback=on_response)
def on_response(self, response):
client = AsyncHTTPClient()
client.fetch("http://another.example.com/", callback=on_response2)
def on_response2(self, response):
client = AsyncHTTPClient()
client.fetch("http://still.another.example.com/", callback=on_response3)
def on_response3(self, response):
...
...
...
但是tornado在2.1版本的时候,引入了tornado.gen模块,也就是异步生成器,可以提供一个更整洁的方式来执行异步请求。
通过协程来实现异步
import tornado.web
import tornado.httpclient
import tornado.gen
class SatoriHandler(tornado.web.RequestHandler):
@tornado.gen.coroutine
def get(self, *args, **kwargs):
# 创建一个客户端
client = tornado.httpclient.AsyncHTTPClient()
# 不指定回调函数,而是通过yield关键字
# 最终获取的数据会存在res当中
res = yield client.fetch("http://www.acfun.cn")
if res.error:
self.send_error(500)
else:
self.write(res.body)
# 这里也无需手动关闭通道,因为会自动关闭
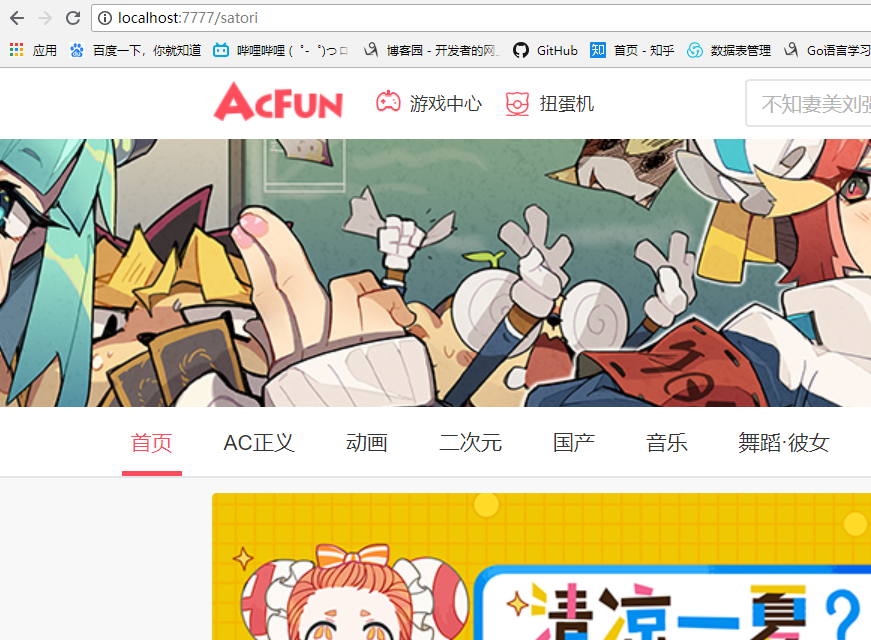
依旧获取成功,而且我先访问google一直在连接中,然后访问AcFun依旧可以访问成功。也可以将异步web请求,单独写出来。
import tornado.web
import tornado.httpclient
import tornado.gen
import json
class SatoriHandler(tornado.web.RequestHandler):
@tornado.gen.coroutine
def get(self, *args, **kwargs):
# 显然这里的res应该getData()的返回值
# 我们要将逻辑都放在getData函数汇总
res = yield self.getData()
self.write(res.body)
@tornado.gen.coroutine
def getData(self):
client = tornado.httpclient.AsyncHTTPClient()
res = yield client.fetch("http://www.acfun.cn")
# 那么我要如何将这里的res传给get函数里面的res呢
# tornado为我们提供了一个异常,通过引发这个异常
# 这个res便会通过yield self.getData()传给get函数里面的res
raise tornado.gen.Return(res)
依旧是可以访问成功的
这里,yield的使用返回程序对Tornado的控制,允许在HTTP请求进行中执行其他任务。当HTTP请求完成时,RequestHandler方法在其停止的地方恢复。这种构建的美在于它在请求处理程序中返回HTTP响应,而不是回调函数中。因此,代码更易理解:所有请求相关的逻辑位于同一个位置。而HTTP请求依然是异步执行的,所以我们使用tornado.gen可以达到和使用回调函数的异步请求版本相同的性能。
异步操作总结
Tornado异步Web发服务不仅容易实现也在实践中有着不容小觑的能力。使用异步处理可以让我们的应用在长时间的API和数据库请求中免受阻塞之苦,最终更快地提供更多请求。尽管不是所有的处理都能从异步中受益--并且实际上尝试整个程序非阻塞会迅速使事情变得复杂--但Tornado的非阻塞功能可以非常方便的创建依赖于缓慢查询或外部服务的Web应用。
不过,值得注意的是,这些例子都非常的做作。如果你正在设计一个任何规模下带有该功能的应用,你可能希望客户端浏览器来执行Twitter搜索请求(使用JavaScript),而让Web服务器转向提供其他请求。在大多数情况下,你至少希望将结果缓存以便两次相同搜索项的请求不会导致再次向远程API执行完整请求。通常,如果你在后端执行HTTP请求提供网站内容,你可能希望重新思考如何建立你的应用。
使用Tornado进行长轮询
Tornado异步架构的另一个优势是它能够轻松处理HTTP长轮询。这是一个处理实时更新的方法,它既可以应用到简单的数字标记通知,也可以实现复杂的多用户聊天室。
部署提供实时更新的Web应用对于Web程序员而言是一项长期的挑战。更新用户状态、发送新消息提醒、或者任何一个需要在初始文档完成加载后由服务器向浏览器发送消息方法的全局活动。一个早期的方法是浏览器以一个固定的时间间隔向服务器轮询新请求。这项技术带来了新的挑战:轮询频率必须足够快以便通知是最新的,但又不能太频繁,当成百上千的客户端持续不断的打开新的连接会使HTTP请求面临严重的扩展性挑战。频繁的轮询使得Web服务器遭受"凌迟"之苦。
所谓的"服务器推送"技术允许Web应用实时发布更新,同时保持合理的资源使用以及确保可预知的扩展。对于一个可行的服务器推送技术而言,它必须在现有的浏览器上表现良好。最流行的技术是让浏览器发起连接来模拟服务器推送更新。这种方式的HTTP连接被称为长轮询或Comet请求。
长轮询意味着浏览器只需启动一个HTTP请求,其连接的服务器会有意保持开启。浏览器只需要等待更新可用时服务器"推送"响应。当服务器发送响应并关闭连接后,(或者浏览器端客户请求超时),客户端只需打开一个新的连接并等待下一个更新。
长轮询的好处
HTTP长轮询的主要吸引力在于其极大地减少了Web服务器的负载。相对于客户端制造大量的短而频繁的请求(以及每次处理HTTP头部产生的开销),服务器端只有当其接收一个初始请求和再次发送响应时处理连接。大部分时间没有新的数据,连接也不会消耗任何处理器资源。
浏览器兼容性是另一个巨大的好处。任何支持AJAX请求的浏览器都可以执行推送请求。不需要任何浏览器插件或其他附加组件。对比其他服务器端推送技术,HTTP长轮询最终成为了被广泛使用的少数几个可行方案之一。
我们已经接触过长轮询的一些使用。实际上,前面提到的状态更新、消息通知以及聊天消息都是目前流行的网站功能。像Google Docs这样的站点使用长轮询同步协作,两个人可以同时编辑文档并看到对方的改变。Twitter使用长轮询指示浏览器在新状态更新可用时展示通知。Facebook使用这项技术在其聊天功能中。长轮询如此流行的一个原因是它改善了应用的用户体验:访客不再需要不断地刷新页面来获取最新的内容
长轮询的缺陷
HTTP长轮询在站点或特定用户状态的高度交互反馈通信中非常有用。但我们也应该知道它的一些缺陷。
当使用长轮询开发应用时,记住对于浏览器请求超时间隔无法控制是非常重要的。由浏览器决定在任何中断情况下重新开启HTTP连接。另一个潜在的问题是许多浏览器限制了对于打开的特定主机的并发请求数量。当有一个连接保持空闲时,剩下的用来下载网站内容的请求数量就会有限制。
此外,你还应该明白请求是怎样影响服务器性能的。比如考虑购物车应用。由于在库存变化时所有的推送请求同时应答和关闭,使得在浏览器重新建立连接时服务器受到了新请求的猛烈冲击。对于像用户间聊天或消息通知这样的应用而言,只有少数用户的连接会同时关闭,这就不再是一个问题了。
tornado当中的websocket
实时获取消息
1.前端轮询,有数据立即回复,没有数据就回复没数据
2.长轮询,没有数据改变时,不做任何相应
3.websocket
概述
websocket是html5规范中提出的新的客户端-服务端通信协议,该协议本身使用新的ws://url
websocket是独立的,创建tcp协议之上的协议。和http唯一的关系就是使用http的101状态码,可以进行协议切换。使用tcp的默认端口为80,可以绕过大多数防火墙
websocket使客户端和服务端之间的数据交互变得简单,允许服务端直接向客户端推送数据,而不需要客户端的请求。两者可以建立持久连接,并且可以双向通信。
tornado的websocket
1.WebSocketHandler,处理通信
2.open(),当一个WebSocket链接被建立后调用
3.on_message(message),当客户端发送过来消息时被调用
4.on_close,当客户端关闭链接时调用
5.write_message(message, binary=False),主动向客户端发送消息,message可以是字符串或者字典(自动转为json),如果binary=False,会以utf-8发送。如果为True,以二进制方式发送,字节码。
6.close(),服务端主动关闭WebSocket链接
7.check_orign(orign),判断orign,对符合条件的请求源允许连接
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="contents" style="width:500px;height:500px;overflow: auto"></div>
<div>
<input type="text" id="message"/>
<button onclick="sendMessage()">发送</button>
</div>
</body>
</html>
import tornado.web
from views import view
import config
import os
class Application(tornado.web.Application):
def __init__(self):
handlers = [
(r"/satori", view.SatoriHandler),
(r"/chat", view.ChatHandler),
]
super(Application, self).__init__(handlers=handlers, **config.settings)
import tornado.web
import tornado.httpclient
import tornado.gen
import tornado.websocket
import json
class SatoriHandler(tornado.websocket.WebSocketHandler):
user = []
def open(self):
# 这里的self便是连接对象
self.user.append(self)
for user in self.user:
user.write_message(f"{self.request.remote_ip}上线了\n")
def on_message(self, message):
for user in self.user:
user.write_message(f"{self.request.remote_ip}说:{message}\n")
def on_close(self):
self.user.remove(self)
for user in self.user:
user.write_message(f"{self.request.remote_ip}下线了\n")
def check_origin(self, origin):
return True
class ChatHandler(tornado.web.RequestHandler):
def get(self):
self.render("home.html")
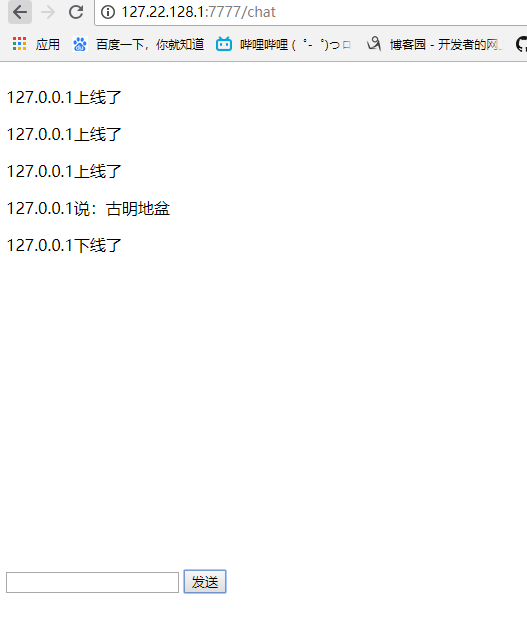
首先访问chat,渲染出页面,然后创建websocket访问satori,当创建websocket,那么handler里面的open就能接收到,当ws.send(),那么handler里面的on_message()就能接收到。
当服务端handler进行write_message的时候,客户端ws.onmessage()可以接收到,定义一个函数,参数为e,那么e.data就是接收到的内容。当客户端下线,那么handler里面的on_close就可以接收到。